 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Crowd Counting With Self-Supervised Learning
Sep 26, 2025Multi-view counting (MVC) methods have attracted significant research attention and stimulated remarkable progress in recent years. Despite their success, most MVC methods have focused on improving performance by following the fully supervised learning (FSL) paradigm, which often requires large amounts of annotated data. In this work, we propose SSLCounter, a novel self-supervised learning (SSL) framework for MVC that leverages neural volumetric rendering to alleviate the reliance on large-scale annotated datasets. SSLCounter learns an implicit representation w.r.t. the scene, enabling the reconstruction of continuous geometry shape and the complex, view-dependent appearance of their 2D projections via differential neural rendering. Owing to its inherent flexibility, the key idea of our method can be seamlessly integrated into exsiting frameworks. Notably, extensive experiments demonstrate that SSLCounter not only demonstrates state-of-the-art performances but also delivers competitive performance with only using 70% proportion of training data, showcasing its superior data efficiency across multiple MVC benchmarks.
CountFormer: Multi-View Crowd Counting Transformer
Jul 02, 2024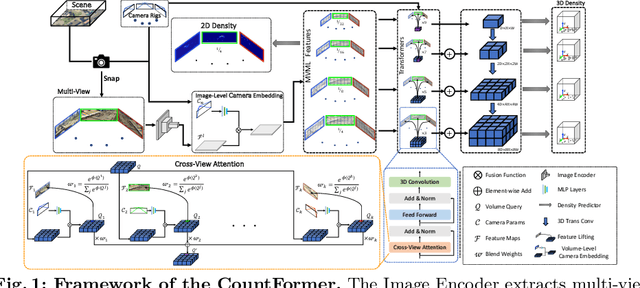


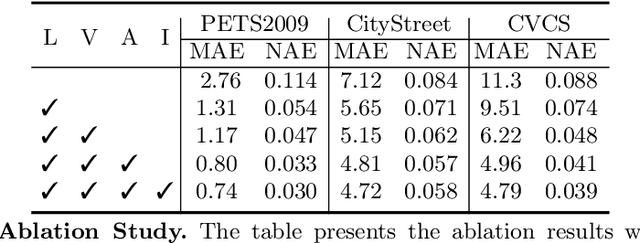
Multi-view counting (MVC) methods have shown their superiority over single-view counterparts, particularly in situations characterized by heavy occlusion and severe perspective distortions. However, hand-crafted heuristic features and identical camera layout requirements in conventional MVC methods limit their applicability and scalability in real-world scenarios.In this work, we propose a concise 3D MVC framework called \textbf{CountFormer}to elevate multi-view image-level features to a scene-level volume representation and estimate the 3D density map based on the volume features. By incorporating a camera encoding strategy, CountFormer successfully embeds camera parameters into the volume query and image-level features, enabling it to handle various camera layouts with significant differences.Furthermore, we introduce a feature lifting module capitalized on the attention mechanism to transform image-level features into a 3D volume representation for each camera view. Subsequently, the multi-view volume aggregation module attentively aggregates various multi-view volumes to create a comprehensive scene-level volume representation, allowing CountFormer to handle images captured by arbitrary dynamic camera layouts. The proposed method performs favorably against the state-of-the-art approaches across various widely used datasets, demonstrating its greater suitability for real-world deployment compared to conventional MVC frameworks.
DCNAS: Densely Connected Neural Architecture Search for Semantic Image Segmentation
Mar 26, 2020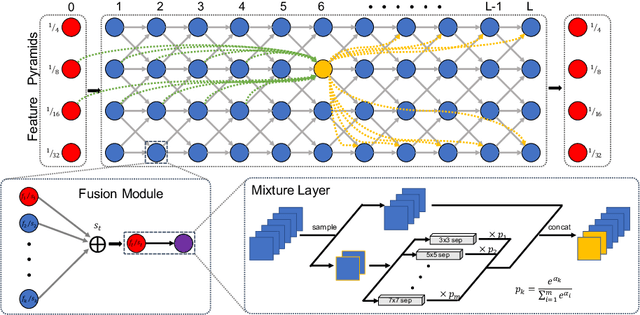
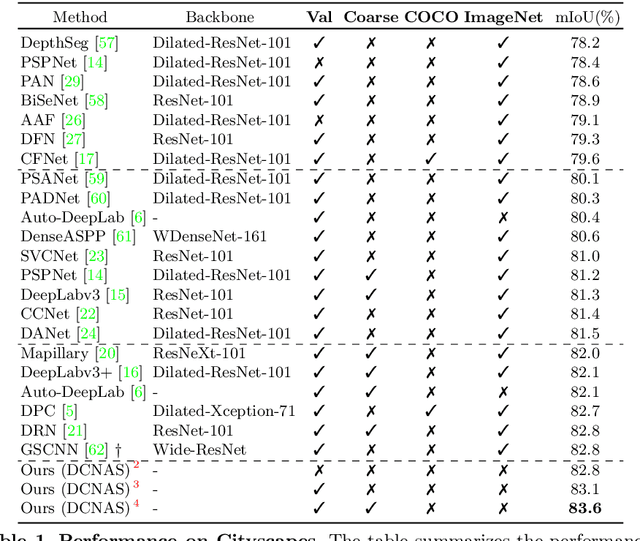
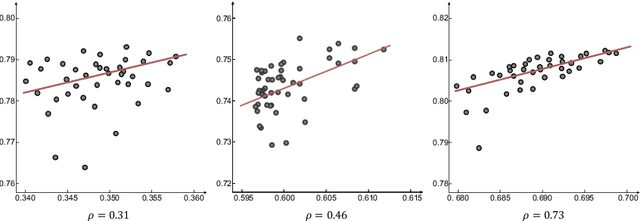
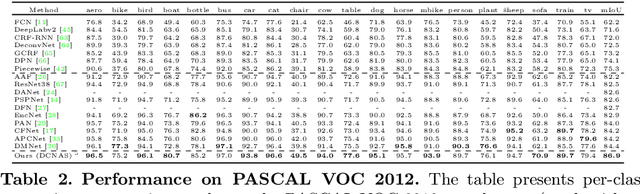
Neural Architecture Search (NAS) has shown great potentials in automatically designing scalable network architectures for dense image predictions. However, existing NAS algorithms usually compromise on restricted search space and search on proxy task to meet the achievable computational demands. To allow as wide as possible network architectures and avoid the gap between target and proxy dataset, we propose a Densely Connected NAS (DCNAS) framework, which directly searches the optimal network structures for the multi-scale representations of visual information, over a large-scale target dataset. Specifically, by connecting cells with each other using learnable weights, we introduce a densely connected search space to cover an abundance of mainstream network designs. Moreover, by combining both path-level and channel-level sampling strategies, we design a fusion module to reduce the memory consumption of ample search space. We demonstrate that the architecture obtained from our DCNAS algorithm achieves state-of-the-art performances on public semantic image segmentation benchmarks, including 83.6% on Cityscapes, and 86.9% on PASCAL VOC 2012 (track w/o additional data). We also retain leading performances when evaluating the architecture on the more challenging ADE20K and Pascal Context dataset.