 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLower Bounds for Differential Privacy Under Continual Observation and Online Threshold Queries
Feb 28, 2024One of the most basic problems for studying the "price of privacy over time" is the so called private counter problem, introduced by Dwork et al. (2010) and Chan et al. (2010). In this problem, we aim to track the number of events that occur over time, while hiding the existence of every single event. More specifically, in every time step $t\in[T]$ we learn (in an online fashion) that $\Delta_t\geq 0$ new events have occurred, and must respond with an estimate $n_t\approx\sum_{j=1}^t \Delta_j$. The privacy requirement is that all of the outputs together, across all time steps, satisfy event level differential privacy. The main question here is how our error needs to depend on the total number of time steps $T$ and the total number of events $n$. Dwork et al. (2015) showed an upper bound of $O\left(\log(T)+\log^2(n)\right)$, and Henzinger et al. (2023) showed a lower bound of $\Omega\left(\min\{\log n, \log T\}\right)$. We show a new lower bound of $\Omega\left(\min\{n,\log T\}\right)$, which is tight w.r.t. the dependence on $T$, and is tight in the sparse case where $\log^2 n=O(\log T)$. Our lower bound has the following implications: $\bullet$ We show that our lower bound extends to the "online thresholds problem", where the goal is to privately answer many "quantile queries" when these queries are presented one-by-one. This resolves an open question of Bun et al. (2017). $\bullet$ Our lower bound implies, for the first time, a separation between the number of mistakes obtainable by a private online learner and a non-private online learner. This partially resolves a COLT'22 open question published by Sanyal and Ramponi. $\bullet$ Our lower bound also yields the first separation between the standard model of private online learning and a recently proposed relaxed variant of it, called private online prediction.
Õptimal Differentially Private Learning of Thresholds and Quasi-Concave Optimization
Nov 11, 2022The problem of learning threshold functions is a fundamental one in machine learning. Classical learning theory implies sample complexity of $O(\xi^{-1} \log(1/\beta))$ (for generalization error $\xi$ with confidence $1-\beta$). The private version of the problem, however, is more challenging and in particular, the sample complexity must depend on the size $|X|$ of the domain. Progress on quantifying this dependence, via lower and upper bounds, was made in a line of works over the past decade. In this paper, we finally close the gap for approximate-DP and provide a nearly tight upper bound of $\tilde{O}(\log^* |X|)$, which matches a lower bound by Alon et al (that applies even with improper learning) and improves over a prior upper bound of $\tilde{O}((\log^* |X|)^{1.5})$ by Kaplan et al. We also provide matching upper and lower bounds of $\tilde{\Theta}(2^{\log^*|X|})$ for the additive error of private quasi-concave optimization (a related and more general problem). Our improvement is achieved via the novel Reorder-Slice-Compute paradigm for private data analysis which we believe will have further applications.
Tricking the Hashing Trick: A Tight Lower Bound on the Robustness of CountSketch to Adaptive Inputs
Jul 03, 2022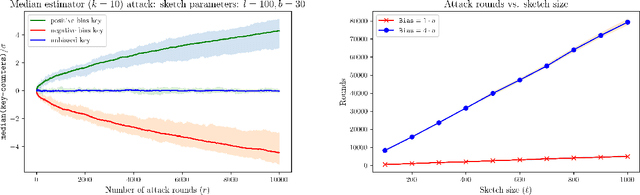
CountSketch and Feature Hashing (the "hashing trick") are popular randomized dimensionality reduction methods that support recovery of $\ell_2$-heavy hitters (keys $i$ where $v_i^2 > \epsilon \|\boldsymbol{v}\|_2^2$) and approximate inner products. When the inputs are {\em not adaptive} (do not depend on prior outputs), classic estimators applied to a sketch of size $O(\ell/\epsilon)$ are accurate for a number of queries that is exponential in $\ell$. When inputs are adaptive, however, an adversarial input can be constructed after $O(\ell)$ queries with the classic estimator and the best known robust estimator only supports $\tilde{O}(\ell^2)$ queries. In this work we show that this quadratic dependence is in a sense inherent: We design an attack that after $O(\ell^2)$ queries produces an adversarial input vector whose sketch is highly biased. Our attack uses "natural" non-adaptive inputs (only the final adversarial input is chosen adaptively) and universally applies with any correct estimator, including one that is unknown to the attacker. In that, we expose inherent vulnerability of this fundamental method.
On the Robustness of CountSketch to Adaptive Inputs
Feb 28, 2022CountSketch is a popular dimensionality reduction technique that maps vectors to a lower dimension using randomized linear measurements. The sketch supports recovering $\ell_2$-heavy hitters of a vector (entries with $v[i]^2 \geq \frac{1}{k}\|\boldsymbol{v}\|^2_2$). We study the robustness of the sketch in adaptive settings where input vectors may depend on the output from prior inputs. Adaptive settings arise in processes with feedback or with adversarial attacks. We show that the classic estimator is not robust, and can be attacked with a number of queries of the order of the sketch size. We propose a robust estimator (for a slightly modified sketch) that allows for quadratic number of queries in the sketch size, which is an improvement factor of $\sqrt{k}$ (for $k$ heavy hitters) over prior work.