 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowDCN: Exploring DCN-like Architectures for Fast Image Generation with Arbitrary Resolution
Paper and Code
Oct 30, 2024


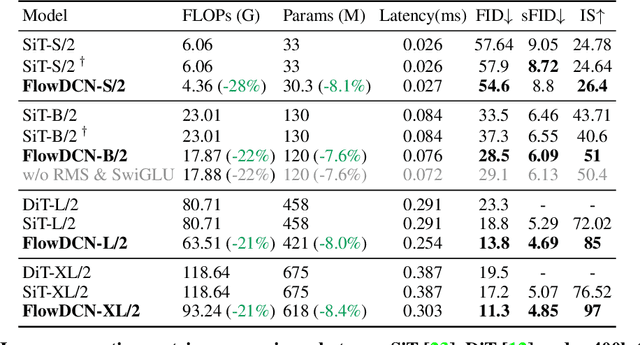
Arbitrary-resolution image generation still remains a challenging task in AIGC, as it requires handling varying resolutions and aspect ratios while maintaining high visual quality. Existing transformer-based diffusion methods suffer from quadratic computation cost and limited resolution extrapolation capabilities, making them less effective for this task. In this paper, we propose FlowDCN, a purely convolution-based generative model with linear time and memory complexity, that can efficiently generate high-quality images at arbitrary resolutions. Equipped with a new design of learnable group-wise deformable convolution block, our FlowDCN yields higher flexibility and capability to handle different resolutions with a single model. FlowDCN achieves the state-of-the-art 4.30 sFID on $256\times256$ ImageNet Benchmark and comparable resolution extrapolation results, surpassing transformer-based counterparts in terms of convergence speed (only $\frac{1}{5}$ images), visual quality, parameters ($8\%$ reduction) and FLOPs ($20\%$ reduction). We believe FlowDCN offers a promising solution to scalable and flexible image synthesis.