 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Generalization during Instruction Tuning: Insights from Similarity and Granularity
Paper and Code
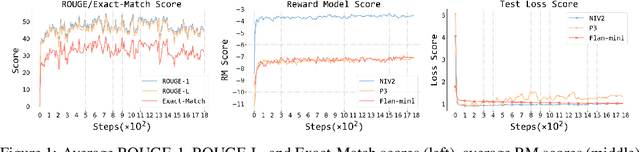

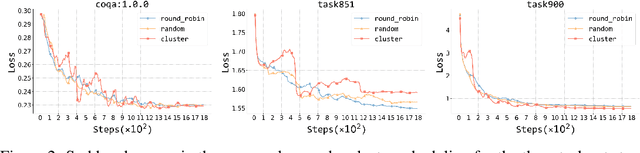

Understanding alignment techniques begins with comprehending zero-shot generalization brought by instruction tuning, but little of the mechanism has been understood. Existing work has largely been confined to the task level, without considering that tasks are artificially defined and, to LLMs, merely consist of tokens and representations. This line of research has been limited to examining transfer between tasks from a task-pair perspective, with few studies focusing on understanding zero-shot generalization from the perspective of the data itself. To bridge this gap, we first demonstrate through multiple metrics that zero-shot generalization during instruction tuning happens very early. Next, we investigate the facilitation of zero-shot generalization from both data similarity and granularity perspectives, confirming that encountering highly similar and fine-grained training data earlier during instruction tuning, without the constraints of defined "tasks", enables better generalization. Finally, we propose a more grounded training data arrangement method, Test-centric Multi-turn Arrangement, and show its effectiveness in promoting continual learning and further loss reduction. For the first time, we show that zero-shot generalization during instruction tuning is a form of similarity-based generalization between training and test data at the instance level. We hope our analysis will advance the understanding of zero-shot generalization during instruction tuning and contribute to the development of more aligned LLMs. Our code is released at https://github.com/HBX-hbx/dynamics_of_zero-shot_generalization.