 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleRemix: An Interpretable Representation for Neural Image Style Transfer
Paper and Code
Mar 25, 2019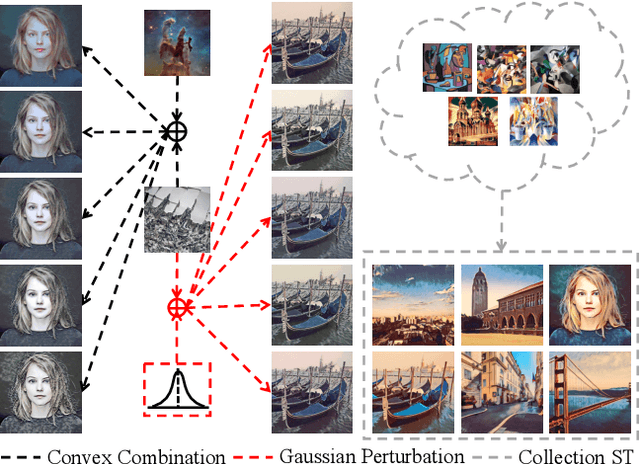

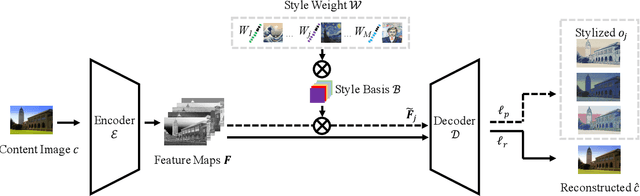
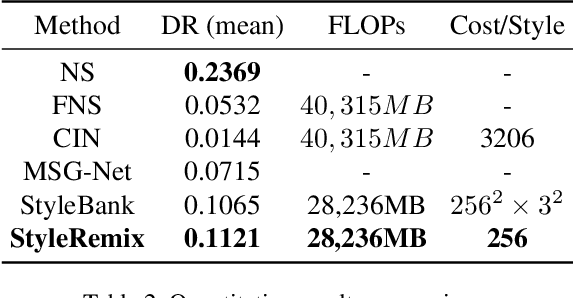
Multi-Style Transfer (MST) intents to capture the high-level visual vocabulary of different styles and expresses these vocabularies in a joint model to transfer each specific style. Recently, Style Embedding Learning (SEL) based methods represent each style with an explicit set of parameters to perform MST task. However, most existing SEL methods either learn explicit style representation with numerous independent parameters or learn a relatively black-box style representation, which makes them difficult to control the stylized results. In this paper, we outline a novel MST model, StyleRemix, to compactly and explicitly integrate multiple styles into one network. By decomposing diverse styles into the same basis, StyleRemix represents a specific style in a continuous vector space with 1-dimensional coefficients. With the interpretable style representation, StyleRemix not only enables the style visualization task but also allows several ways of remixing styles in the smooth style embedding space.~Extensive experiments demonstrate the effectiveness of StyleRemix on various MST tasks compared to state-of-the-art SEL approaches.