 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Deep Learning on the Edge via Stochastic Local Competition among Subnetworks
Jul 15, 2024



Continual learning on edge devices poses unique challenges due to stringent resource constraints. This paper introduces a novel method that leverages stochastic competition principles to promote sparsity, significantly reducing deep network memory footprint and computational demand. Specifically, we propose deep networks that comprise blocks of units that compete locally to win the representation of each arising new task; competition takes place in a stochastic manner. This type of network organization results in sparse task-specific representations from each network layer; the sparsity pattern is obtained during training and is different among tasks. Crucially, our method sparsifies both the weights and the weight gradients, thus facilitating training on edge devices. This is performed on the grounds of winning probability for each unit in a block. During inference, the network retains only the winning unit and zeroes-out all weights pertaining to non-winning units for the task at hand. Thus, our approach is specifically tailored for deployment on edge devices, providing an efficient and scalable solution for continual learning in resource-limited environments.
A New Dataset for End-to-End Sign Language Translation: The Greek Elementary School Dataset
Oct 07, 2023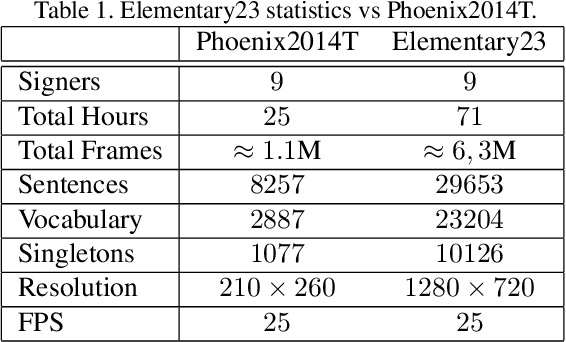

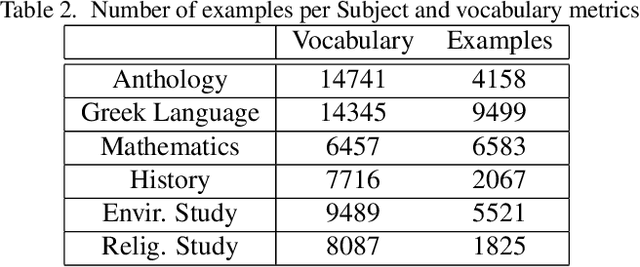
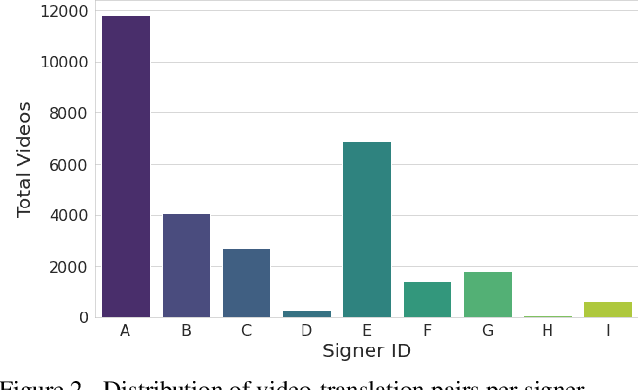
Automatic Sign Language Translation (SLT) is a research avenue of great societal impact. End-to-End SLT facilitates the interaction of Hard-of-Hearing (HoH) with hearing people, thus improving their social life and opportunities for participation in social life. However, research within this frame of reference is still in its infancy, and current resources are particularly limited. Existing SLT methods are either of low translation ability or are trained and evaluated on datasets of restricted vocabulary and questionable real-world value. A characteristic example is Phoenix2014T benchmark dataset, which only covers weather forecasts in German Sign Language. To address this shortage of resources, we introduce a newly constructed collection of 29653 Greek Sign Language video-translation pairs which is based on the official syllabus of Greek Elementary School. Our dataset covers a wide range of subjects. We use this novel dataset to train recent state-of-the-art Transformer-based methods widely used in SLT research. Our results demonstrate the potential of our introduced dataset to advance SLT research by offering a favourable balance between usability and real-world value.
* ICCVW2023 - ACVR
Dialog speech sentiment classification for imbalanced datasets
Sep 15, 2021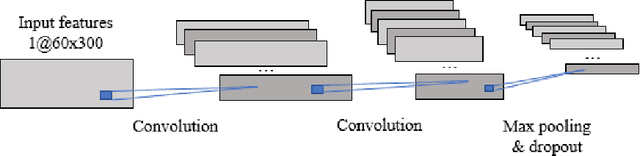
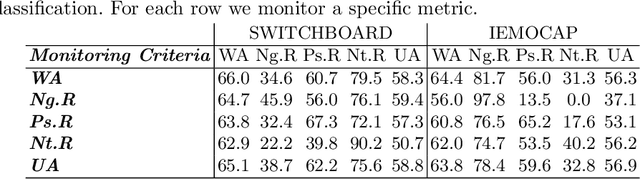
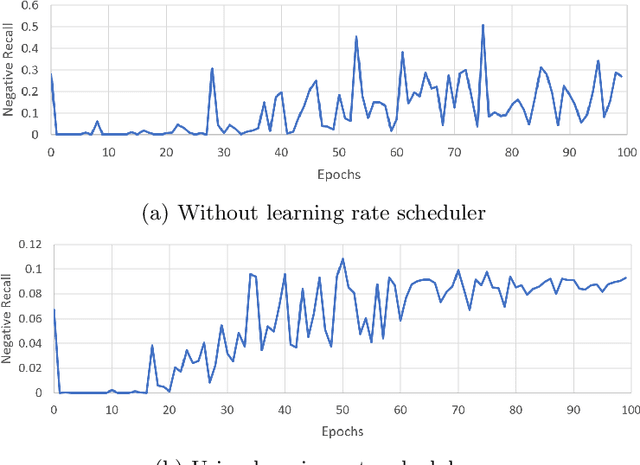
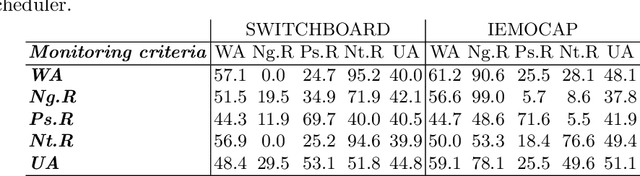
Speech is the most common way humans express their feelings, and sentiment analysis is the use of tools such as natural language processing and computational algorithms to identify the polarity of these feelings. Even though this field has seen tremendous advancements in the last two decades, the task of effectively detecting under represented sentiments in different kinds of datasets is still a challenging task. In this paper, we use single and bi-modal analysis of short dialog utterances and gain insights on the main factors that aid in sentiment detection, particularly in the underrepresented classes, in datasets with and without inherent sentiment component. Furthermore, we propose an architecture which uses a learning rate scheduler and different monitoring criteria and provides state-of-the-art results for the SWITCHBOARD imbalanced sentiment dataset.
t-Exponential Memory Networks for Question-Answering Machines
Sep 04, 2018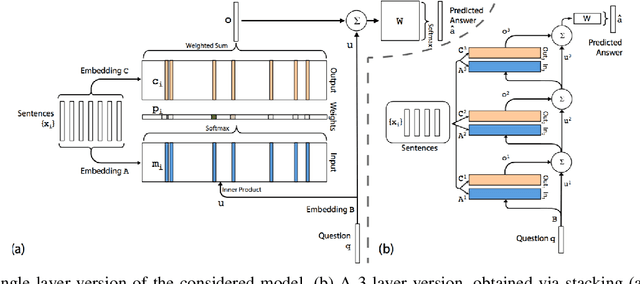
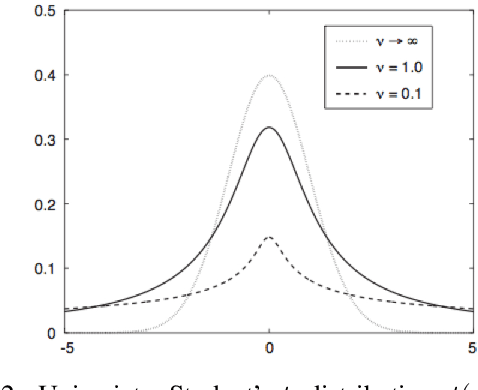
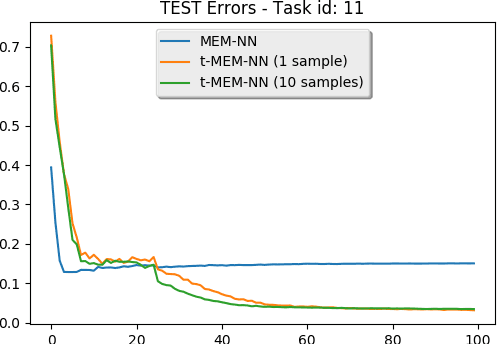

Recent advances in deep learning have brought to the fore models that can make multiple computational steps in the service of completing a task; these are capable of describ- ing long-term dependencies in sequential data. Novel recurrent attention models over possibly large external memory modules constitute the core mechanisms that enable these capabilities. Our work addresses learning subtler and more complex underlying temporal dynamics in language modeling tasks that deal with sparse sequential data. To this end, we improve upon these recent advances, by adopting concepts from the field of Bayesian statistics, namely variational inference. Our proposed approach consists in treating the network parameters as latent variables with a prior distribution imposed over them. Our statistical assumptions go beyond the standard practice of postulating Gaussian priors. Indeed, to allow for handling outliers, which are prevalent in long observed sequences of multivariate data, multivariate t-exponential distributions are imposed. On this basis, we proceed to infer corresponding posteriors; these can be used for inference and prediction at test time, in a way that accounts for the uncertainty in the available sparse training data. Specifically, to allow for our approach to best exploit the merits of the t-exponential family, our method considers a new t-divergence measure, which generalizes the concept of the Kullback-Leibler divergence. We perform an extensive experimental evaluation of our approach, using challenging language modeling benchmarks, and illustrate its superiority over existing state-of-the-art techniques.