 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaze Prediction in Virtual Reality Without Eye Tracking Using Visual and Head Motion Cues
Jan 26, 2026Gaze prediction plays a critical role in Virtual Reality (VR) applications by reducing sensor-induced latency and enabling computationally demanding techniques such as foveated rendering, which rely on anticipating user attention. However, direct eye tracking is often unavailable due to hardware limitations or privacy concerns. To address this, we present a novel gaze prediction framework that combines Head-Mounted Display (HMD) motion signals with visual saliency cues derived from video frames. Our method employs UniSal, a lightweight saliency encoder, to extract visual features, which are then fused with HMD motion data and processed through a time-series prediction module. We evaluate two lightweight architectures, TSMixer and LSTM, for forecasting future gaze directions. Experiments on the EHTask dataset, along with deployment on commercial VR hardware, show that our approach consistently outperforms baselines such as Center-of-HMD and Mean Gaze. These results demonstrate the effectiveness of predictive gaze modeling in reducing perceptual lag and enhancing natural interaction in VR environments where direct eye tracking is constrained.
PEDESTRIAN: An Egocentric Vision Dataset for Obstacle Detection on Pavements
Dec 22, 2025Walking has always been a primary mode of transportation and is recognized as an essential activity for maintaining good health. Despite the need for safe walking conditions in urban environments, sidewalks are frequently obstructed by various obstacles that hinder free pedestrian movement. Any object obstructing a pedestrian's path can pose a safety hazard. The advancement of pervasive computing and egocentric vision techniques offers the potential to design systems that can automatically detect such obstacles in real time, thereby enhancing pedestrian safety. The development of effective and efficient identification algorithms relies on the availability of comprehensive and well-balanced datasets of egocentric data. In this work, we introduce the PEDESTRIAN dataset, comprising egocentric data for 29 different obstacles commonly found on urban sidewalks. A total of 340 videos were collected using mobile phone cameras, capturing a pedestrian's point of view. Additionally, we present the results of a series of experiments that involved training several state-of-the-art deep learning algorithms using the proposed dataset, which can be used as a benchmark for obstacle detection and recognition tasks. The dataset can be used for training pavement obstacle detectors to enhance the safety of pedestrians in urban areas.
A New Dataset for End-to-End Sign Language Translation: The Greek Elementary School Dataset
Oct 07, 2023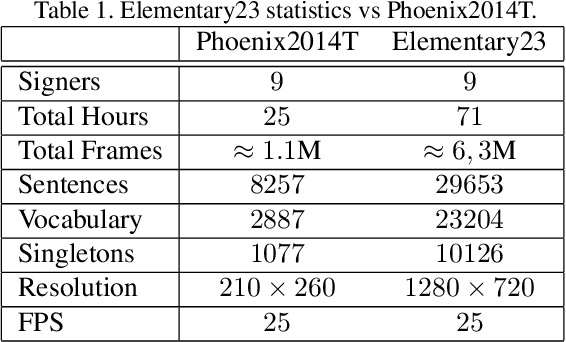

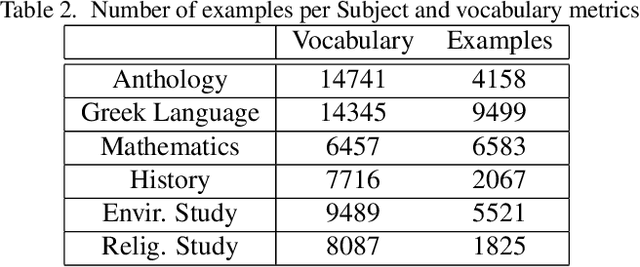
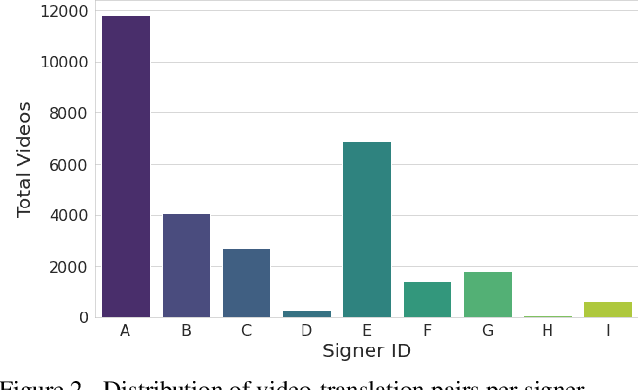
Automatic Sign Language Translation (SLT) is a research avenue of great societal impact. End-to-End SLT facilitates the interaction of Hard-of-Hearing (HoH) with hearing people, thus improving their social life and opportunities for participation in social life. However, research within this frame of reference is still in its infancy, and current resources are particularly limited. Existing SLT methods are either of low translation ability or are trained and evaluated on datasets of restricted vocabulary and questionable real-world value. A characteristic example is Phoenix2014T benchmark dataset, which only covers weather forecasts in German Sign Language. To address this shortage of resources, we introduce a newly constructed collection of 29653 Greek Sign Language video-translation pairs which is based on the official syllabus of Greek Elementary School. Our dataset covers a wide range of subjects. We use this novel dataset to train recent state-of-the-art Transformer-based methods widely used in SLT research. Our results demonstrate the potential of our introduced dataset to advance SLT research by offering a favourable balance between usability and real-world value.
* ICCVW2023 - ACVR
Variational Bayesian Sequence-to-Sequence Networks for Memory-Efficient Sign Language Translation
Feb 11, 2021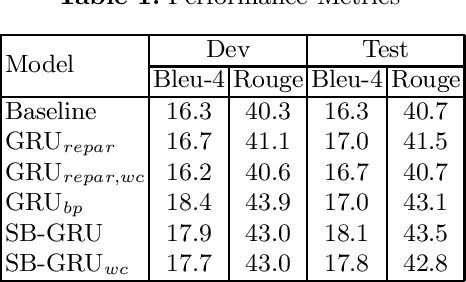
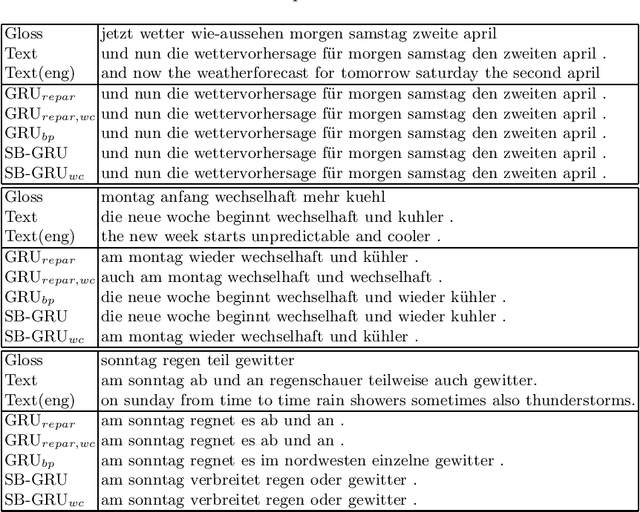
Memory-efficient continuous Sign Language Translation is a significant challenge for the development of assisted technologies with real-time applicability for the deaf. In this work, we introduce a paradigm of designing recurrent deep networks whereby the output of the recurrent layer is derived from appropriate arguments from nonparametric statistics. A novel variational Bayesian sequence-to-sequence network architecture is proposed that consists of a) a full Gaussian posterior distribution for data-driven memory compression and b) a nonparametric Indian Buffet Process prior for regularization applied on the Gated Recurrent Unit non-gate weights. We dub our approach Stick-Breaking Recurrent network and show that it can achieve a substantial weight compression without diminishing modeling performance.
A Self-Attentive Emotion Recognition Network
Apr 24, 2019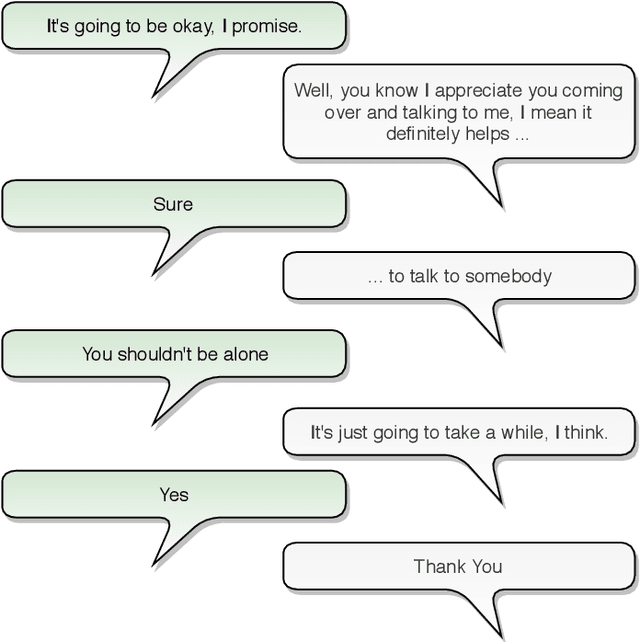

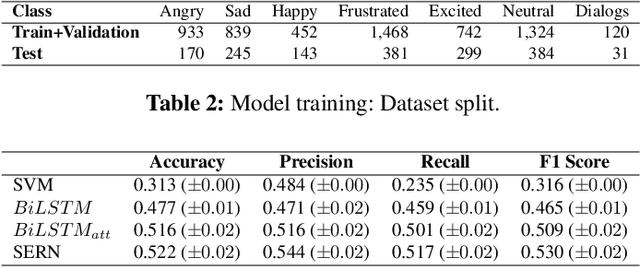
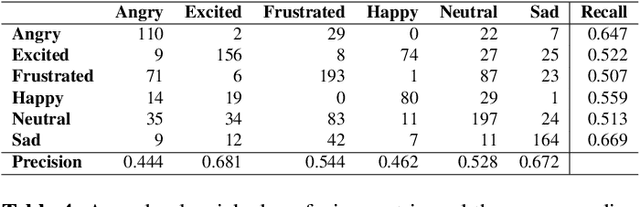
Modern deep learning approaches have achieved groundbreaking performance in modeling and classifying sequential data. Specifically, attention networks constitute the state-of-the-art paradigm for capturing long temporal dynamics. This paper examines the efficacy of this paradigm in the challenging task of emotion recognition in dyadic conversations. In contrast to existing approaches, our work introduces a novel attention mechanism capable of inferring the immensity of the effect of each past utterance on the current speaker emotional state. The proposed attention mechanism performs this inference procedure without the need of a decoder network; this is achieved by means of innovative self-attention arguments. Our self-attention networks capture the correlation patterns among consecutive encoder network states, thus allowing to robustly and effectively model temporal dynamics over arbitrary long temporal horizons. Thus, we enable capturing strong affective patterns over the course of long discussions. We exhibit the effectiveness of our approach considering the challenging IEMOCAP benchmark. As we show, our devised methodology outperforms state-of-the-art alternatives and commonly used approaches, giving rise to promising new research directions in the context of Online Social Network (OSN) analysis tasks.
Deep Network Regularization via Bayesian Inference of Synaptic Connectivity
Mar 04, 2018

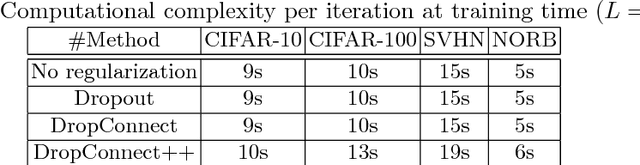
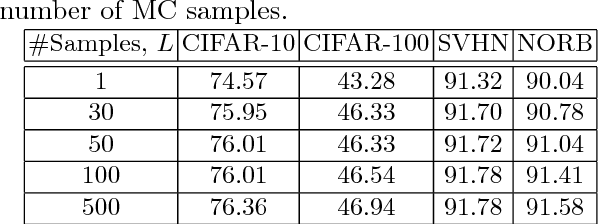
Deep neural networks (DNNs) often require good regularizers to generalize well. Currently, state-of-the-art DNN regularization techniques consist in randomly dropping units and/or connections on each iteration of the training algorithm. Dropout and DropConnect are characteristic examples of such regularizers, that are widely popular among practitioners. However, a drawback of such approaches consists in the fact that their postulated probability of random unit/connection omission is a constant that must be heuristically selected based on the obtained performance in some validation set. To alleviate this burden, in this paper we regard the DNN regularization problem from a Bayesian inference perspective: We impose a sparsity-inducing prior over the network synaptic weights, where the sparsity is induced by a set of Bernoulli-distributed binary variables with Beta (hyper-)priors over their prior parameters. This way, we eventually allow for marginalizing over the DNN synaptic connectivity for output generation, thus giving rise to an effective, heuristics-free, network regularization scheme. We perform Bayesian inference for the resulting hierarchical model by means of an efficient Black-Box Variational inference scheme. We exhibit the advantages of our method over existing approaches by conducting an extensive experimental evaluation using benchmark datasets.
Deep learning with t-exponential Bayesian kitchen sinks
Feb 10, 2018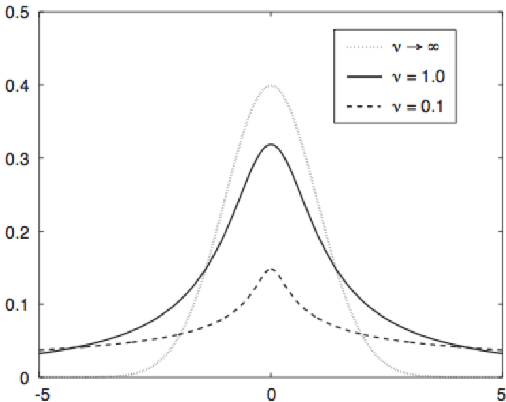
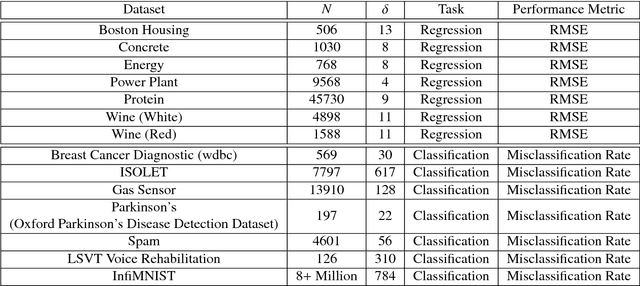
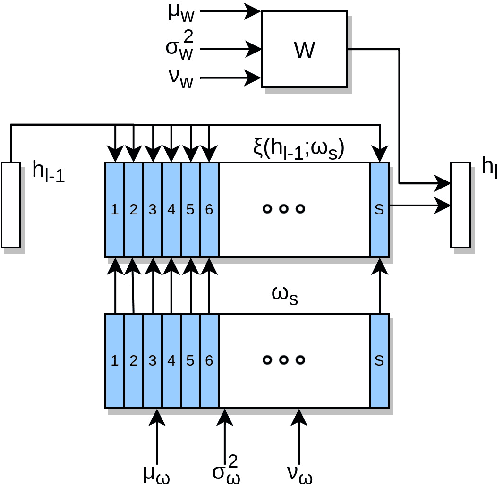
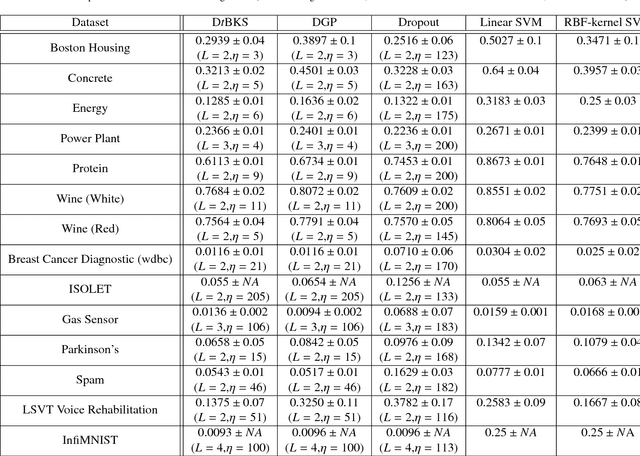
Bayesian learning has been recently considered as an effective means of accounting for uncertainty in trained deep network parameters. This is of crucial importance when dealing with small or sparse training datasets. On the other hand, shallow models that compute weighted sums of their inputs, after passing them through a bank of arbitrary randomized nonlinearities, have been recently shown to enjoy good test error bounds that depend on the number of nonlinearities. Inspired from these advances, in this paper we examine novel deep network architectures, where each layer comprises a bank of arbitrary nonlinearities, linearly combined using multiple alternative sets of weights. We effect model training by means of approximate inference based on a t-divergence measure; this generalizes the Kullback-Leibler divergence in the context of the t-exponential family of distributions. We adopt the t-exponential family since it can more flexibly accommodate real-world data, that entail outliers and distributions with fat tails, compared to conventional Gaussian model assumptions. We extensively evaluate our approach using several challenging benchmarks, and provide comparative results to related state-of-the-art techniques.