 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneBooth: Diffusion-based Framework for Subject-preserved Text-to-Image Generation
Jan 07, 2025



Due to the demand for personalizing image generation, subject-driven text-to-image generation method, which creates novel renditions of an input subject based on text prompts, has received growing research interest. Existing methods often learn subject representation and incorporate it into the prompt embedding to guide image generation, but they struggle with preserving subject fidelity. To solve this issue, this paper approaches a novel framework named SceneBooth for subject-preserved text-to-image generation, which consumes inputs of a subject image, object phrases and text prompts. Instead of learning the subject representation and generating a subject, our SceneBooth fixes the given subject image and generates its background image guided by the text prompts. To this end, our SceneBooth introduces two key components, i.e., a multimodal layout generation module and a background painting module. The former determines the position and scale of the subject by generating appropriate scene layouts that align with text captions, object phrases, and subject visual information. The latter integrates two adapters (ControlNet and Gated Self-Attention) into the latent diffusion model to generate a background that harmonizes with the subject guided by scene layouts and text descriptions. In this manner, our SceneBooth ensures accurate preservation of the subject's appearance in the output. Quantitative and qualitative experimental results demonstrate that SceneBooth significantly outperforms baseline methods in terms of subject preservation, image harmonization and overall quality.
LayoutDM: Transformer-based Diffusion Model for Layout Generation
May 04, 2023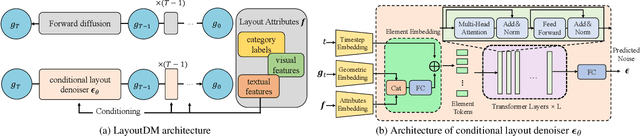
Automatic layout generation that can synthesize high-quality layouts is an important tool for graphic design in many applications. Though existing methods based on generative models such as Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) have progressed, they still leave much room for improving the quality and diversity of the results. Inspired by the recent success of diffusion models in generating high-quality images, this paper explores their potential for conditional layout generation and proposes Transformer-based Layout Diffusion Model (LayoutDM) by instantiating the conditional denoising diffusion probabilistic model (DDPM) with a purely transformer-based architecture. Instead of using convolutional neural networks, a transformer-based conditional Layout Denoiser is proposed to learn the reverse diffusion process to generate samples from noised layout data. Benefitting from both transformer and DDPM, our LayoutDM is of desired properties such as high-quality generation, strong sample diversity, faithful distribution coverage, and stationary training in comparison to GANs and VAEs. Quantitative and qualitative experimental results show that our method outperforms state-of-the-art generative models in terms of quality and diversity.