 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2T: A Classifier-Based Tree Construction Method in Speculative Decoding
Paper and Code
Feb 19, 2025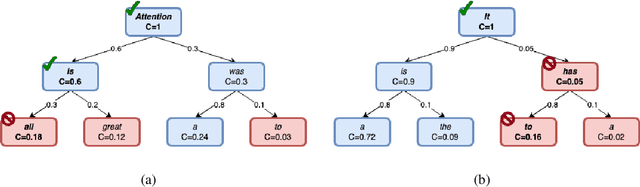
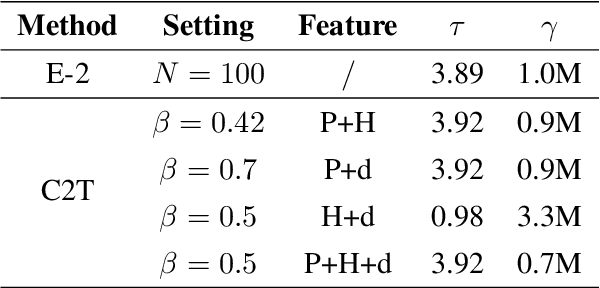

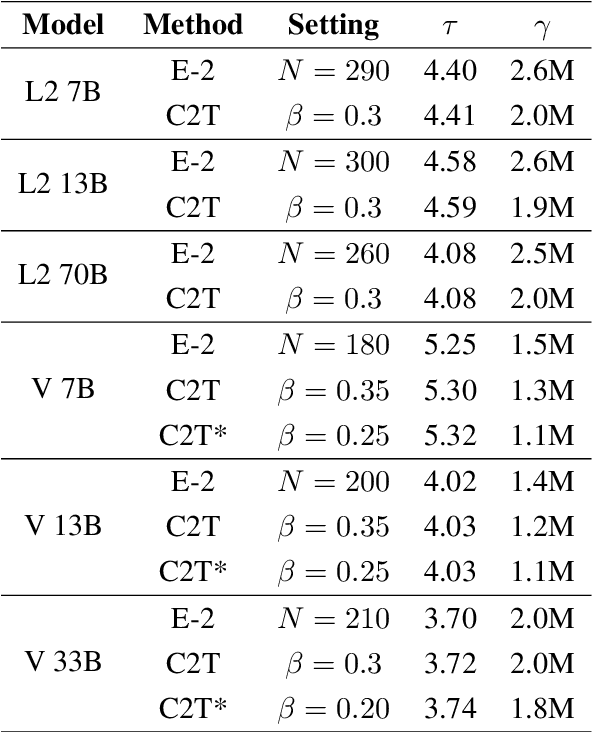
The growing scale of Large Language Models (LLMs) has exacerbated inference latency and computational costs. Speculative decoding methods, which aim to mitigate these issues, often face inefficiencies in the construction of token trees and the verification of candidate tokens. Existing strategies, including chain mode, static tree, and dynamic tree approaches, have limitations in accurately preparing candidate token trees for verification. We propose a novel method named C2T that adopts a lightweight classifier to generate and prune token trees dynamically. Our classifier considers additional feature variables beyond the commonly used joint probability to predict the confidence score for each draft token to determine whether it is the candidate token for verification. This method outperforms state-of-the-art (SOTA) methods such as EAGLE-2 on multiple benchmarks, by reducing the total number of candidate tokens by 25% while maintaining or even improving the acceptance length.