 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning To Solve Differential Equation Constrained Optimization Problems
Oct 02, 2024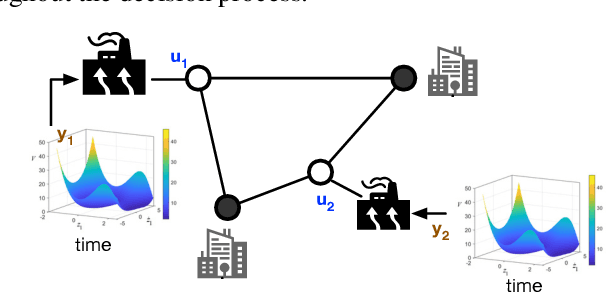
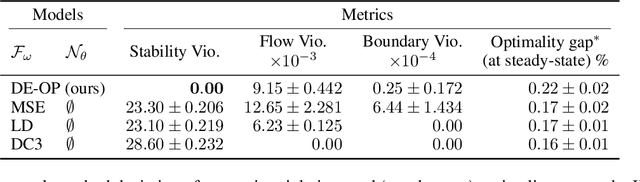
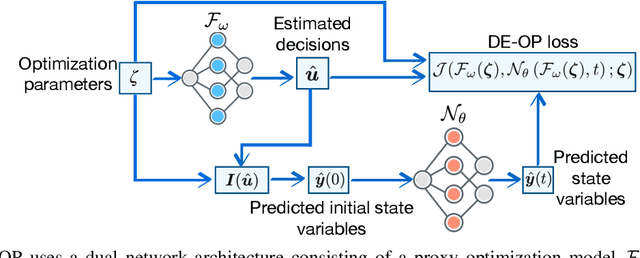

Differential equations (DE) constrained optimization plays a critical role in numerous scientific and engineering fields, including energy systems, aerospace engineering, ecology, and finance, where optimal configurations or control strategies must be determined for systems governed by ordinary or stochastic differential equations. Despite its significance, the computational challenges associated with these problems have limited their practical use. To address these limitations, this paper introduces a learning-based approach to DE-constrained optimization that combines techniques from proxy optimization and neural differential equations. The proposed approach uses a dual-network architecture, with one approximating the control strategies, focusing on steady-state constraints, and another solving the associated DEs. This combination enables the approximation of optimal strategies while accounting for dynamic constraints in near real-time. Experiments across problems in energy optimization and finance modeling show that this method provides full compliance with dynamic constraints and it produces results up to 25 times more precise than other methods which do not explicitly model the system's dynamic equations.
Learning Joint Models of Prediction and Optimization
Sep 07, 2024



The Predict-Then-Optimize framework uses machine learning models to predict unknown parameters of an optimization problem from exogenous features before solving. This setting is common to many real-world decision processes, and recently it has been shown that decision quality can be substantially improved by solving and differentiating the optimization problem within an end-to-end training loop. However, this approach requires significant computational effort in addition to handcrafted, problem-specific rules for backpropagation through the optimization step, challenging its applicability to a broad class of optimization problems. This paper proposes an alternative method, in which optimal solutions are learned directly from the observable features by joint predictive models. The approach is generic, and based on an adaptation of the Learning-to-Optimize paradigm, from which a rich variety of existing techniques can be employed. Experimental evaluations show the ability of several Learning-to-Optimize methods to provide efficient and accurate solutions to an array of challenging Predict-Then-Optimize problems.
Predict-Then-Optimize by Proxy: Learning Joint Models of Prediction and Optimization
Nov 22, 2023
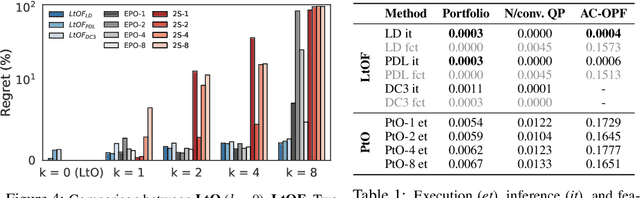
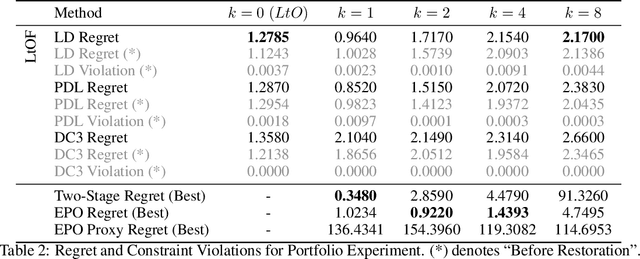
Many real-world decision processes are modeled by optimization problems whose defining parameters are unknown and must be inferred from observable data. The Predict-Then-Optimize framework uses machine learning models to predict unknown parameters of an optimization problem from features before solving. Recent works show that decision quality can be improved in this setting by solving and differentiating the optimization problem in the training loop, enabling end-to-end training with loss functions defined directly on the resulting decisions. However, this approach can be inefficient and requires handcrafted, problem-specific rules for backpropagation through the optimization step. This paper proposes an alternative method, in which optimal solutions are learned directly from the observable features by predictive models. The approach is generic, and based on an adaptation of the Learning-to-Optimize paradigm, from which a rich variety of existing techniques can be employed. Experimental evaluations show the ability of several Learning-to-Optimize methods to provide efficient, accurate, and flexible solutions to an array of challenging Predict-Then-Optimize problems.
End-to-End Optimization and Learning for Multiagent Ensembles
Nov 01, 2022Multiagent ensemble learning is an important class of algorithms aimed at creating accurate and robust machine learning models by combining predictions from individual agents. A key challenge for the design of these models is to create effective rules to combine individual predictions for any particular input sample. This paper addresses this challenge and proposes a unique integration of constrained optimization and learning to derive specialized consensus rules to compose accurate predictions from a pretrained ensemble. The resulting strategy, called end-to-end Multiagent ensemble Learning (e2e-MEL), learns to select appropriate predictors to combine for a particular input sample. The paper shows how to derive the ensemble learning task into a differentiable selection program which is trained end-to-end within the ensemble learning model. Results over standard benchmarks demonstrate the ability of e2e-MEL to substantially outperform conventional consensus rules in a variety of settings.