 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEight Years of Face Recognition Research: Reproducibility, Achievements and Open Issues
Aug 09, 2022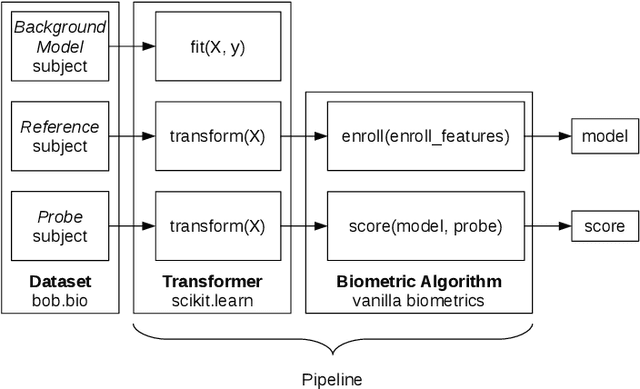
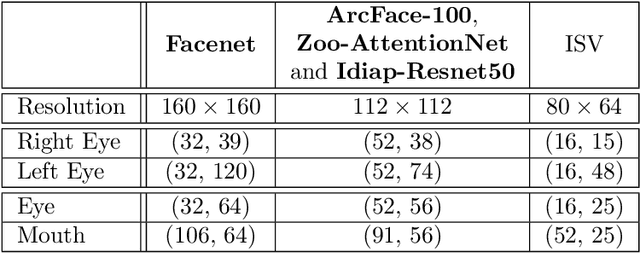

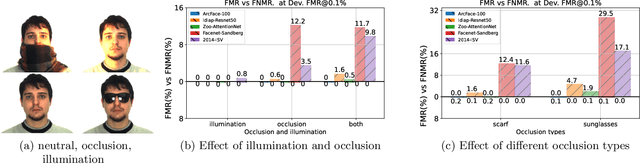
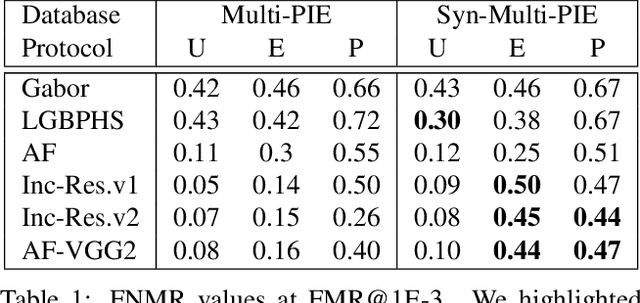
Automatic face recognition is a research area with high popularity. Many different face recognition algorithms have been proposed in the last thirty years of intensive research in the field. With the popularity of deep learning and its capability to solve a huge variety of different problems, face recognition researchers have concentrated effort on creating better models under this paradigm. From the year 2015, state-of-the-art face recognition has been rooted in deep learning models. Despite the availability of large-scale and diverse datasets for evaluating the performance of face recognition algorithms, many of the modern datasets just combine different factors that influence face recognition, such as face pose, occlusion, illumination, facial expression and image quality. When algorithms produce errors on these datasets, it is not clear which of the factors has caused this error and, hence, there is no guidance in which direction more research is required. This work is a followup from our previous works developed in 2014 and eventually published in 2016, showing the impact of various facial aspects on face recognition algorithms. By comparing the current state-of-the-art with the best systems from the past, we demonstrate that faces under strong occlusions, some types of illumination, and strong expressions are problems mastered by deep learning algorithms, whereas recognition with low-resolution images, extreme pose variations, and open-set recognition is still an open problem. To show this, we run a sequence of experiments using six different datasets and five different face recognition algorithms in an open-source and reproducible manner. We provide the source code to run all of our experiments, which is easily extensible so that utilizing your own deep network in our evaluation is just a few minutes away.
On the use of automatically generated synthetic image datasets for benchmarking face recognition
Jun 08, 2021

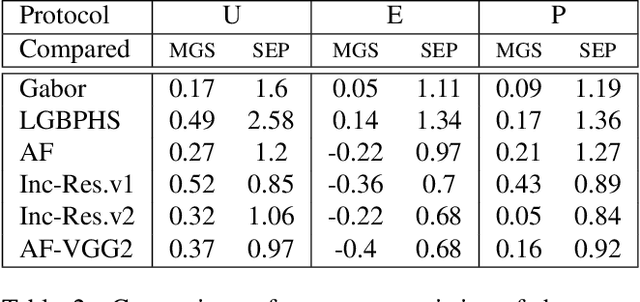
The availability of large-scale face datasets has been key in the progress of face recognition. However, due to licensing issues or copyright infringement, some datasets are not available anymore (e.g. MS-Celeb-1M). Recent advances in Generative Adversarial Networks (GANs), to synthesize realistic face images, provide a pathway to replace real datasets by synthetic datasets, both to train and benchmark face recognition (FR) systems. The work presented in this paper provides a study on benchmarking FR systems using a synthetic dataset. First, we introduce the proposed methodology to generate a synthetic dataset, without the need for human intervention, by exploiting the latent structure of a StyleGAN2 model with multiple controlled factors of variation. Then, we confirm that (i) the generated synthetic identities are not data subjects from the GAN's training dataset, which is verified on a synthetic dataset with 10K+ identities; (ii) benchmarking results on the synthetic dataset are a good substitution, often providing error rates and system ranking similar to the benchmarking on the real dataset.
Fairness in Biometrics: a figure of merit to assess biometric verification systems
Nov 04, 2020
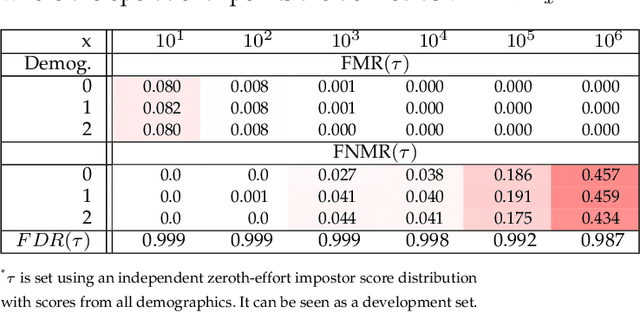


Machine learning-based (ML) systems are being largely deployed since the last decade in a myriad of scenarios impacting several instances in our daily lives. With this vast sort of applications, aspects of fairness start to rise in the spotlight due to the social impact that this can get in minorities. In this work aspects of fairness in biometrics are addressed. First, we introduce the first figure of merit that is able to evaluate and compare fairness aspects between multiple biometric verification systems, the so-called Fairness Discrepancy Rate (FDR). A use case with two synthetic biometric systems is introduced and demonstrates the potential of this figure of merit in extreme cases of fair and unfair behavior. Second, a use case using face biometrics is presented where several systems are evaluated compared with this new figure of merit using three public datasets exploring gender and race demographics.