 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Evaluation of Textual Backdoor Learning: Frameworks and Benchmarks
Paper and Code



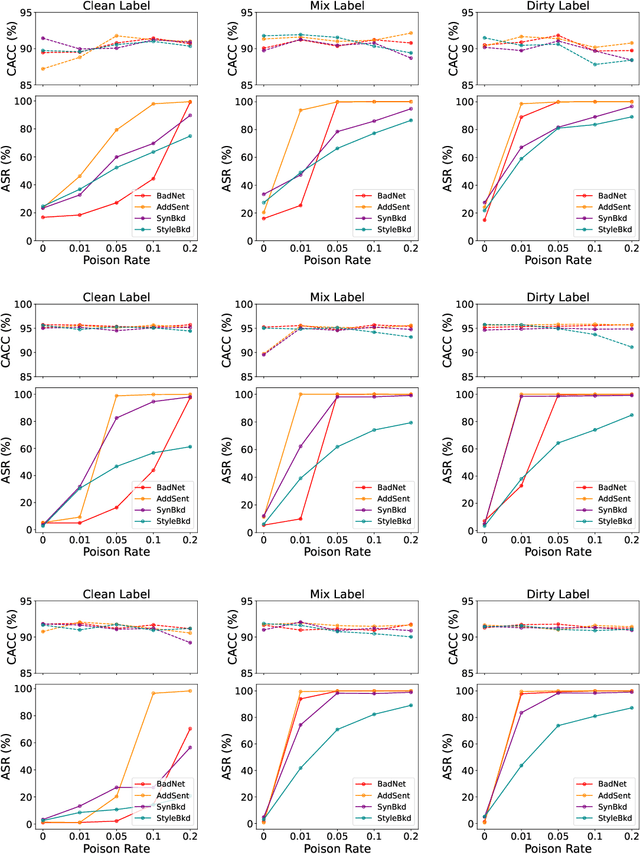
Textual backdoor attacks are a kind of practical threat to NLP systems. By injecting a backdoor in the training phase, the adversary could control model predictions via predefined triggers. As various attack and defense models have been proposed, it is of great significance to perform rigorous evaluations. However, we highlight two issues in previous backdoor learning evaluations: (1) The differences between real-world scenarios (e.g. releasing poisoned datasets or models) are neglected, and we argue that each scenario has its own constraints and concerns, thus requires specific evaluation protocols; (2) The evaluation metrics only consider whether the attacks could flip the models' predictions on poisoned samples and retain performances on benign samples, but ignore that poisoned samples should also be stealthy and semantic-preserving. To address these issues, we categorize existing works into three practical scenarios in which attackers release datasets, pre-trained models, and fine-tuned models respectively, then discuss their unique evaluation methodologies. On metrics, to completely evaluate poisoned samples, we use grammar error increase and perplexity difference for stealthiness, along with text similarity for validity. After formalizing the frameworks, we develop an open-source toolkit OpenBackdoor to foster the implementations and evaluations of textual backdoor learning. With this toolkit, we perform extensive experiments to benchmark attack and defense models under the suggested paradigm. To facilitate the underexplored defenses against poisoned datasets, we further propose CUBE, a simple yet strong clustering-based defense baseline. We hope that our frameworks and benchmarks could serve as the cornerstones for future model development and evaluations.