 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Chain Transformation: Expanding Optimization Dynamics for Fine-Tuning Large Language Models
Oct 29, 2024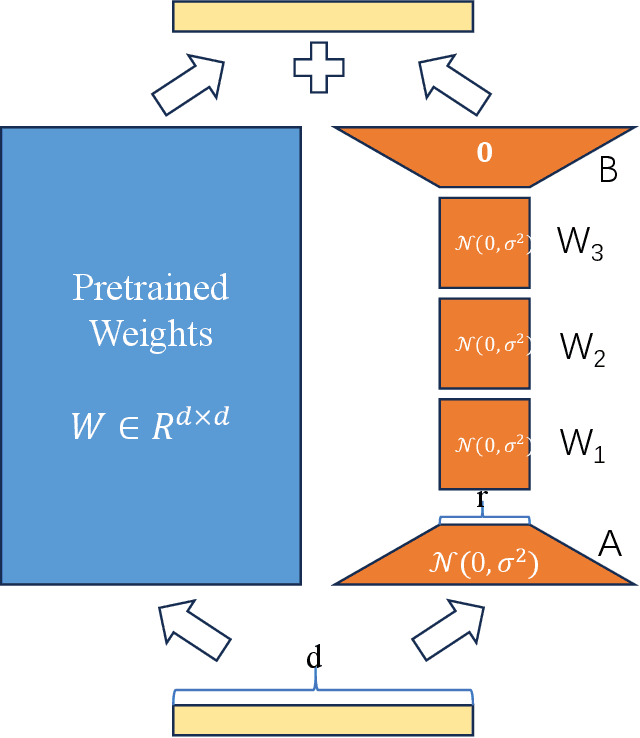
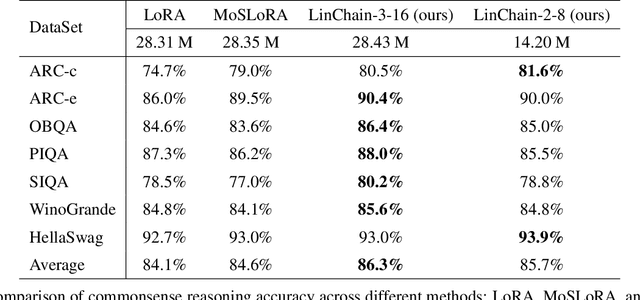
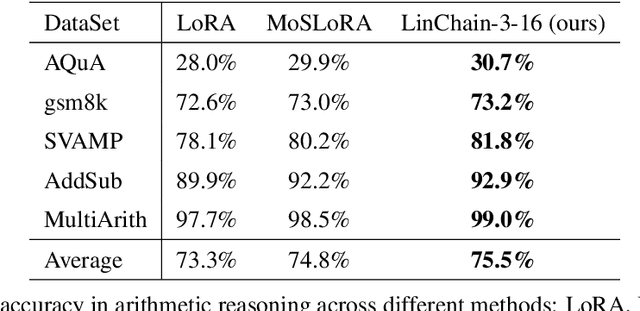
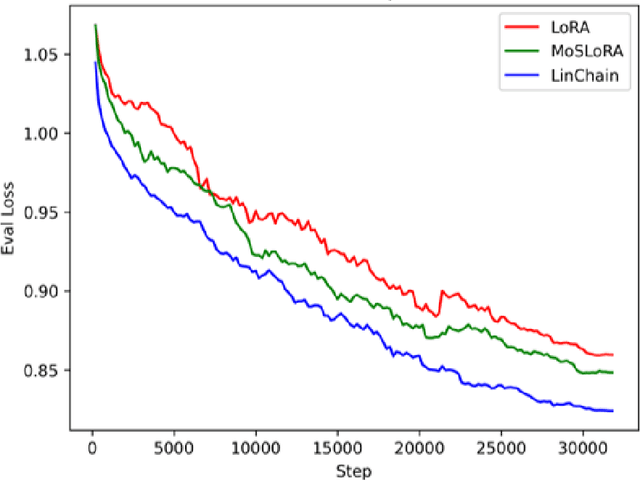
Fine-tuning large language models (LLMs) has become essential for adapting pretrained models to specific downstream tasks. In this paper, we propose Linear Chain Transformation (LinChain), a novel approach that introduces a sequence of linear transformations during fine-tuning to enrich optimization dynamics. By incorporating multiple linear transformations into the parameter update process, LinChain expands the effective rank of updates and enhances the model's ability to learn complex task-specific representations. We demonstrate that this method significantly improves the performance of LLM fine-tuning over state-of-the-art methods by providing more flexible optimization paths during training, while maintaining the inference efficiency of the resulting model. Our experiments on various benchmark tasks show that LinChain leads to better generalization, fewer learnable parameters, and improved task adaptation, making it a compelling strategy for LLM fine-tuning.