 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Making under Miscalibration
Paper and Code
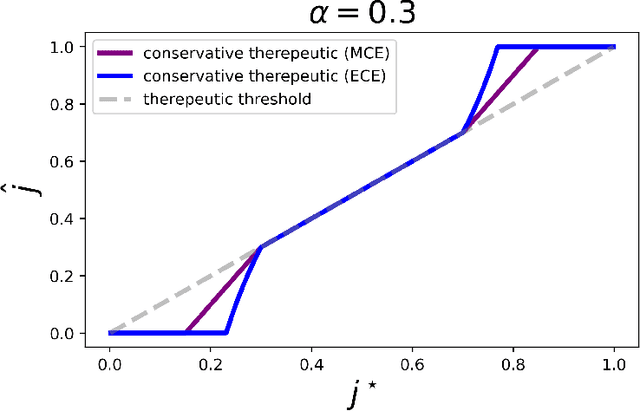
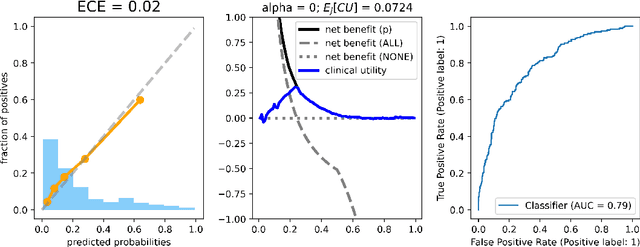
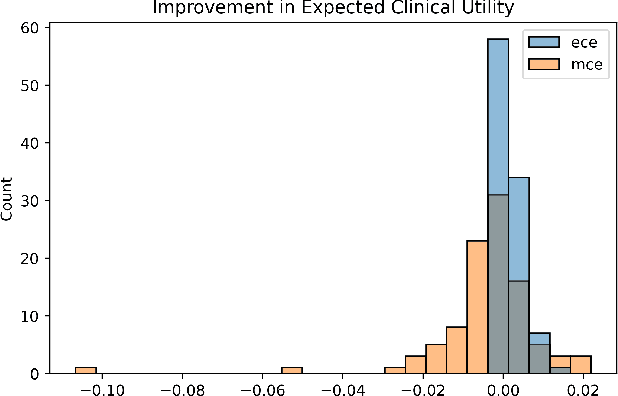
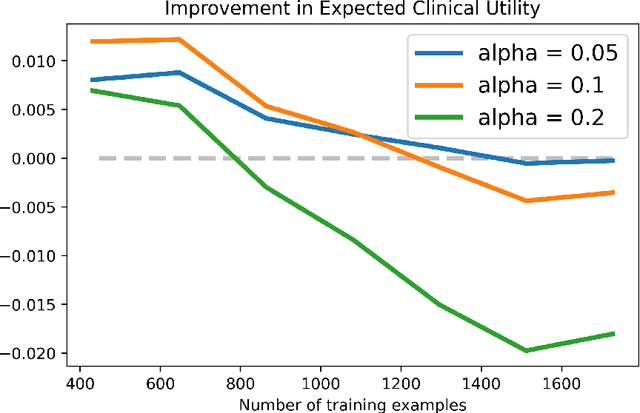
ML-based predictions are used to inform consequential decisions about individuals. How should we use predictions (e.g., risk of heart attack) to inform downstream binary classification decisions (e.g., undergoing a medical procedure)? When the risk estimates are perfectly calibrated, the answer is well understood: a classification problem's cost structure induces an optimal treatment threshold $j^{\star}$. In practice, however, some amount of miscalibration is unavoidable, raising a fundamental question: how should one use potentially miscalibrated predictions to inform binary decisions? We formalize a natural (distribution-free) solution concept: given anticipated miscalibration of $\alpha$, we propose using the threshold $j$ that minimizes the worst-case regret over all $\alpha$-miscalibrated predictors, where the regret is the difference in clinical utility between using the threshold in question and using the optimal threshold in hindsight. We provide closed form expressions for $j$ when miscalibration is measured using both expected and maximum calibration error, which reveal that it indeed differs from $j^{\star}$ (the optimal threshold under perfect calibration). We validate our theoretical findings on real data, demonstrating that there are natural cases in which making decisions using $j$ improves the clinical utility.