 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHand Image Understanding via Deep Multi-Task Learning
Jul 28, 2021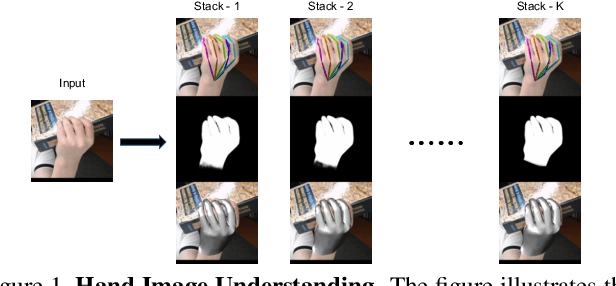

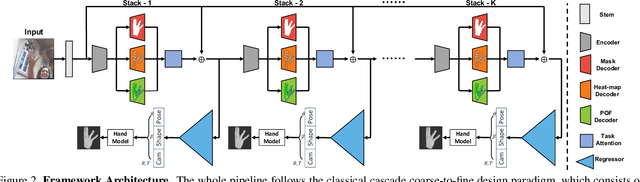
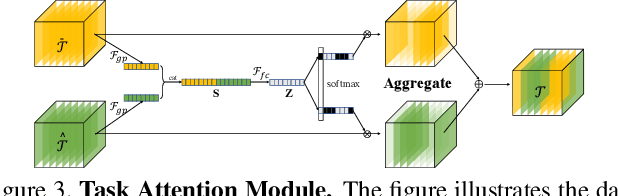
Analyzing and understanding hand information from multimedia materials like images or videos is important for many real world applications and remains active in research community. There are various works focusing on recovering hand information from single image, however, they usually solve a single task, for example, hand mask segmentation, 2D/3D hand pose estimation, or hand mesh reconstruction and perform not well in challenging scenarios. To further improve the performance of these tasks, we propose a novel Hand Image Understanding (HIU) framework to extract comprehensive information of the hand object from a single RGB image, by jointly considering the relationships between these tasks. To achieve this goal, a cascaded multi-task learning (MTL) backbone is designed to estimate the 2D heat maps, to learn the segmentation mask, and to generate the intermediate 3D information encoding, followed by a coarse-to-fine learning paradigm and a self-supervised learning strategy. Qualitative experiments demonstrate that our approach is capable of recovering reasonable mesh representations even in challenging situations. Quantitatively, our method significantly outperforms the state-of-the-art approaches on various widely-used datasets, in terms of diverse evaluation metrics.
Exploring Adversarial Learning for Deep Semi-Supervised Facial Action Unit Recognition
Jun 04, 2021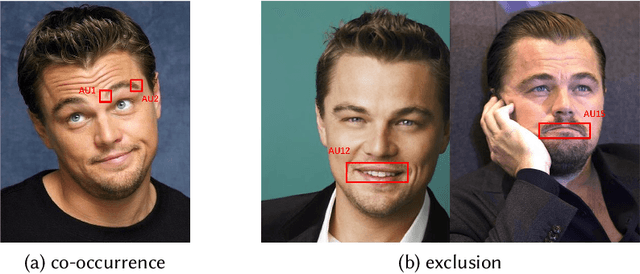
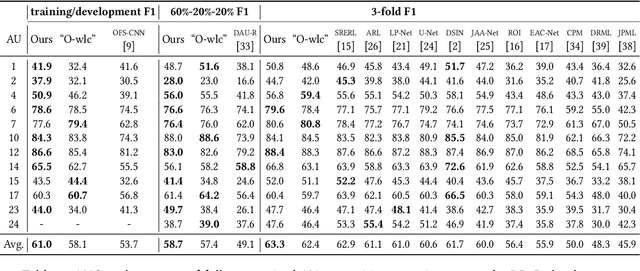
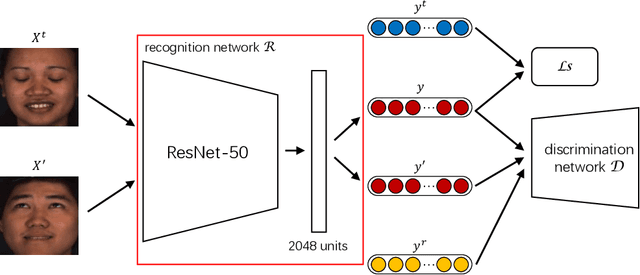
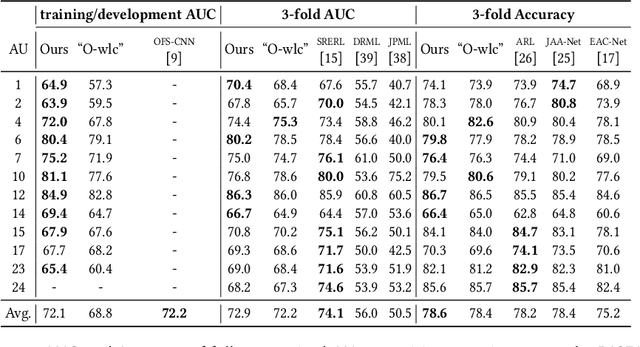
Current works formulate facial action unit (AU) recognition as a supervised learning problem, requiring fully AU-labeled facial images during training. It is challenging if not impossible to provide AU annotations for large numbers of facial images. Fortunately, AUs appear on all facial images, whether manually labeled or not, satisfy the underlying anatomic mechanisms and human behavioral habits. In this paper, we propose a deep semi-supervised framework for facial action unit recognition from partially AU-labeled facial images. Specifically, the proposed deep semi-supervised AU recognition approach consists of a deep recognition network and a discriminator D. The deep recognition network R learns facial representations from large-scale facial images and AU classifiers from limited ground truth AU labels. The discriminator D is introduced to enforce statistical similarity between the AU distribution inherent in ground truth AU labels and the distribution of the predicted AU labels from labeled and unlabeled facial images. The deep recognition network aims to minimize recognition loss from the labeled facial images, to faithfully represent inherent AU distribution for both labeled and unlabeled facial images, and to confuse the discriminator. During training, the deep recognition network R and the discriminator D are optimized alternately. Thus, the inherent AU distributions caused by underlying anatomic mechanisms are leveraged to construct better feature representations and AU classifiers from partially AU-labeled data during training. Experiments on two benchmark databases demonstrate that the proposed approach successfully captures AU distributions through adversarial learning and outperforms state-of-the-art AU recognition work.