 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Towards Pixel-Level VLM Perception via Simple Points Prediction
Jan 27, 2026We present SimpleSeg, a strikingly simple yet highly effective approach to endow Multimodal Large Language Models (MLLMs) with native pixel-level perception. Our method reframes segmentation as a simple sequence generation problem: the model directly predicts sequences of points (textual coordinates) delineating object boundaries, entirely within its language space. To achieve high fidelity, we introduce a two-stage SF$\to$RL training pipeline, where Reinforcement Learning with an IoU-based reward refines the point sequences to accurately match ground-truth contours. We find that the standard MLLM architecture possesses a strong, inherent capacity for low-level perception that can be unlocked without any specialized architecture. On segmentation benchmarks, SimpleSeg achieves performance that is comparable to, and often surpasses, methods relying on complex, task-specific designs. This work lays out that precise spatial understanding can emerge from simple point prediction, challenging the prevailing need for auxiliary components and paving the way for more unified and capable VLMs. Homepage: https://simpleseg.github.io/
Differentiable Solver Search for Fast Diffusion Sampling
May 27, 2025Diffusion models have demonstrated remarkable generation quality but at the cost of numerous function evaluations. Recently, advanced ODE-based solvers have been developed to mitigate the substantial computational demands of reverse-diffusion solving under limited sampling steps. However, these solvers, heavily inspired by Adams-like multistep methods, rely solely on t-related Lagrange interpolation. We show that t-related Lagrange interpolation is suboptimal for diffusion model and reveal a compact search space comprised of time steps and solver coefficients. Building on our analysis, we propose a novel differentiable solver search algorithm to identify more optimal solver. Equipped with the searched solver, rectified-flow models, e.g., SiT-XL/2 and FlowDCN-XL/2, achieve FID scores of 2.40 and 2.35, respectively, on ImageNet256 with only 10 steps. Meanwhile, DDPM model, DiT-XL/2, reaches a FID score of 2.33 with only 10 steps. Notably, our searched solver outperforms traditional solvers by a significant margin. Moreover, our searched solver demonstrates generality across various model architectures, resolutions, and model sizes.
DMM: Building a Versatile Image Generation Model via Distillation-Based Model Merging
Apr 16, 2025The success of text-to-image (T2I) generation models has spurred a proliferation of numerous model checkpoints fine-tuned from the same base model on various specialized datasets. This overwhelming specialized model production introduces new challenges for high parameter redundancy and huge storage cost, thereby necessitating the development of effective methods to consolidate and unify the capabilities of diverse powerful models into a single one. A common practice in model merging adopts static linear interpolation in the parameter space to achieve the goal of style mixing. However, it neglects the features of T2I generation task that numerous distinct models cover sundry styles which may lead to incompatibility and confusion in the merged model. To address this issue, we introduce a style-promptable image generation pipeline which can accurately generate arbitrary-style images under the control of style vectors. Based on this design, we propose the score distillation based model merging paradigm (DMM), compressing multiple models into a single versatile T2I model. Moreover, we rethink and reformulate the model merging task in the context of T2I generation, by presenting new merging goals and evaluation protocols. Our experiments demonstrate that DMM can compactly reorganize the knowledge from multiple teacher models and achieve controllable arbitrary-style generation.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
FlowDCN: Exploring DCN-like Architectures for Fast Image Generation with Arbitrary Resolution
Oct 30, 2024


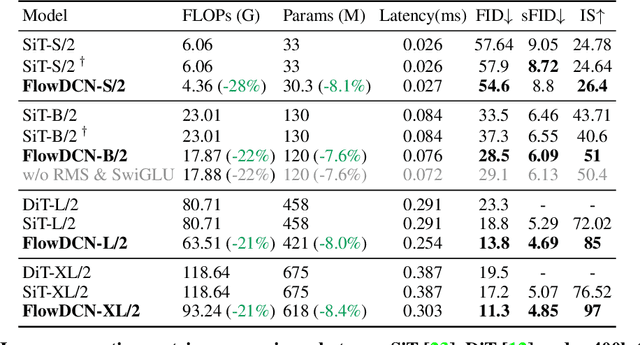
Arbitrary-resolution image generation still remains a challenging task in AIGC, as it requires handling varying resolutions and aspect ratios while maintaining high visual quality. Existing transformer-based diffusion methods suffer from quadratic computation cost and limited resolution extrapolation capabilities, making them less effective for this task. In this paper, we propose FlowDCN, a purely convolution-based generative model with linear time and memory complexity, that can efficiently generate high-quality images at arbitrary resolutions. Equipped with a new design of learnable group-wise deformable convolution block, our FlowDCN yields higher flexibility and capability to handle different resolutions with a single model. FlowDCN achieves the state-of-the-art 4.30 sFID on $256\times256$ ImageNet Benchmark and comparable resolution extrapolation results, surpassing transformer-based counterparts in terms of convergence speed (only $\frac{1}{5}$ images), visual quality, parameters ($8\%$ reduction) and FLOPs ($20\%$ reduction). We believe FlowDCN offers a promising solution to scalable and flexible image synthesis.
Accelerating Image Generation with Sub-path Linear Approximation Model
Apr 23, 2024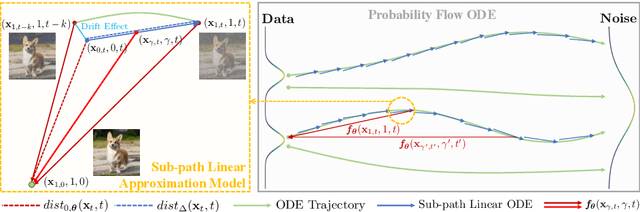
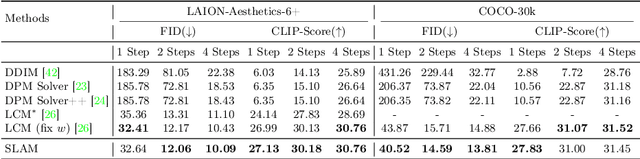
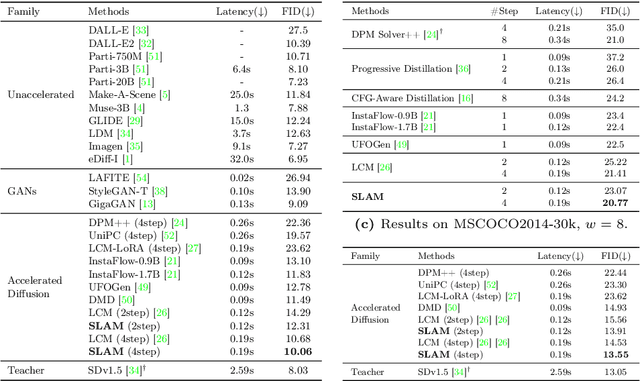
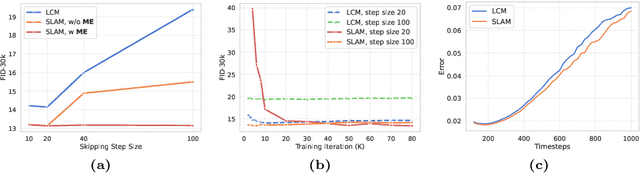
Diffusion models have significantly advanced the state of the art in image, audio, and video generation tasks. However, their applications in practical scenarios are hindered by slow inference speed. Drawing inspiration from the approximation strategies utilized in consistency models, we propose the Sub-path Linear Approximation Model (SLAM), which accelerates diffusion models while maintaining high-quality image generation. SLAM treats the PF-ODE trajectory as a series of PF-ODE sub-paths divided by sampled points, and harnesses sub-path linear (SL) ODEs to form a progressive and continuous error estimation along each individual PF-ODE sub-path. The optimization on such SL-ODEs allows SLAM to construct denoising mappings with smaller cumulative approximated errors. An efficient distillation method is also developed to facilitate the incorporation of more advanced diffusion models, such as latent diffusion models. Our extensive experimental results demonstrate that SLAM achieves an efficient training regimen, requiring only 6 A100 GPU days to produce a high-quality generative model capable of 2 to 4-step generation with high performance. Comprehensive evaluations on LAION, MS COCO 2014, and MS COCO 2017 datasets also illustrate that SLAM surpasses existing acceleration methods in few-step generation tasks, achieving state-of-the-art performance both on FID and the quality of the generated images.
MixFormerV2: Efficient Fully Transformer Tracking
May 25, 2023



Transformer-based trackers have achieved strong accuracy on the standard benchmarks. However, their efficiency remains an obstacle to practical deployment on both GPU and CPU platforms. In this paper, to overcome this issue, we propose a fully transformer tracking framework, coined as \emph{MixFormerV2}, without any dense convolutional operation and complex score prediction module. Our key design is to introduce four special prediction tokens and concatenate them with the tokens from target template and search areas. Then, we apply the unified transformer backbone on these mixed token sequence. These prediction tokens are able to capture the complex correlation between target template and search area via mixed attentions. Based on them, we can easily predict the tracking box and estimate its confidence score through simple MLP heads. To further improve the efficiency of MixFormerV2, we present a new distillation-based model reduction paradigm, including dense-to-sparse distillation and deep-to-shallow distillation. The former one aims to transfer knowledge from the dense-head based MixViT to our fully transformer tracker, while the latter one is used to prune some layers of the backbone. We instantiate two types of MixForemrV2, where the MixFormerV2-B achieves an AUC of 70.6\% on LaSOT and an AUC of 57.4\% on TNL2k with a high GPU speed of 165 FPS, and the MixFormerV2-S surpasses FEAR-L by 2.7\% AUC on LaSOT with a real-time CPU speed.