 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Optimization and Learning of Fair Court Schedules
Oct 22, 2024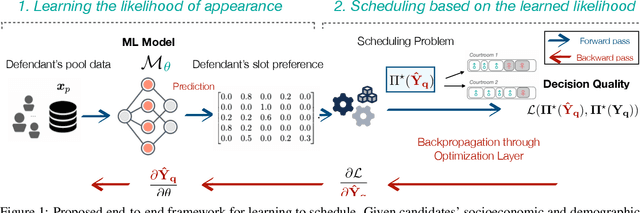

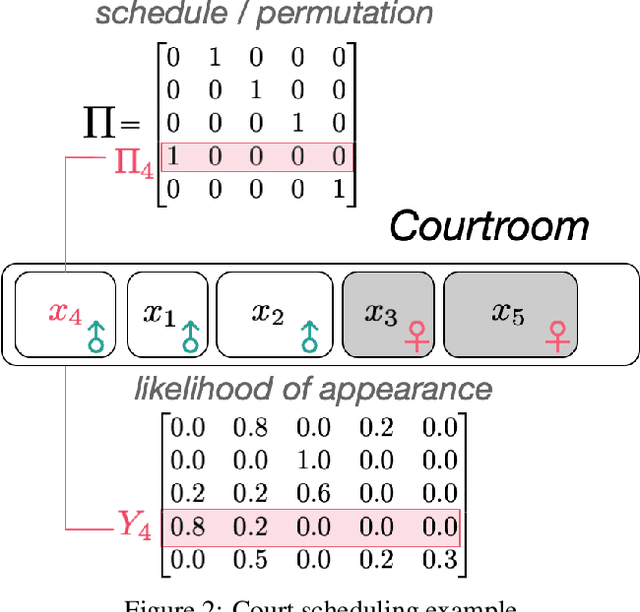
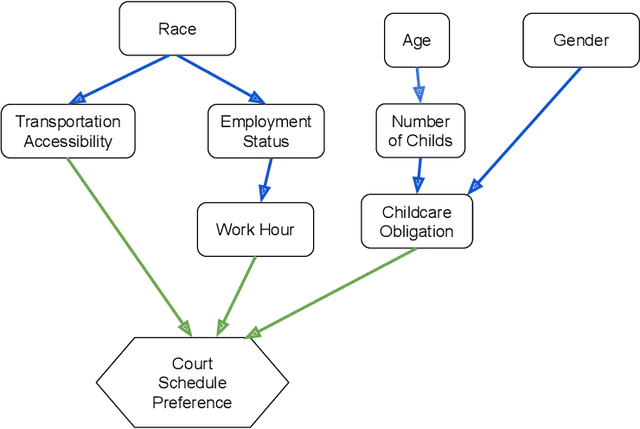
Criminal courts across the United States handle millions of cases every year, and the scheduling of those cases must accommodate a diverse set of constraints, including the preferences and availability of courts, prosecutors, and defense teams. When criminal court schedules are formed, defendants' scheduling preferences often take the least priority, although defendants may face significant consequences (including arrest or detention) for missed court dates. Additionally, studies indicate that defendants' nonappearances impose costs on the courts and other system stakeholders. To address these issues, courts and commentators have begun to recognize that pretrial outcomes for defendants and for the system would be improved with greater attention to court processes, including \emph{court scheduling practices}. There is thus a need for fair criminal court pretrial scheduling systems that account for defendants' preferences and availability, but the collection of such data poses logistical challenges. Furthermore, optimizing schedules fairly across various parties' preferences is a complex optimization problem, even when such data is available. In an effort to construct such a fair scheduling system under data uncertainty, this paper proposes a joint optimization and learning framework that combines machine learning models trained end-to-end with efficient matching algorithms. This framework aims to produce court scheduling schedules that optimize a principled measure of fairness, balancing the availability and preferences of all parties.
End-to-End Learning for Fair Multiobjective Optimization Under Uncertainty
Feb 12, 2024



Many decision processes in artificial intelligence and operations research are modeled by parametric optimization problems whose defining parameters are unknown and must be inferred from observable data. The Predict-Then-Optimize (PtO) paradigm in machine learning aims to maximize downstream decision quality by training the parametric inference model end-to-end with the subsequent constrained optimization. This requires backpropagation through the optimization problem using approximation techniques specific to the problem's form, especially for nondifferentiable linear and mixed-integer programs. This paper extends the PtO methodology to optimization problems with nondifferentiable Ordered Weighted Averaging (OWA) objectives, known for their ability to ensure properties of fairness and robustness in decision models. Through a collection of training techniques and proposed application settings, it shows how optimization of OWA functions can be effectively integrated with parametric prediction for fair and robust optimization under uncertainty.
Analyzing and Enhancing the Backward-Pass Convergence of Unrolled Optimization
Dec 28, 2023The integration of constrained optimization models as components in deep networks has led to promising advances on many specialized learning tasks. A central challenge in this setting is backpropagation through the solution of an optimization problem, which often lacks a closed form. One typical strategy is algorithm unrolling, which relies on automatic differentiation through the entire chain of operations executed by an iterative optimization solver. This paper provides theoretical insights into the backward pass of unrolled optimization, showing that it is asymptotically equivalent to the solution of a linear system by a particular iterative method. Several practical pitfalls of unrolling are demonstrated in light of these insights, and a system called Folded Optimization is proposed to construct more efficient backpropagation rules from unrolled solver implementations. Experiments over various end-to-end optimization and learning tasks demonstrate the advantages of this system both computationally, and in terms of flexibility over various optimization problem forms.