 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCV-Arena: An Open Benchmark for Instructional Computer Vision Problem Solving with Human-AI Collaborative Preferences
May 30, 2026Instruction-guided image editing is becoming a general interface for visual work, yet existing benchmarks still focus largely on narrow appearance edits and do not fully capture the diversity of real-image tasks in professional workflows. Here, we define instructional computer vision problem solving as a broader formulation of image editing: given a real input image and a natural-language instruction, a system must produce an edited output that realizes the requested transformation while satisfying explicit preservation, geometric, physical, and usability constraints. We introduce CV-Arena, an open benchmark designed to evaluate this capability at professional scales. CV-Arena contains 12K high-resolution real-image instruction pairs spanning 16 instruction-based visual task types, constructed using CogRetriever, a dual-track retrieval-and-curation pipeline that combines targeted web search, agentic query refinement, verification, and traceability. To evaluate models at scale while preserving human fidelity, we propose Active Elo, a human-AI collaborative preference protocol that leverages CV-Judge, a logic-gated, multi-dimensional VLM evaluator, to reject clear failures and resolve high-confidence comparisons; and to route close, high-quality comparisons to expert raters. Mixed human and AI supervision is then aggregated through reliability-weighted Elo updates. Our comprehensive evaluation of 21 systems, including proprietary, open-source, and agentic models, on CV-Arena reveals persistent gaps in instruction adherence, physical reasoning, structural control, and fine-grained detail preservation. We further develop CV-Agent, a lightweight agentic model that combines planning, editing, and verification, and demonstrate that closed-loop reasoning is a promising direction for professional-grade instruction-following visual editing.
LAVQA: A Latency-Aware Visual Question Answering Framework for Shared Autonomy in Self-Driving Vehicles
Nov 14, 2025When uncertainty is high, self-driving vehicles may halt for safety and benefit from the access to remote human operators who can provide high-level guidance. This paradigm, known as {shared autonomy}, enables autonomous vehicle and remote human operators to jointly formulate appropriate responses. To address critical decision timing with variable latency due to wireless network delays and human response time, we present LAVQA, a latency-aware shared autonomy framework that integrates Visual Question Answering (VQA) and spatiotemporal risk visualization. LAVQA augments visual queries with Latency-Induced COllision Map (LICOM), a dynamically evolving map that represents both temporal latency and spatial uncertainty. It enables remote operator to observe as the vehicle safety regions vary over time in the presence of dynamic obstacles and delayed responses. Closed-loop simulations in CARLA, the de-facto standard for autonomous vehicle simulator, suggest that that LAVQA can reduce collision rates by over 8x compared to latency-agnostic baselines.
Two-stream network-driven vision-based tactile sensor for object feature extraction and fusion perception
Oct 14, 2025



Tactile perception is crucial for embodied intelligent robots to recognize objects. Vision-based tactile sensors extract object physical attributes multidimensionally using high spatial resolution; however, this process generates abundant redundant information. Furthermore, single-dimensional extraction, lacking effective fusion, fails to fully characterize object attributes. These challenges hinder the improvement of recognition accuracy. To address this issue, this study introduces a two-stream network feature extraction and fusion perception strategy for vision-based tactile systems. This strategy employs a distributed approach to extract internal and external object features. It obtains depth map information through three-dimensional reconstruction while simultaneously acquiring hardness information by measuring contact force data. After extracting features with a convolutional neural network (CNN), weighted fusion is applied to create a more informative and effective feature representation. In standard tests on objects of varying shapes and hardness, the force prediction error is 0.06 N (within a 12 N range). Hardness recognition accuracy reaches 98.0%, and shape recognition accuracy reaches 93.75%. With fusion algorithms, object recognition accuracy in actual grasping scenarios exceeds 98.5%. Focused on object physical attributes perception, this method enhances the artificial tactile system ability to transition from perception to cognition, enabling its use in embodied perception applications.
Multi-Head Attention Driven Dynamic Visual-Semantic Embedding for Enhanced Image-Text Matching
Dec 26, 2024



With the rapid development of multimodal learning, the image-text matching task, as a bridge connecting vision and language, has become increasingly important. Based on existing research, this study proposes an innovative visual semantic embedding model, Multi-Headed Consensus-Aware Visual-Semantic Embedding (MH-CVSE). This model introduces a multi-head self-attention mechanism based on the consensus-aware visual semantic embedding model (CVSE) to capture information in multiple subspaces in parallel, significantly enhancing the model's ability to understand and represent the complex relationship between images and texts. In addition, we adopt a parameterized feature fusion strategy to flexibly integrate feature information at different levels, further improving the model's expressive power. In terms of loss function design, the MH-CVSE model adopts a dynamic weight adjustment strategy to dynamically adjust the weight according to the loss value itself, so that the model can better balance the contribution of different loss terms during training. At the same time, we introduce a cosine annealing learning rate strategy to help the model converge more stably in the later stages of training. Extensive experimental verification on the Flickr30k dataset shows that the MH-CVSE model achieves better performance than previous methods in both bidirectional image and text retrieval tasks, fully demonstrating its effectiveness and superiority.
Fair Submodular Cover
Jul 05, 2024

Submodular optimization is a fundamental problem with many applications in machine learning, often involving decision-making over datasets with sensitive attributes such as gender or age. In such settings, it is often desirable to produce a diverse solution set that is fairly distributed with respect to these attributes. Motivated by this, we initiate the study of Fair Submodular Cover (FSC), where given a ground set $U$, a monotone submodular function $f:2^U\to\mathbb{R}_{\ge 0}$, a threshold $\tau$, the goal is to find a balanced subset of $S$ with minimum cardinality such that $f(S)\ge\tau$. We first introduce discrete algorithms for FSC that achieve a bicriteria approximation ratio of $(\frac{1}{\epsilon}, 1-O(\epsilon))$. We then present a continuous algorithm that achieves a $(\ln\frac{1}{\epsilon}, 1-O(\epsilon))$-bicriteria approximation ratio, which matches the best approximation guarantee of submodular cover without a fairness constraint. Finally, we complement our theoretical results with a number of empirical evaluations that demonstrate the effectiveness of our algorithms on instances of maximum coverage.
Linear Submodular Maximization with Bandit Feedback
Jul 02, 2024

Submodular optimization with bandit feedback has recently been studied in a variety of contexts. In a number of real-world applications such as diversified recommender systems and data summarization, the submodular function exhibits additional linear structure. We consider developing approximation algorithms for the maximization of a submodular objective function $f:2^U\to\mathbb{R}_{\geq 0}$, where $f=\sum_{i=1}^dw_iF_{i}$. It is assumed that we have value oracle access to the functions $F_i$, but the coefficients $w_i$ are unknown, and $f$ can only be accessed via noisy queries. We develop algorithms for this setting inspired by adaptive allocation algorithms in the best-arm identification for linear bandit, with approximation guarantees arbitrarily close to the setting where we have value oracle access to $f$. Finally, we empirically demonstrate that our algorithms make vast improvements in terms of sample efficiency compared to algorithms that do not exploit the linear structure of $f$ on instances of move recommendation.
TR-DETR: Task-Reciprocal Transformer for Joint Moment Retrieval and Highlight Detection
Jan 05, 2024



Video moment retrieval (MR) and highlight detection (HD) based on natural language queries are two highly related tasks, which aim to obtain relevant moments within videos and highlight scores of each video clip. Recently, several methods have been devoted to building DETR-based networks to solve both MR and HD jointly. These methods simply add two separate task heads after multi-modal feature extraction and feature interaction, achieving good performance. Nevertheless, these approaches underutilize the reciprocal relationship between two tasks. In this paper, we propose a task-reciprocal transformer based on DETR (TR-DETR) that focuses on exploring the inherent reciprocity between MR and HD. Specifically, a local-global multi-modal alignment module is first built to align features from diverse modalities into a shared latent space. Subsequently, a visual feature refinement is designed to eliminate query-irrelevant information from visual features for modal interaction. Finally, a task cooperation module is constructed to refine the retrieval pipeline and the highlight score prediction process by utilizing the reciprocity between MR and HD. Comprehensive experiments on QVHighlights, Charades-STA and TVSum datasets demonstrate that TR-DETR outperforms existing state-of-the-art methods. Codes are available at \url{https://github.com/mingyao1120/TR-DETR}.
Offline Stochastic Shortest Path: Learning, Evaluation and Towards Optimality
Jun 10, 2022
Goal-oriented Reinforcement Learning, where the agent needs to reach the goal state while simultaneously minimizing the cost, has received significant attention in real-world applications. Its theoretical formulation, stochastic shortest path (SSP), has been intensively researched in the online setting. Nevertheless, it remains understudied when such an online interaction is prohibited and only historical data is provided. In this paper, we consider the offline stochastic shortest path problem when the state space and the action space are finite. We design the simple value iteration-based algorithms for tackling both offline policy evaluation (OPE) and offline policy learning tasks. Notably, our analysis of these simple algorithms yields strong instance-dependent bounds which can imply worst-case bounds that are near-minimax optimal. We hope our study could help illuminate the fundamental statistical limits of the offline SSP problem and motivate further studies beyond the scope of current consideration.
On Top-$k$ Selection from $m$-wise Partial Rankings via Borda Counting
Apr 11, 2022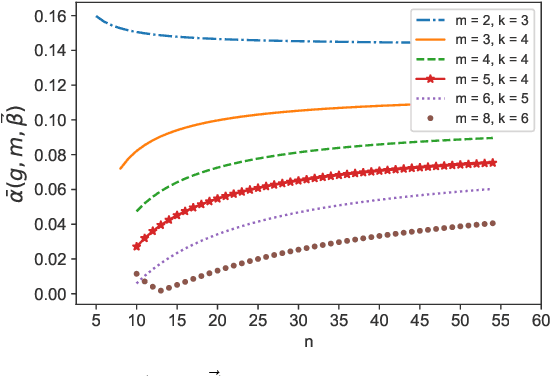
We analyze the performance of the Borda counting algorithm in a non-parametric model. The algorithm needs to utilize probabilistic rankings of the items within $m$-sized subsets to accurately determine which items are the overall top-$k$ items in a total of $n$ items. The Borda counting algorithm simply counts the cumulative scores for each item from these partial ranking observations. This generalizes a previous work of a similar nature by Shah et al. using probabilistic pairwise comparison data. The performance of the Borda counting algorithm critically depends on the associated score separation $\Delta_k$ between the $k$-th item and the $(k+1)$-th item. Specifically, we show that if $\Delta_k$ is greater than certain value, then the top-$k$ items selected by the algorithm is asymptotically accurate almost surely; if $\Delta_k$ is below certain value, then the result will be inaccurate with a constant probability. In the special case of $m=2$, i.e., pairwise comparison, the resultant bound is tighter than that given by Shah et al., leading to a reduced gap between the error probability upper and lower bounds. These results are further extended to the approximate top-$k$ selection setting. Numerical experiments demonstrate the effectiveness and accuracy of the Borda counting algorithm, compared with the spectral MLE-based algorithm, particularly when the data does not necessarily follow an assumed parametric model.