 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Optimization and Learning of Fair Court Schedules
Paper and Code
Oct 22, 2024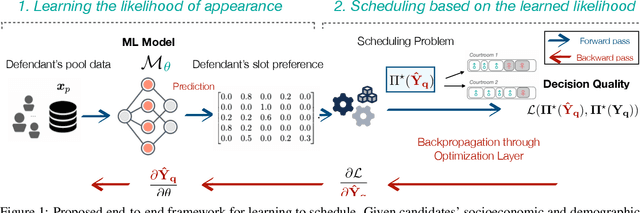

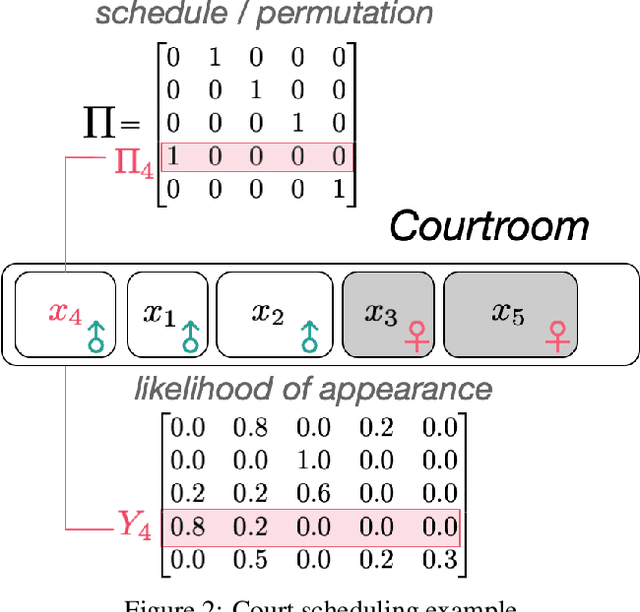
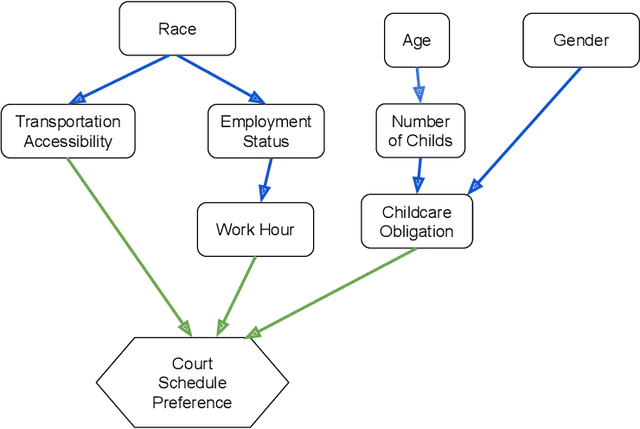
Criminal courts across the United States handle millions of cases every year, and the scheduling of those cases must accommodate a diverse set of constraints, including the preferences and availability of courts, prosecutors, and defense teams. When criminal court schedules are formed, defendants' scheduling preferences often take the least priority, although defendants may face significant consequences (including arrest or detention) for missed court dates. Additionally, studies indicate that defendants' nonappearances impose costs on the courts and other system stakeholders. To address these issues, courts and commentators have begun to recognize that pretrial outcomes for defendants and for the system would be improved with greater attention to court processes, including \emph{court scheduling practices}. There is thus a need for fair criminal court pretrial scheduling systems that account for defendants' preferences and availability, but the collection of such data poses logistical challenges. Furthermore, optimizing schedules fairly across various parties' preferences is a complex optimization problem, even when such data is available. In an effort to construct such a fair scheduling system under data uncertainty, this paper proposes a joint optimization and learning framework that combines machine learning models trained end-to-end with efficient matching algorithms. This framework aims to produce court scheduling schedules that optimize a principled measure of fairness, balancing the availability and preferences of all parties.