 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Bayesian Sequence-to-Sequence Networks for Memory-Efficient Sign Language Translation
Paper and Code
Feb 11, 2021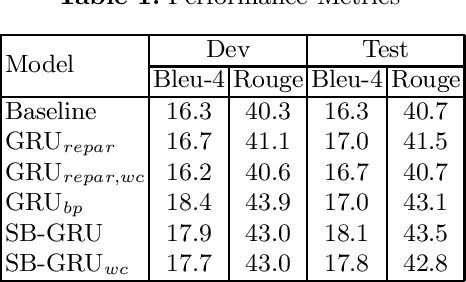
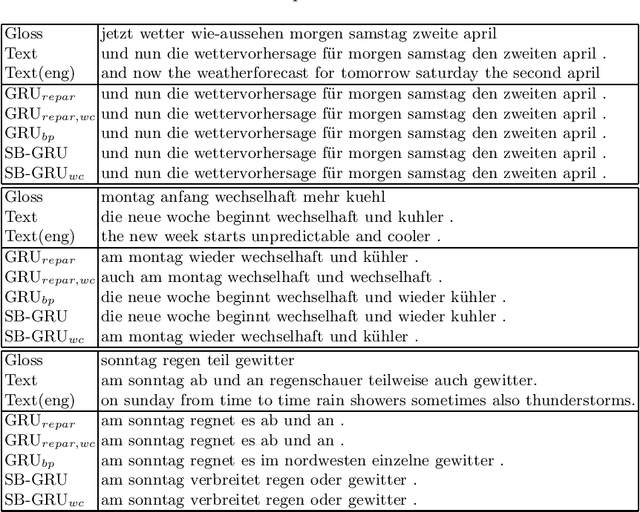
Memory-efficient continuous Sign Language Translation is a significant challenge for the development of assisted technologies with real-time applicability for the deaf. In this work, we introduce a paradigm of designing recurrent deep networks whereby the output of the recurrent layer is derived from appropriate arguments from nonparametric statistics. A novel variational Bayesian sequence-to-sequence network architecture is proposed that consists of a) a full Gaussian posterior distribution for data-driven memory compression and b) a nonparametric Indian Buffet Process prior for regularization applied on the Gated Recurrent Unit non-gate weights. We dub our approach Stick-Breaking Recurrent network and show that it can achieve a substantial weight compression without diminishing modeling performance.