 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA cross-domain recommender system using deep coupled autoencoders
Dec 08, 2021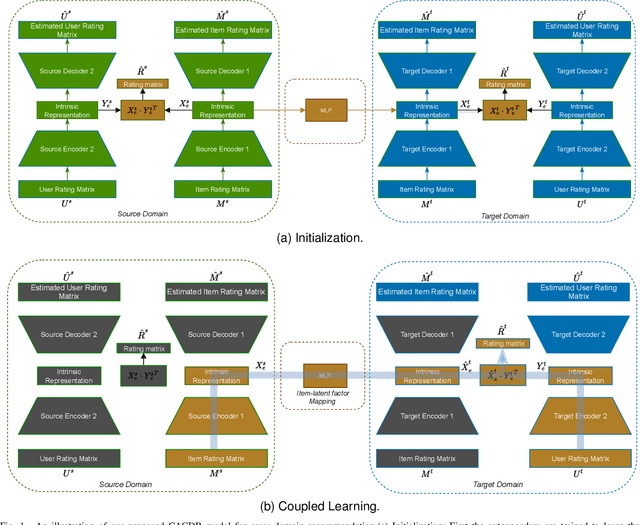
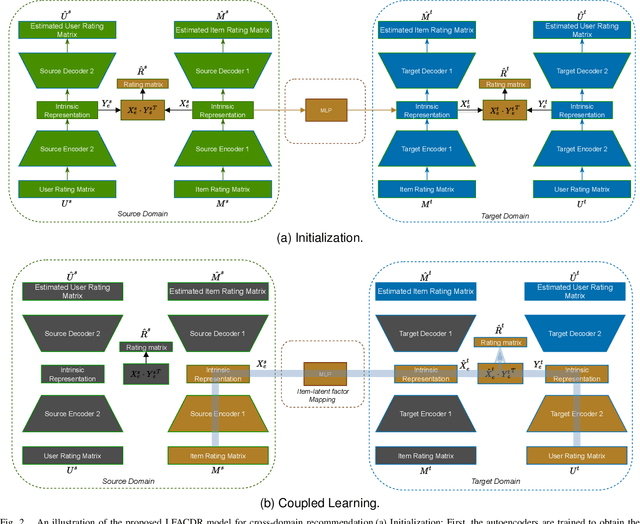
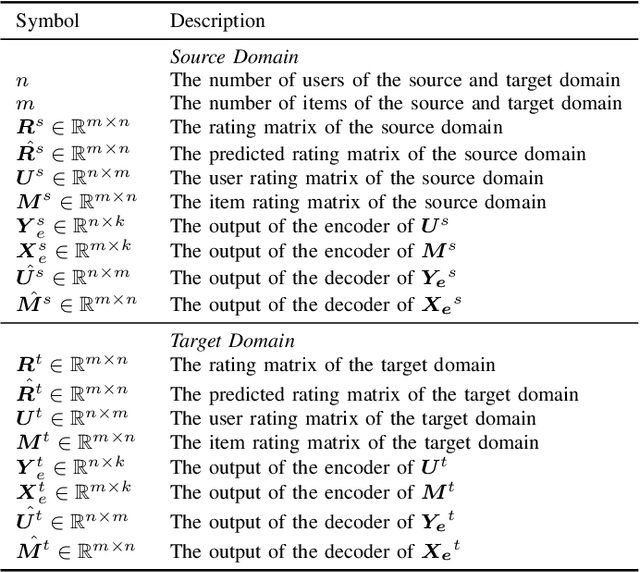
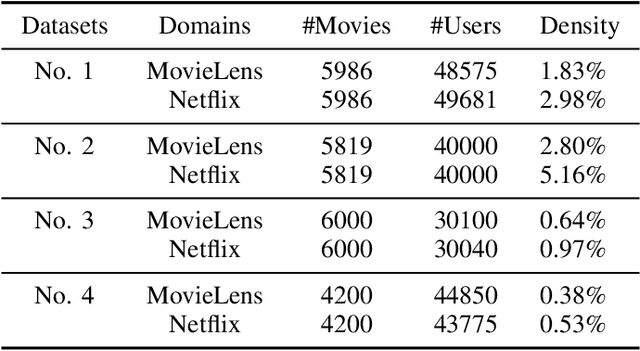
Long-standing data sparsity and cold-start constitute thorny and perplexing problems for the recommendation systems. Cross-domain recommendation as a domain adaptation framework has been utilized to efficiently address these challenging issues, by exploiting information from multiple domains. In this study, an item-level relevance cross-domain recommendation task is explored, where two related domains, that is, the source and the target domain contain common items without sharing sensitive information regarding the users' behavior, and thus avoiding the leak of user privacy. In light of this scenario, two novel coupled autoencoder-based deep learning methods are proposed for cross-domain recommendation. The first method aims to simultaneously learn a pair of autoencoders in order to reveal the intrinsic representations of the items in the source and target domains, along with a coupled mapping function to model the non-linear relationships between these representations, thus transferring beneficial information from the source to the target domain. The second method is derived based on a new joint regularized optimization problem, which employs two autoencoders to generate in a deep and non-linear manner the user and item-latent factors, while at the same time a data-driven function is learnt to map the item-latent factors across domains. Extensive numerical experiments on two publicly available benchmark datasets are conducted illustrating the superior performance of our proposed methods compared to several state-of-the-art cross-domain recommendation frameworks.
Stochastic Transformer Networks with Linear Competing Units: Application to end-to-end SL Translation
Oct 01, 2021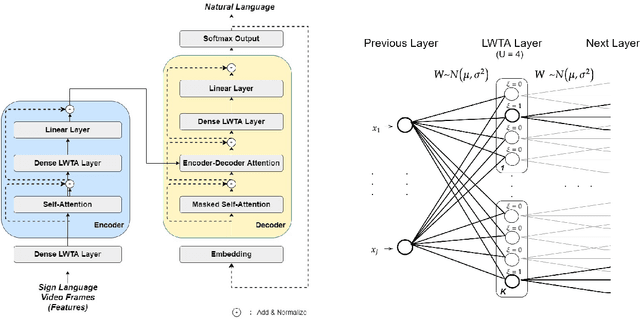
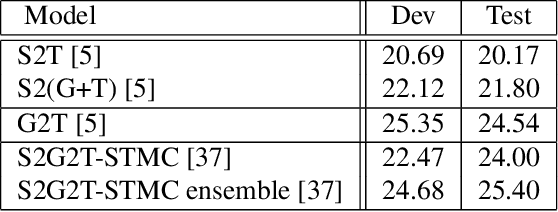


Automating sign language translation (SLT) is a challenging real world application. Despite its societal importance, though, research progress in the field remains rather poor. Crucially, existing methods that yield viable performance necessitate the availability of laborious to obtain gloss sequence groundtruth. In this paper, we attenuate this need, by introducing an end-to-end SLT model that does not entail explicit use of glosses; the model only needs text groundtruth. This is in stark contrast to existing end-to-end models that use gloss sequence groundtruth, either in the form of a modality that is recognized at an intermediate model stage, or in the form of a parallel output process, jointly trained with the SLT model. Our approach constitutes a Transformer network with a novel type of layers that combines: (i) local winner-takes-all (LWTA) layers with stochastic winner sampling, instead of conventional ReLU layers, (ii) stochastic weights with posterior distributions estimated via variational inference, and (iii) a weight compression technique at inference time that exploits estimated posterior variance to perform massive, almost lossless compression. We demonstrate that our approach can reach the currently best reported BLEU-4 score on the PHOENIX 2014T benchmark, but without making use of glosses for model training, and with a memory footprint reduced by more than 70%.
Variational Bayesian Sequence-to-Sequence Networks for Memory-Efficient Sign Language Translation
Feb 11, 2021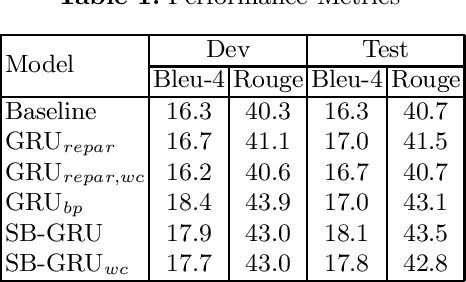
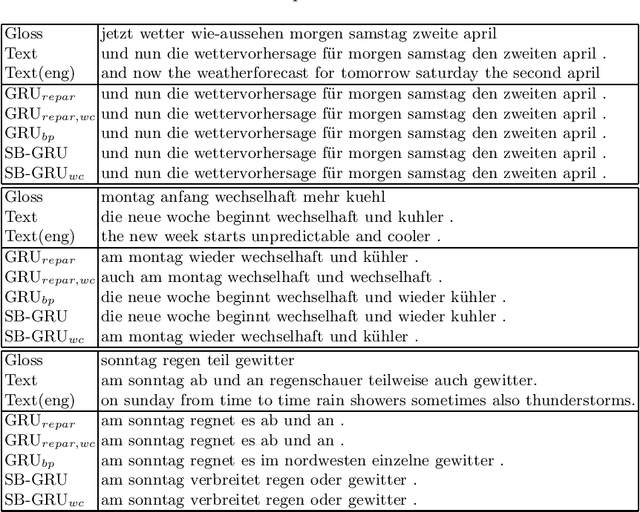
Memory-efficient continuous Sign Language Translation is a significant challenge for the development of assisted technologies with real-time applicability for the deaf. In this work, we introduce a paradigm of designing recurrent deep networks whereby the output of the recurrent layer is derived from appropriate arguments from nonparametric statistics. A novel variational Bayesian sequence-to-sequence network architecture is proposed that consists of a) a full Gaussian posterior distribution for data-driven memory compression and b) a nonparametric Indian Buffet Process prior for regularization applied on the Gated Recurrent Unit non-gate weights. We dub our approach Stick-Breaking Recurrent network and show that it can achieve a substantial weight compression without diminishing modeling performance.