 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Agent DRL-Based Framework for Optimal Resource Allocation and Twin Migration in the Multi-Tier Vehicular Metaverse
Feb 26, 2025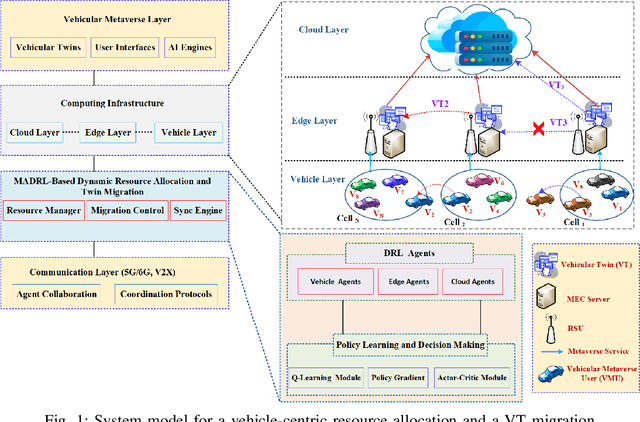
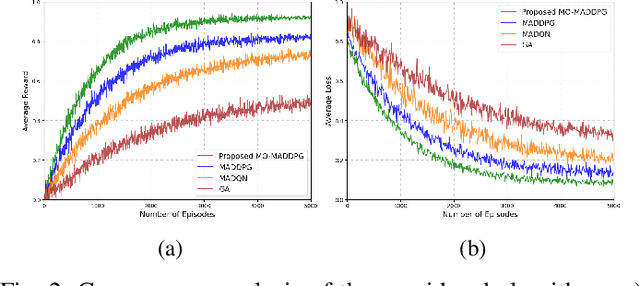
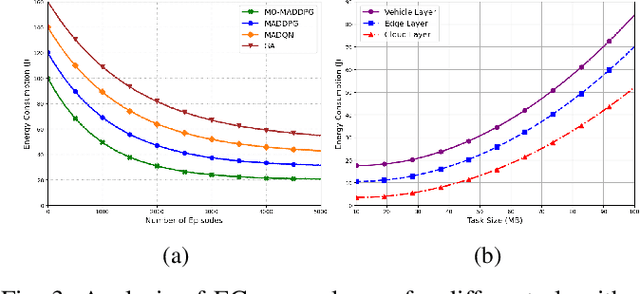
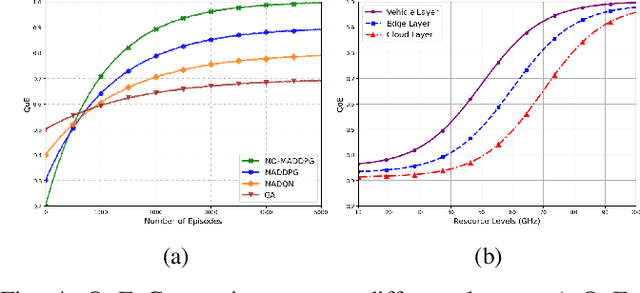
Although multi-tier vehicular Metaverse promises to transform vehicles into essential nodes -- within an interconnected digital ecosystem -- using efficient resource allocation and seamless vehicular twin (VT) migration, this can hardly be achieved by the existing techniques operating in a highly dynamic vehicular environment, since they can hardly balance multi-objective optimization problems such as latency reduction, resource utilization, and user experience (UX). To address these challenges, we introduce a novel multi-tier resource allocation and VT migration framework that integrates Graph Convolutional Networks (GCNs), a hierarchical Stackelberg game-based incentive mechanism, and Multi-Agent Deep Reinforcement Learning (MADRL). The GCN-based model captures both spatial and temporal dependencies within the vehicular network; the Stackelberg game-based incentive mechanism fosters cooperation between vehicles and infrastructure; and the MADRL algorithm jointly optimizes resource allocation and VT migration in real time. By modeling this dynamic and multi-tier vehicular Metaverse as a Markov Decision Process (MDP), we develop a MADRL-based algorithm dubbed the Multi-Objective Multi-Agent Deep Deterministic Policy Gradient (MO-MADDPG), which can effectively balances the various conflicting objectives. Extensive simulations validate the effectiveness of this algorithm that is demonstrated to enhance scalability, reliability, and efficiency while considerably improving latency, resource utilization, migration cost, and overall UX by 12.8%, 9.7%, 14.2%, and 16.1%, respectively.
Deep Learning-Enabled Text Semantic Communication under Interference: An Empirical Study
Oct 30, 2023At the confluence of 6G, deep learning (DL), and natural language processing (NLP), DL-enabled text semantic communication (SemCom) has emerged as a 6G enabler by promising to minimize bandwidth consumption, transmission delay, and power usage. Among text SemCom techniques, \textit{DeepSC} is a popular scheme that leverages advancements in DL and NLP to reliably transmit semantic information in low signal-to-noise ratio (SNR) regimes. To understand the fundamental limits of such a transmission paradigm, our recently developed theory \cite{Getu'23_Performance_Limits} predicted the performance limits of DeepSC under radio frequency interference (RFI). Although these limits were corroborated by simulations, trained deep networks can defy classical statistical wisdom, and hence extensive computer experiments are needed to validate our theory. Accordingly, this empirical work follows concerning the training and testing of DeepSC using the proceedings of the European Parliament (Europarl) dataset. Employing training, validation, and testing sets \textit{tokenized and vectorized} from Europarl, we train the DeepSC architecture in Keras 2.9 with TensorFlow 2.9 as a backend and test it under Gaussian multi-interferer RFI received over Rayleigh fading channels. Validating our theory, the testing results corroborate that DeepSC produces semantically irrelevant sentences as the number of Gaussian RFI emitters gets very large. Therefore, a fundamental 6G design paradigm for \textit{interference-resistant and robust SemCom} (IR$^2$ SemCom) is needed.
Fundamental Limits of Deep Learning-Based Binary Classifiers Trained with Hinge Loss
Sep 13, 2023Although deep learning (DL) has led to several breakthroughs in many disciplines as diverse as chemistry, computer science, electrical engineering, mathematics, medicine, neuroscience, and physics, a comprehensive understanding of why and how DL is empirically successful remains fundamentally elusive. To attack this fundamental problem and unravel the mysteries behind DL's empirical successes, significant innovations toward a unified theory of DL have been made. These innovations encompass nearly fundamental advances in optimization, generalization, and approximation. Despite these advances, however, no work to date has offered a way to quantify the testing performance of a DL-based algorithm employed to solve a pattern classification problem. To overcome this fundamental challenge in part, this paper exposes the fundamental testing performance limits of DL-based binary classifiers trained with hinge loss. For binary classifiers that are based on deep rectified linear unit (ReLU) feedforward neural networks (FNNs) and ones that are based on deep FNNs with ReLU and Tanh activation, we derive their respective novel asymptotic testing performance limits. The derived testing performance limits are validated by extensive computer experiments.
Making Sense of Meaning: A Survey on Metrics for Semantic and Goal-Oriented Communication
Mar 20, 2023Semantic communication (SemCom) aims to convey the meaning behind a transmitted message by transmitting only semantically-relevant information. This semantic-centric design helps to minimize power usage, bandwidth consumption, and transmission delay. SemCom and goal-oriented SemCom (or effectiveness-level SemCom) are therefore promising enablers of 6G and developing rapidly. Despite the surge in their swift development, the design, analysis, optimization, and realization of robust and intelligent SemCom as well as goal-oriented SemCom are fraught with many fundamental challenges. One of the challenges is that the lack of unified/universal metrics of SemCom and goal-oriented SemCom can stifle research progress on their respective algorithmic, theoretical, and implementation frontiers. Consequently, this survey paper documents the existing metrics -- scattered in many references -- of wireless SemCom, optical SemCom, quantum SemCom, and goal-oriented wireless SemCom. By doing so, this paper aims to inspire the design, analysis, and optimization of a wide variety of SemCom and goal-oriented SemCom systems. This article also stimulates the development of unified/universal performance assessment metrics of SemCom and goal-oriented SemCom, as the existing metrics are purely statistical and hardly applicable to reasoning-type tasks that constitute the heart of 6G and beyond.
Performance Limits of a Deep Learning-Enabled Text Semantic Communication under Interference
Feb 15, 2023Semantic communication (SemCom) has emerged as a 6G enabler while promising to minimize power usage, bandwidth consumption, and transmission delay by minimizing irrelevant information transmission. However, the benefits of such a semantic-centric design can be limited by radio frequency interference (RFI) that causes substantial semantic noise. The impact of semantic noise due to interference can be alleviated using an interference-resistant and robust (IR$^2$) SemCom design. Nevertheless, no such design exists yet. To shed light on this knowledge gap and stimulate fundamental research on IR$^2$ SemCom, the performance limits of a text SemCom system named DeepSC is studied in the presence of single- and multi-interferer RFI. By introducing a principled probabilistic framework for SemCom, we show that DeepSC produces semantically irrelevant sentences as the power of single- and multi-interferer RFI gets very large. Corroborated by Monte Carlo simulations, these performance limits offer design insights -- regarding IR$^2$ SemCom -- contrary to the theoretically unsubstantiated sentiment that SemCom techniques (such as DeepSC) work well in very low signal-to-noise ratio regimes. The performance limits also reveal the vulnerability of DeepSC and SemCom to a wireless attack using RFI. Furthermore, our introduced probabilistic framework inspires the performance analysis of many text SemCom techniques, as they are chiefly inspired by DeepSC.
Error Bounds for a Matrix-Vector Product Approximation with Deep ReLU Neural Networks
Nov 25, 2021
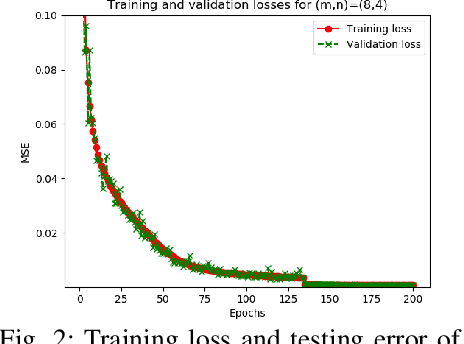
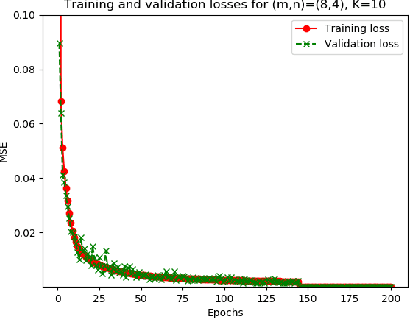
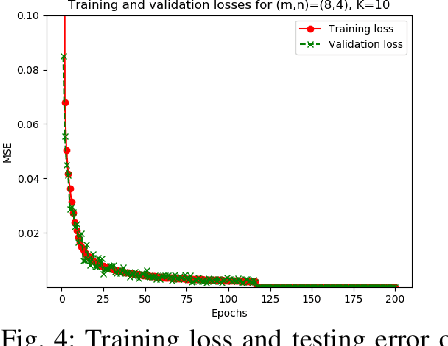
Among the several paradigms of artificial intelligence (AI) or machine learning (ML), a remarkably successful paradigm is deep learning. Deep learning's phenomenal success has been hoped to be interpreted via fundamental research on the theory of deep learning. Accordingly, applied research on deep learning has spurred the theory of deep learning-oriented depth and breadth of developments. Inspired by such developments, we pose these fundamental questions: can we accurately approximate an arbitrary matrix-vector product using deep rectified linear unit (ReLU) feedforward neural networks (FNNs)? If so, can we bound the resulting approximation error? In light of these questions, we derive error bounds in Lebesgue and Sobolev norms that comprise our developed deep approximation theory. Guided by this theory, we have successfully trained deep ReLU FNNs whose test results justify our developed theory. The developed theory is also applicable for guiding and easing the training of teacher deep ReLU FNNs in view of the emerging teacher-student AI or ML paradigms that are essential for solving several AI or ML problems in wireless communications and signal processing; network science and graph signal processing; and network neuroscience and brain physics.