 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividual Fairness in Pipelines
Apr 12, 2020

It is well understood that a system built from individually fair components may not itself be individually fair. In this work, we investigate individual fairness under pipeline composition. Pipelines differ from ordinary sequential or repeated composition in that individuals may drop out at any stage, and classification in subsequent stages may depend on the remaining "cohort" of individuals. As an example, a company might hire a team for a new project and at a later point promote the highest performer on the team. Unlike other repeated classification settings, where the degree of unfairness degrades gracefully over multiple fair steps, the degree of unfairness in pipelines can be arbitrary, even in a pipeline with just two stages. Guided by a panoply of real-world examples, we provide a rigorous framework for evaluating different types of fairness guarantees for pipelines. We show that na\"{i}ve auditing is unable to uncover systematic unfairness and that, in order to ensure fairness, some form of dependence must exist between the design of algorithms at different stages in the pipeline. Finally, we provide constructions that permit flexibility at later stages, meaning that there is no need to lock in the entire pipeline at the time that the early stage is constructed.
Abstracting Fairness: Oracles, Metrics, and Interpretability
Apr 04, 2020
It is well understood that classification algorithms, for example, for deciding on loan applications, cannot be evaluated for fairness without taking context into account. We examine what can be learned from a fairness oracle equipped with an underlying understanding of ``true'' fairness. The oracle takes as input a (context, classifier) pair satisfying an arbitrary fairness definition, and accepts or rejects the pair according to whether the classifier satisfies the underlying fairness truth. Our principal conceptual result is an extraction procedure that learns the underlying truth; moreover, the procedure can learn an approximation to this truth given access to a weak form of the oracle. Since every ``truly fair'' classifier induces a coarse metric, in which those receiving the same decision are at distance zero from one another and those receiving different decisions are at distance one, this extraction process provides the basis for ensuring a rough form of metric fairness, also known as individual fairness. Our principal technical result is a higher fidelity extractor under a mild technical constraint on the weak oracle's conception of fairness. Our framework permits the scenario in which many classifiers, with differing outcomes, may all be considered fair. Our results have implications for interpretablity -- a highly desired but poorly defined property of classification systems that endeavors to permit a human arbiter to reject classifiers deemed to be ``unfair'' or illegitimately derived.
Individual Fairness in Sponsored Search Auctions
Jun 20, 2019

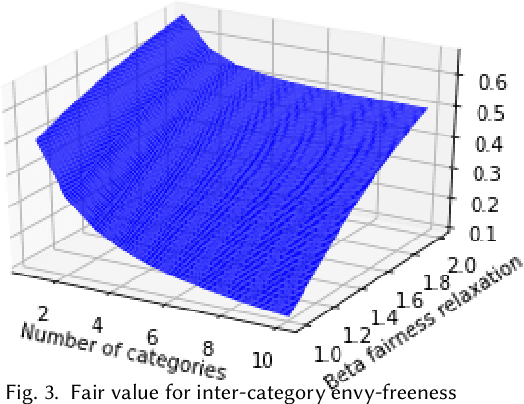
Fairness in advertising is a topic of particular interest in both the computer science and economics literatures, supported by theoretical and empirical observations. We initiate the study of tradeoffs between individual fairness and performance in online advertising, where advertisers place bids on ad slots for each user and the platform must determine which ads to display. Our main focus is to investigate the "cost of fairness": more specifically, whether a fair allocation mechanism can achieve utility close to that of a utility-optimal unfair mechanism. Motivated by practice, we consider both the case of many advertisers in a single category, e.g. sponsored results on a job search website, and ads spanning multiple categories, e.g. personalized display advertising on a social networking site, and show the tradeoffs are inherently different in these settings. We prove lower and upper bounds on the cost of fairness for each of these settings. For the single category setting, we show constraints on the "fairness" of advertisers' bids are necessary to achieve good utility. Moreover, with bid fairness constraints, we construct a mechanism that simultaneously achieves a high utility and a strengthening of typical fairness constraints that we call total variation fairness. For the multiple category setting, we show that fairness relaxations are necessary to achieve good utility. We consider a relaxed definition based on user-specified category preferences that we call user-directed fairness, and we show that with this fairness notion a high utility is achievable. Finally, we show that our mechanisms in the single and multiple category settings compose well, yielding a high utility combined mechanism that satisfies user-directed fairness across categories and conditional total variation fairness within categories.
Metric Learning for Individual Fairness
Jun 01, 2019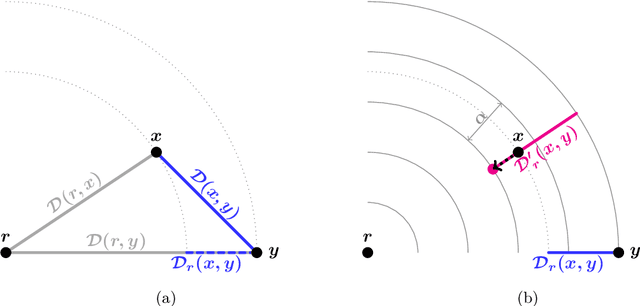


There has been much discussion recently about how fairness should be measured or enforced in classification. Individual Fairness [Dwork, Hardt, Pitassi, Reingold, Zemel, 2012], which requires that similar individuals be treated similarly, is a highly appealing definition as it gives strong guarantees on treatment of individuals. Unfortunately, the need for a task-specific similarity metric has prevented its use in practice. In this work, we propose a solution to the problem of approximating a metric for Individual Fairness based on human judgments. Our model assumes that we have access to a human fairness arbiter, who can answer a limited set of queries concerning similarity of individuals for a particular task, is free of explicit biases and possesses sufficient domain knowledge to evaluate similarity. Our contributions include definitions for metric approximation relevant for Individual Fairness, constructions for approximations from a limited number of realistic queries to the arbiter on a sample of individuals, and learning procedures to construct hypotheses for metric approximations which generalize to unseen samples under certain assumptions of learnability of distance threshold functions.
Fairness Under Composition
Jun 15, 2018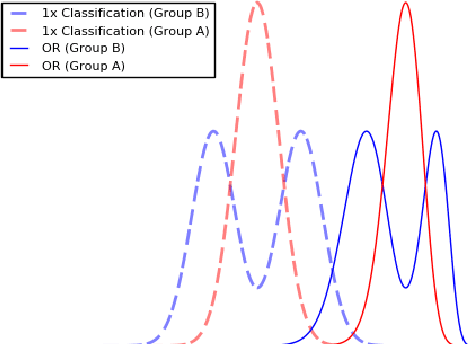
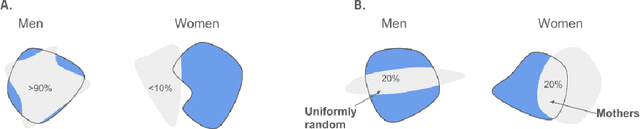
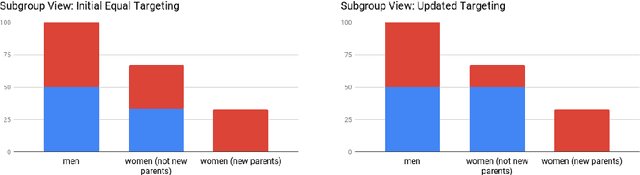
Much of the literature on fair classifiers considers the case of a single classifier used once, in isolation. We initiate the study of composition of fair classifiers. In particular, we address the pitfalls of na{\i}ve composition and give general constructions for fair composition. Focusing on the individual fairness setting proposed in [Dwork, Hardt, Pitassi, Reingold, Zemel, 2011], we also extend our results to a large class of group fairness definitions popular in the recent literature. We exhibit several cases in which group fairness definitions give misleading signals under composition and conclude that additional context is needed to evaluate both group and individual fairness under composition.