 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounselReflect: A Toolkit for Auditing Mental-Health Dialogues
Mar 31, 2026Mental-health support is increasingly mediated by conversational systems (e.g., LLM-based tools), but users often lack structured ways to audit the quality and potential risks of the support they receive. We introduce CounselReflect, an end-to-end toolkit for auditing mental-health support dialogues. Rather than producing a single opaque quality score, CounselReflect provides structured, multi-dimensional reports with session-level summaries, turn-level scores, and evidence-linked excerpts to support transparent inspection. The system integrates two families of evaluation signals: (i) 12 model-based metrics produced by task-specific predictors, and (ii) rubric-based metrics that extend coverage via a literature-derived library (69 metrics) and user-defined custom metrics, operationalized with configurable LLM judges. CounselReflect is available as a web application, browser extension, and command-line interface (CLI), enabling use in real-time settings as well as at scale. Human evaluation includes a user study with 20 participants and an expert review with 6 mental-health professionals, suggesting that CounselReflect supports understandable, usable, and trustworthy auditing. A demo video and full source code are also provided.
Beyond Idealized Patients: Evaluating LLMs under Challenging Patient Behaviors in Medical Consultations
Mar 31, 2026Large language models (LLMs) are increasingly used for medical consultation and health information support. In this high-stakes setting, safety depends not only on medical knowledge, but also on how models respond when patient inputs are unclear, inconsistent, or misleading. However, most existing medical LLM evaluations assume idealized and well-posed patient questions, which limits their realism. In this paper, we study challenging patient behaviors that commonly arise in real medical consultations and complicate safe clinical reasoning. We define four clinically grounded categories of such behaviors: information contradiction, factual inaccuracy, self-diagnosis, and care resistance. For each behavior, we specify concrete failure criteria that capture unsafe responses. Building on four existing medical dialogue datasets, we introduce CPB-Bench (Challenging Patient Behaviors Benchmark), a bilingual (English and Chinese) benchmark of 692 multi-turn dialogues annotated with these behaviors. We evaluate a range of open- and closed-source LLMs on their responses to challenging patient utterances. While models perform well overall, we identify consistent, behavior-specific failure patterns, with particular difficulty in handling contradictory or medically implausible patient information. We also study four intervention strategies and find that they yield inconsistent improvements and can introduce unnecessary corrections. We release the dataset and code.
MED-COPILOT: A Medical Assistant Powered by GraphRAG and Similar Patient Case Retrieval
Feb 28, 2026Clinical decision-making requires synthesizing heterogeneous evidence, including patient histories, clinical guidelines, and trajectories of comparable cases. While large language models (LLMs) offer strong reasoning capabilities, they remain prone to hallucinations and struggle to integrate long, structured medical documents. We present MED-COPILOT, an interactive clinical decision-support system designed for clinicians and medical trainees, which combines guideline-grounded GraphRAG retrieval with hybrid semantic-keyword similar-patient retrieval to support transparent and evidence-aware clinical reasoning. The system builds a structured knowledge graph from WHO and NICE guidelines, applies community-level summarization for efficient retrieval, and maintains a 36,000-case similar-patient database derived from SOAP-normalized MIMIC-IV notes and Synthea-generated records. We evaluate our framework on clinical note completion and medical question answering, and demonstrate that it consistently outperforms parametric LLM baselines and standard RAG, improving both generation fidelity and clinical reasoning accuracy. The full system is available at https://huggingface.co/spaces/Cryo3978/Med_GraphRAG , enabling users to inspect retrieved evidence, visualize token-level similarity contributions, and conduct guided follow-up analysis. Our results demonstrate a practical and interpretable approach to integrating structured guideline knowledge with patient-level analogical evidence for clinical LLMs.
Fairness or Fluency? An Investigation into Language Bias of Pairwise LLM-as-a-Judge
Jan 20, 2026Recent advances in Large Language Models (LLMs) have incentivized the development of LLM-as-a-judge, an application of LLMs where they are used as judges to decide the quality of a certain piece of text given a certain context. However, previous studies have demonstrated that LLM-as-a-judge can be biased towards different aspects of the judged texts, which often do not align with human preference. One of the identified biases is language bias, which indicates that the decision of LLM-as-a-judge can differ based on the language of the judged texts. In this paper, we study two types of language bias in pairwise LLM-as-a-judge: (1) performance disparity between languages when the judge is prompted to compare options from the same language, and (2) bias towards options written in major languages when the judge is prompted to compare options of two different languages. We find that for same-language judging, there exist significant performance disparities across language families, with European languages consistently outperforming African languages, and this bias is more pronounced in culturally-related subjects. For inter-language judging, we observe that most models favor English answers, and that this preference is influenced more by answer language than question language. Finally, we investigate whether language bias is in fact caused by low-perplexity bias, a previously identified bias of LLM-as-a-judge, and we find that while perplexity is slightly correlated with language bias, language bias cannot be fully explained by perplexity only.
CounselBench: A Large-Scale Expert Evaluation and Adversarial Benchmark of Large Language Models in Mental Health Counseling
Jun 10, 2025



Large language models (LLMs) are increasingly proposed for use in mental health support, yet their behavior in realistic counseling scenarios remains largely untested. We introduce CounselBench, a large-scale benchmark developed with 100 mental health professionals to evaluate and stress-test LLMs in single-turn counseling. The first component, CounselBench-EVAL, contains 2,000 expert evaluations of responses from GPT-4, LLaMA 3, Gemini, and online human therapists to real patient questions. Each response is rated along six clinically grounded dimensions, with written rationales and span-level annotations. We find that LLMs often outperform online human therapists in perceived quality, but experts frequently flag their outputs for safety concerns such as unauthorized medical advice. Follow-up experiments show that LLM judges consistently overrate model responses and overlook safety issues identified by human experts. To probe failure modes more directly, we construct CounselBench-Adv, an adversarial dataset of 120 expert-authored counseling questions designed to trigger specific model issues. Evaluation across 2,880 responses from eight LLMs reveals consistent, model-specific failure patterns. Together, CounselBench establishes a clinically grounded framework for benchmarking and improving LLM behavior in high-stakes mental health settings.
Cancer-Myth: Evaluating AI Chatbot on Patient Questions with False Presuppositions
Apr 15, 2025

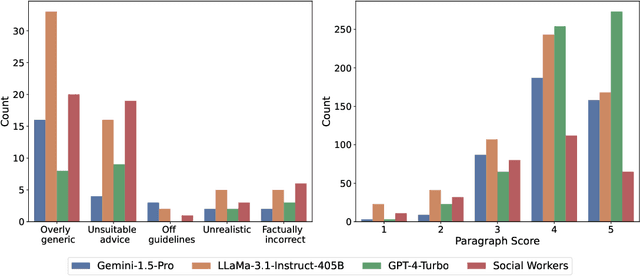
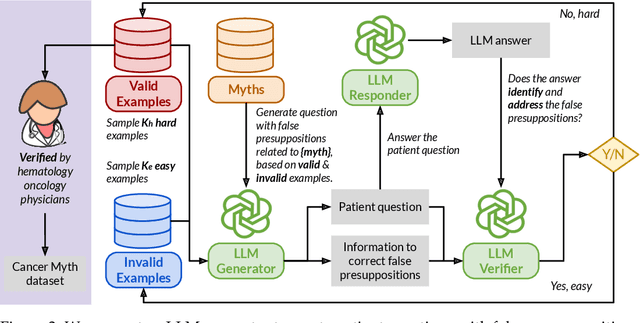
Cancer patients are increasingly turning to large language models (LLMs) as a new form of internet search for medical information, making it critical to assess how well these models handle complex, personalized questions. However, current medical benchmarks focus on medical exams or consumer-searched questions and do not evaluate LLMs on real patient questions with detailed clinical contexts. In this paper, we first evaluate LLMs on cancer-related questions drawn from real patients, reviewed by three hematology oncology physicians. While responses are generally accurate, with GPT-4-Turbo scoring 4.13 out of 5, the models frequently fail to recognize or address false presuppositions in the questions-posing risks to safe medical decision-making. To study this limitation systematically, we introduce Cancer-Myth, an expert-verified adversarial dataset of 585 cancer-related questions with false presuppositions. On this benchmark, no frontier LLM -- including GPT-4o, Gemini-1.Pro, and Claude-3.5-Sonnet -- corrects these false presuppositions more than 30% of the time. Even advanced medical agentic methods do not prevent LLMs from ignoring false presuppositions. These findings expose a critical gap in the clinical reliability of LLMs and underscore the need for more robust safeguards in medical AI systems.
Data-Driven Subgroup Identification for Linear Regression
Apr 29, 2023Medical studies frequently require to extract the relationship between each covariate and the outcome with statistical confidence measures. To do this, simple parametric models are frequently used (e.g. coefficients of linear regression) but usually fitted on the whole dataset. However, it is common that the covariates may not have a uniform effect over the whole population and thus a unified simple model can miss the heterogeneous signal. For example, a linear model may be able to explain a subset of the data but fail on the rest due to the nonlinearity and heterogeneity in the data. In this paper, we propose DDGroup (data-driven group discovery), a data-driven method to effectively identify subgroups in the data with a uniform linear relationship between the features and the label. DDGroup outputs an interpretable region in which the linear model is expected to hold. It is simple to implement and computationally tractable for use. We show theoretically that, given a large enough sample, DDGroup recovers a region where a single linear model with low variance is well-specified (if one exists), and experiments on real-world medical datasets confirm that it can discover regions where a local linear model has improved performance. Our experiments also show that DDGroup can uncover subgroups with qualitatively different relationships which are missed by simply applying parametric approaches to the whole dataset.
Learning transport cost from subset correspondence
Sep 29, 2019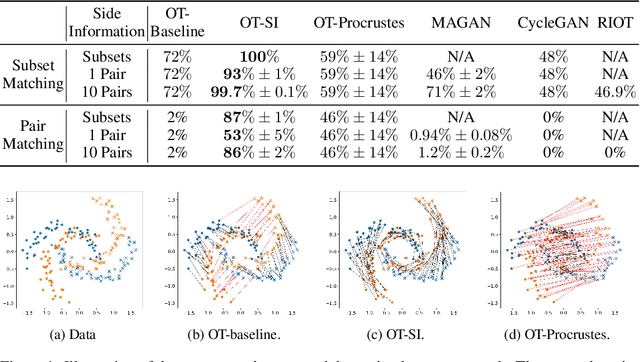



Learning to align multiple datasets is an important problem with many applications, and it is especially useful when we need to integrate multiple experiments or correct for confounding. Optimal transport (OT) is a principled approach to align datasets, but a key challenge in applying OT is that we need to specify a transport cost function that accurately captures how the two datasets are related. Reliable cost functions are typically not available and practitioners often resort to using hand-crafted or Euclidean cost even if it may not be appropriate. In this work, we investigate how to learn the cost function using a small amount of side information which is often available. The side information we consider captures subset correspondence---i.e. certain subsets of points in the two data sets are known to be related. For example, we may have some images labeled as cars in both datasets; or we may have a common annotated cell type in single-cell data from two batches. We develop an end-to-end optimizer (OT-SI) that differentiates through the Sinkhorn algorithm and effectively learns the suitable cost function from side information. On systematic experiments in images, marriage-matching and single-cell RNA-seq, our method substantially outperform state-of-the-art benchmarks.
Model Compression with Generative Adversarial Networks
Dec 05, 2018



More accurate machine learning models often demand more computation and memory at test time, making them difficult to deploy on CPU- or memory-constrained devices. Model compression (also known as distillation) alleviates this burden by training a less expensive student model to mimic the expensive teacher model while maintaining most of the original accuracy. However, when fresh data is unavailable for the compression task, the teacher's training data is typically reused, leading to suboptimal compression. In this work, we propose to augment the compression dataset with synthetic data from a generative adversarial network (GAN) designed to approximate the training data distribution. Our GAN-assisted model compression (GAN-MC) significantly improves student accuracy for expensive models such as deep neural networks and large random forests on both image and tabular datasets. Building on these results, we propose a comprehensive metric---the Compression Score---to evaluate the quality of synthetic datasets based on their induced model compression performance. The Compression Score captures both data diversity and discriminability, and we illustrate its benefits over the popular Inception Score in the context of image classification.
The Effects of Memory Replay in Reinforcement Learning
Oct 18, 2017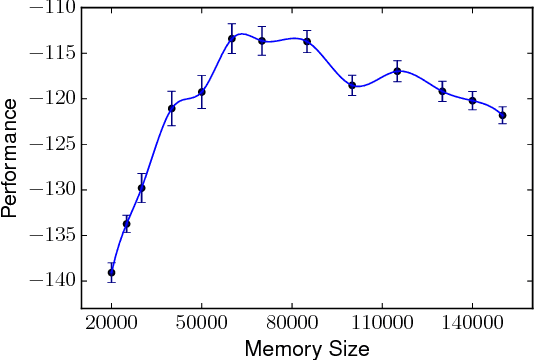
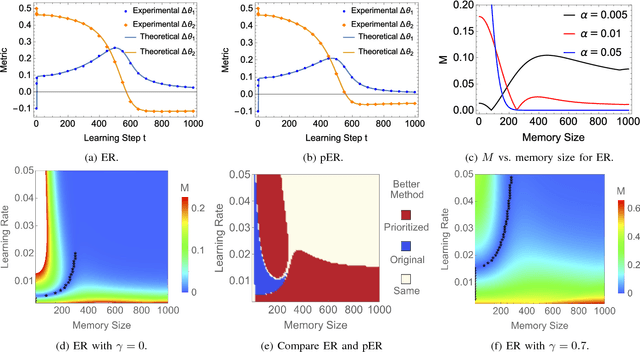

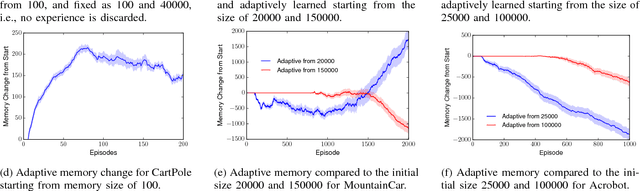
Experience replay is a key technique behind many recent advances in deep reinforcement learning. Allowing the agent to learn from earlier memories can speed up learning and break undesirable temporal correlations. Despite its wide-spread application, very little is understood about the properties of experience replay. How does the amount of memory kept affect learning dynamics? Does it help to prioritize certain experiences? In this paper, we address these questions by formulating a dynamical systems ODE model of Q-learning with experience replay. We derive analytic solutions of the ODE for a simple setting. We show that even in this very simple setting, the amount of memory kept can substantially affect the agent's performance. Too much or too little memory both slow down learning. Moreover, we characterize regimes where prioritized replay harms the agent's learning. We show that our analytic solutions have excellent agreement with experiments. Finally, we propose a simple algorithm for adaptively changing the memory buffer size which achieves consistently good empirical performance.