 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountFormer: Multi-View Crowd Counting Transformer
Paper and Code
Jul 02, 2024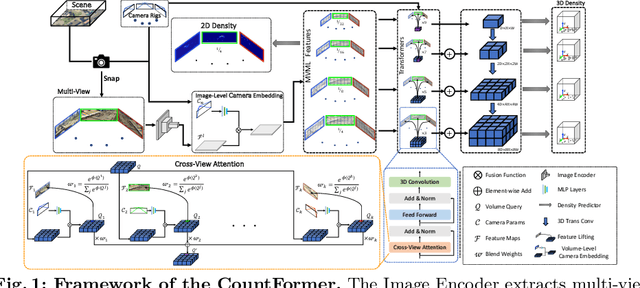


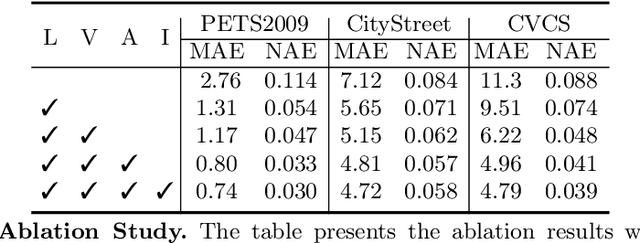
Multi-view counting (MVC) methods have shown their superiority over single-view counterparts, particularly in situations characterized by heavy occlusion and severe perspective distortions. However, hand-crafted heuristic features and identical camera layout requirements in conventional MVC methods limit their applicability and scalability in real-world scenarios.In this work, we propose a concise 3D MVC framework called \textbf{CountFormer}to elevate multi-view image-level features to a scene-level volume representation and estimate the 3D density map based on the volume features. By incorporating a camera encoding strategy, CountFormer successfully embeds camera parameters into the volume query and image-level features, enabling it to handle various camera layouts with significant differences.Furthermore, we introduce a feature lifting module capitalized on the attention mechanism to transform image-level features into a 3D volume representation for each camera view. Subsequently, the multi-view volume aggregation module attentively aggregates various multi-view volumes to create a comprehensive scene-level volume representation, allowing CountFormer to handle images captured by arbitrary dynamic camera layouts. The proposed method performs favorably against the state-of-the-art approaches across various widely used datasets, demonstrating its greater suitability for real-world deployment compared to conventional MVC frameworks.