 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
DSARSR: Deep Stacked Auto-encoders Enhanced Robust Speaker Recognition
Jul 06, 2023Speaker recognition is a biometric modality that utilizes the speaker's speech segments to recognize the identity, determining whether the test speaker belongs to one of the enrolled speakers. In order to improve the robustness of the i-vector framework on cross-channel conditions and explore the nova method for applying deep learning to speaker recognition, the Stacked Auto-encoders are used to get the abstract extraction of the i-vector instead of applying PLDA. After pre-processing and feature extraction, the speaker and channel-independent speeches are employed for UBM training. The UBM is then used to extract the i-vector of the enrollment and test speech. Unlike the traditional i-vector framework, which uses linear discriminant analysis (LDA) to reduce dimension and increase the discrimination between speaker subspaces, this research use stacked auto-encoders to reconstruct the i-vector with lower dimension and different classifiers can be chosen to achieve final classification. The experimental results show that the proposed method achieves better performance than the state-of-the-art method.
Learning Behavior Recognition in Smart Classroom with Multiple Students Based on YOLOv5
Mar 20, 2023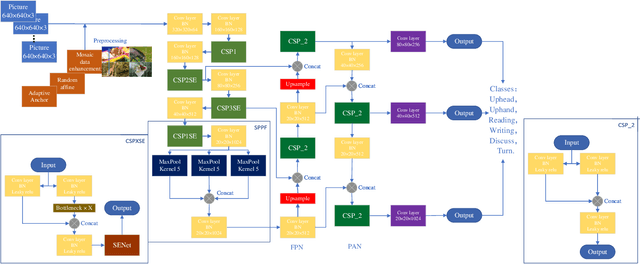
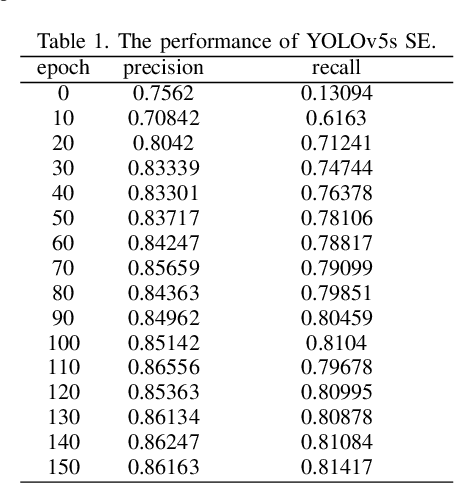
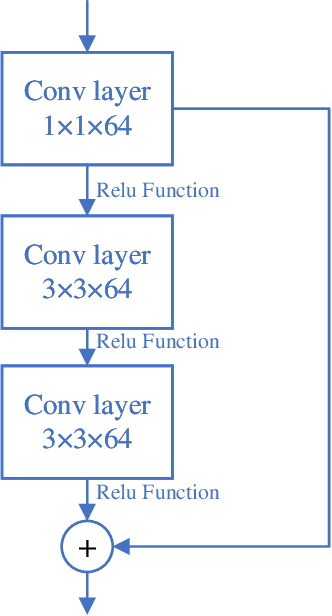
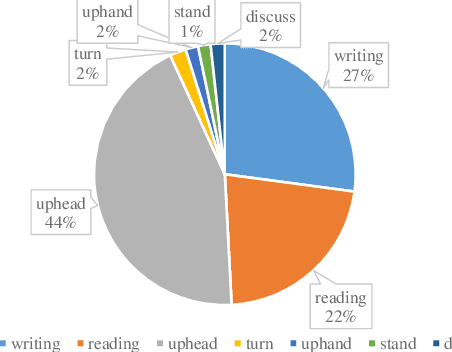
Deep learning-based computer vision technology has grown stronger in recent years, and cross-fertilization using computer vision technology has been a popular direction in recent years. The use of computer vision technology to identify students' learning behavior in the classroom can reduce the workload of traditional teachers in supervising students in the classroom, and ensure greater accuracy and comprehensiveness. However, existing student learning behavior detection systems are unable to track and detect multiple targets precisely, and the accuracy of learning behavior recognition is not high enough to meet the existing needs for the accurate recognition of student behavior in the classroom. To solve this problem, we propose a YOLOv5s network structure based on you only look once (YOLO) algorithm to recognize and analyze students' classroom behavior in this paper. Firstly, the input images taken in the smart classroom are pre-processed. Then, the pre-processed image is fed into the designed YOLOv5 networks to extract deep features through convolutional layers, and the Squeeze-and-Excitation (SE) attention detection mechanism is applied to reduce the weight of background information in the recognition process. Finally, the extracted features are classified by the Feature Pyramid Networks (FPN) and Path Aggregation Network (PAN) structures. Multiple groups of experiments were performed to compare with traditional learning behavior recognition methods to validate the effectiveness of the proposed method. When compared with YOLOv4, the proposed method is able to improve the mAP performance by 11%.
Graph Neural Networks Enhanced Smart Contract Vulnerability Detection of Educational Blockchain
Mar 08, 2023With the development of blockchain technology, more and more attention has been paid to the intersection of blockchain and education, and various educational evaluation systems and E-learning systems are developed based on blockchain technology. Among them, Ethereum smart contract is favored by developers for its ``event-triggered" mechanism for building education intelligent trading systems and intelligent learning platforms. However, due to the immutability of blockchain, published smart contracts cannot be modified, so problematic contracts cannot be fixed by modifying the code in the educational blockchain. In recent years, security incidents due to smart contract vulnerabilities have caused huge property losses, so the detection of smart contract vulnerabilities in educational blockchain has become a great challenge. To solve this problem, this paper proposes a graph neural network (GNN) based vulnerability detection for smart contracts in educational blockchains. Firstly, the bytecodes are decompiled to get the opcode. Secondly, the basic blocks are divided, and the edges between the basic blocks according to the opcode execution logic are added. Then, the control flow graphs (CFG) are built. Finally, we designed a GNN-based model for vulnerability detection. The experimental results show that the proposed method is effective for the vulnerability detection of smart contracts. Compared with the traditional approaches, it can get good results with fewer layers of the GCN model, which shows that the contract bytecode and GCN model are efficient in vulnerability detection.
Convolutional Embedding Makes Hierarchical Vision Transformer Stronger
Aug 01, 2022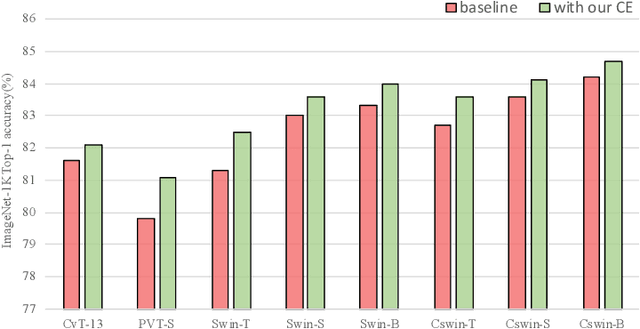
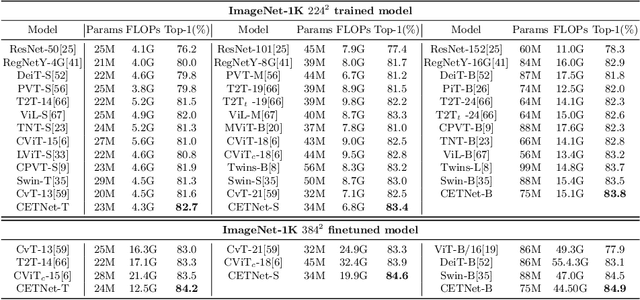
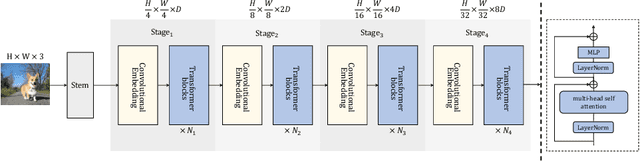
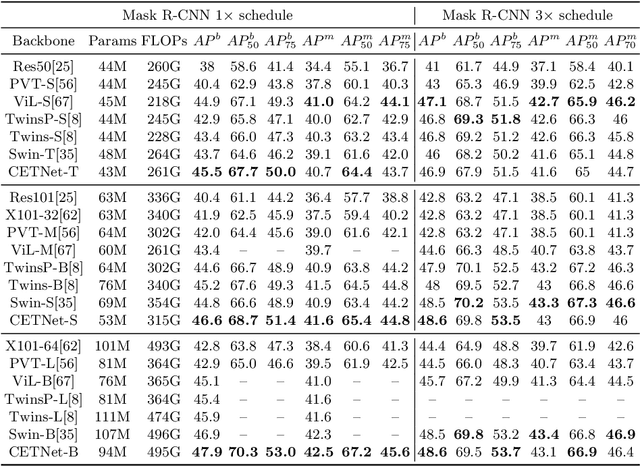
Vision Transformers (ViTs) have recently dominated a range of computer vision tasks, yet it suffers from low training data efficiency and inferior local semantic representation capability without appropriate inductive bias. Convolutional neural networks (CNNs) inherently capture regional-aware semantics, inspiring researchers to introduce CNNs back into the architecture of the ViTs to provide desirable inductive bias for ViTs. However, is the locality achieved by the micro-level CNNs embedded in ViTs good enough? In this paper, we investigate the problem by profoundly exploring how the macro architecture of the hybrid CNNs/ViTs enhances the performances of hierarchical ViTs. Particularly, we study the role of token embedding layers, alias convolutional embedding (CE), and systemically reveal how CE injects desirable inductive bias in ViTs. Besides, we apply the optimal CE configuration to 4 recently released state-of-the-art ViTs, effectively boosting the corresponding performances. Finally, a family of efficient hybrid CNNs/ViTs, dubbed CETNets, are released, which may serve as generic vision backbones. Specifically, CETNets achieve 84.9% Top-1 accuracy on ImageNet-1K (training from scratch), 48.6% box mAP on the COCO benchmark, and 51.6% mIoU on the ADE20K, substantially improving the performances of the corresponding state-of-the-art baselines.
Hand Image Understanding via Deep Multi-Task Learning
Jul 28, 2021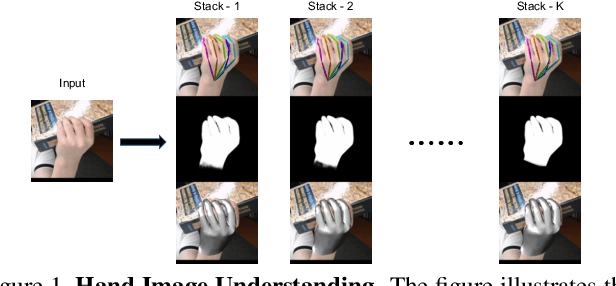

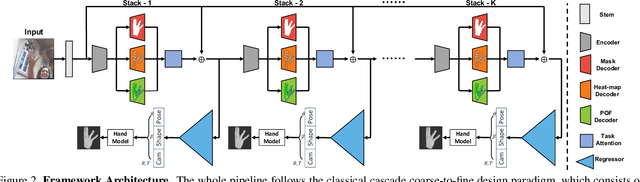
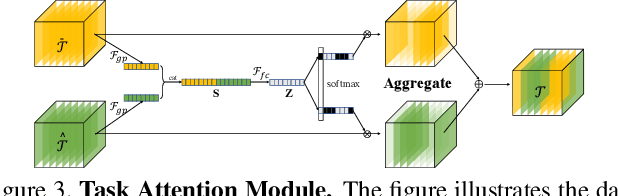
Analyzing and understanding hand information from multimedia materials like images or videos is important for many real world applications and remains active in research community. There are various works focusing on recovering hand information from single image, however, they usually solve a single task, for example, hand mask segmentation, 2D/3D hand pose estimation, or hand mesh reconstruction and perform not well in challenging scenarios. To further improve the performance of these tasks, we propose a novel Hand Image Understanding (HIU) framework to extract comprehensive information of the hand object from a single RGB image, by jointly considering the relationships between these tasks. To achieve this goal, a cascaded multi-task learning (MTL) backbone is designed to estimate the 2D heat maps, to learn the segmentation mask, and to generate the intermediate 3D information encoding, followed by a coarse-to-fine learning paradigm and a self-supervised learning strategy. Qualitative experiments demonstrate that our approach is capable of recovering reasonable mesh representations even in challenging situations. Quantitatively, our method significantly outperforms the state-of-the-art approaches on various widely-used datasets, in terms of diverse evaluation metrics.
DCNAS: Densely Connected Neural Architecture Search for Semantic Image Segmentation
Mar 26, 2020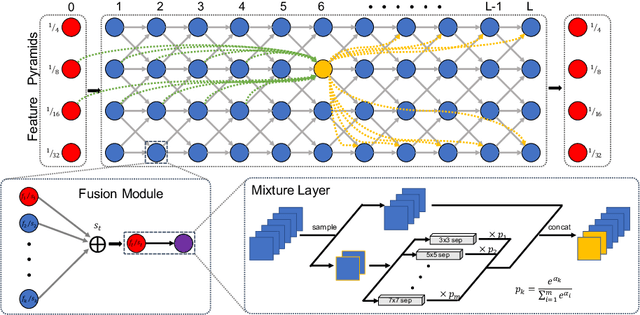
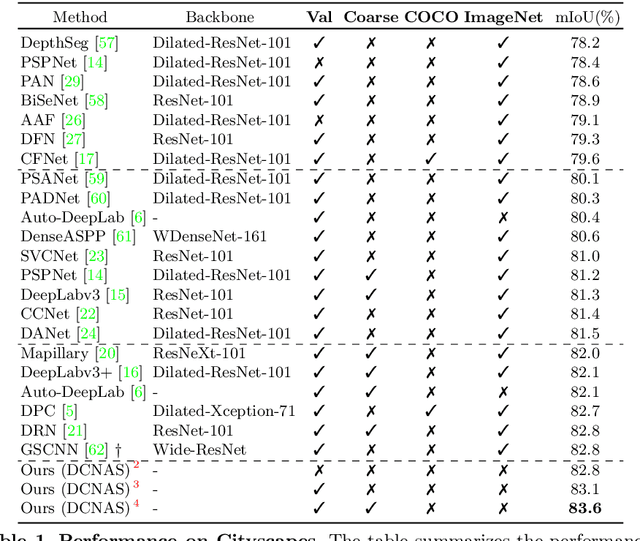
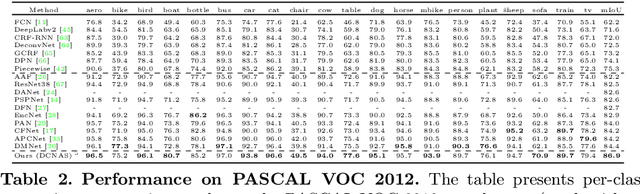
Neural Architecture Search (NAS) has shown great potentials in automatically designing scalable network architectures for dense image predictions. However, existing NAS algorithms usually compromise on restricted search space and search on proxy task to meet the achievable computational demands. To allow as wide as possible network architectures and avoid the gap between target and proxy dataset, we propose a Densely Connected NAS (DCNAS) framework, which directly searches the optimal network structures for the multi-scale representations of visual information, over a large-scale target dataset. Specifically, by connecting cells with each other using learnable weights, we introduce a densely connected search space to cover an abundance of mainstream network designs. Moreover, by combining both path-level and channel-level sampling strategies, we design a fusion module to reduce the memory consumption of ample search space. We demonstrate that the architecture obtained from our DCNAS algorithm achieves state-of-the-art performances on public semantic image segmentation benchmarks, including 83.6% on Cityscapes, and 86.9% on PASCAL VOC 2012 (track w/o additional data). We also retain leading performances when evaluating the architecture on the more challenging ADE20K and Pascal Context dataset.
StyleRemix: An Interpretable Representation for Neural Image Style Transfer
Mar 25, 2019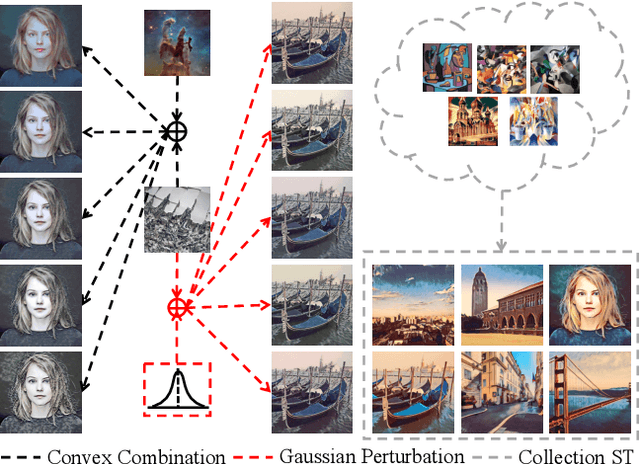

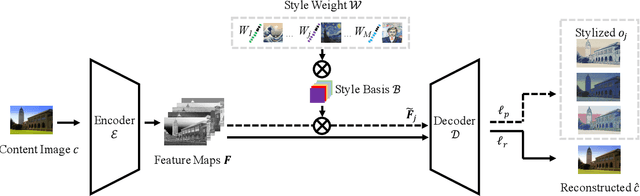
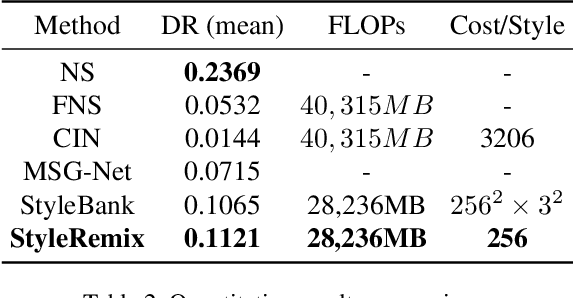
Multi-Style Transfer (MST) intents to capture the high-level visual vocabulary of different styles and expresses these vocabularies in a joint model to transfer each specific style. Recently, Style Embedding Learning (SEL) based methods represent each style with an explicit set of parameters to perform MST task. However, most existing SEL methods either learn explicit style representation with numerous independent parameters or learn a relatively black-box style representation, which makes them difficult to control the stylized results. In this paper, we outline a novel MST model, StyleRemix, to compactly and explicitly integrate multiple styles into one network. By decomposing diverse styles into the same basis, StyleRemix represents a specific style in a continuous vector space with 1-dimensional coefficients. With the interpretable style representation, StyleRemix not only enables the style visualization task but also allows several ways of remixing styles in the smooth style embedding space.~Extensive experiments demonstrate the effectiveness of StyleRemix on various MST tasks compared to state-of-the-art SEL approaches.