 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibriVAD: A Scalable Open Dataset with Deep Learning Benchmarks for Voice Activity Detection
Dec 19, 2025Robust Voice Activity Detection (VAD) remains a challenging task, especially under noisy, diverse, and unseen acoustic conditions. Beyond algorithmic development, a key limitation in advancing VAD research is the lack of large-scale, systematically controlled, and publicly available datasets. To address this, we introduce LibriVAD - a scalable open-source dataset derived from LibriSpeech and augmented with diverse real-world and synthetic noise sources. LibriVAD enables systematic control over speech-to-noise ratio, silence-to-speech ratio (SSR), and noise diversity, and is released in three sizes (15 GB, 150 GB, and 1.5 TB) with two variants (LibriVAD-NonConcat and LibriVAD-Concat) to support different experimental setups. We benchmark multiple feature-model combinations, including waveform, Mel-Frequency Cepstral Coefficients (MFCC), and Gammatone filter bank cepstral coefficients, and introduce the Vision Transformer (ViT) architecture for VAD. Our experiments show that ViT with MFCC features consistently outperforms established VAD models such as boosted deep neural network and convolutional long short-term memory deep neural network across seen, unseen, and out-of-distribution (OOD) conditions, including evaluation on the real-world VOiCES dataset. We further analyze the impact of dataset size and SSR on model generalization, experimentally showing that scaling up dataset size and balancing SSR noticeably and consistently enhance VAD performance under OOD conditions. All datasets, trained models, and code are publicly released to foster reproducibility and accelerate progress in VAD research.
Vocal Tract Length Warped Features for Spoken Keyword Spotting
Jan 07, 2025In this paper, we propose several methods that incorporate vocal tract length (VTL) warped features for spoken keyword spotting (KWS). The first method, VTL-independent KWS, involves training a single deep neural network (DNN) that utilizes VTL features with various warping factors. During training, a specific VTL feature is randomly selected per epoch, allowing the exploration of VTL variations. During testing, the VTL features with different warping factors of a test utterance are scored against the DNN and combined with equal weight. In the second method scores the conventional features of a test utterance (without VTL warping) against the DNN. The third method, VTL-concatenation KWS, concatenates VTL warped features to form high-dimensional features for KWS. Evaluations carried out on the English Google Command dataset demonstrate that the proposed methods improve the accuracy of KWS.
On Training Targets and Activation Functions for Deep Representation Learning in Text-Dependent Speaker Verification
Jan 17, 2022Deep representation learning has gained significant momentum in advancing text-dependent speaker verification (TD-SV) systems. When designing deep neural networks (DNN) for extracting bottleneck features, key considerations include training targets, activation functions, and loss functions. In this paper, we systematically study the impact of these choices on the performance of TD-SV. For training targets, we consider speaker identity, time-contrastive learning (TCL) and auto-regressive prediction coding with the first being supervised and the last two being self-supervised. Furthermore, we study a range of loss functions when speaker identity is used as the training target. With regard to activation functions, we study the widely used sigmoid function, rectified linear unit (ReLU), and Gaussian error linear unit (GELU). We experimentally show that GELU is able to reduce the error rates of TD-SV significantly compared to sigmoid, irrespective of training target. Among the three training targets, TCL performs the best. Among the various loss functions, cross entropy, joint-softmax and focal loss functions outperform the others. Finally, score-level fusion of different systems is also able to reduce the error rates. Experiments are conducted on the RedDots 2016 challenge database for TD-SV using short utterances. For the speaker classifications, the well-known Gaussian mixture model-universal background model (GMM-UBM) and i-vector techniques are used.
Vocal Tract Length Perturbation for Text-Dependent Speaker Verification with Autoregressive Prediction Coding
Nov 25, 2020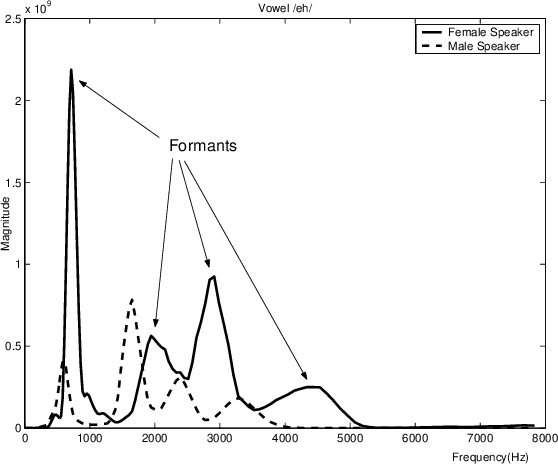
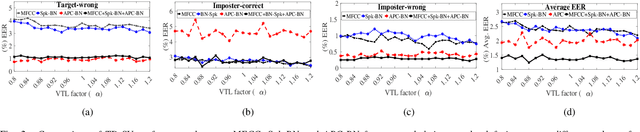

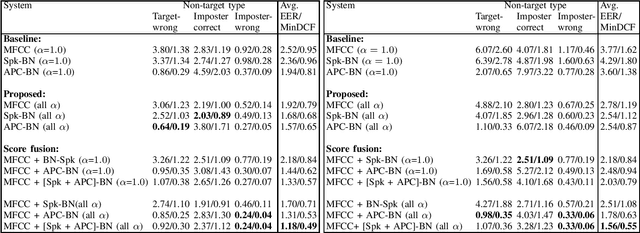
In this letter, we propose a vocal tract length (VTL) perturbation method for text-dependent speaker verification (TD-SV), in which a set of TD-SV systems are trained, one for each VTL factor, and score-level fusion is applied to make a final decision. Next, we explore the bottleneck (BN) feature extracted by training deep neural networks with a self-supervised objective, autoregressive predictive coding (APC), for TD-SV and compare it with the well-studied speaker-discriminant BN feature. The proposed VTL method is then applied to APC and speaker-discriminant BN features. In the end, we combine the VTL perturbation systems trained on MFCC and the two BN features in the score domain. Experiments are performed on the RedDots challenge 2016 database of TD-SV using short utterances with Gaussian mixture model-universal background model and i-vector techniques. Results show the proposed methods significantly outperform the baselines.
rVAD: An Unsupervised Segment-Based Robust Voice Activity Detection Method
Jun 09, 2019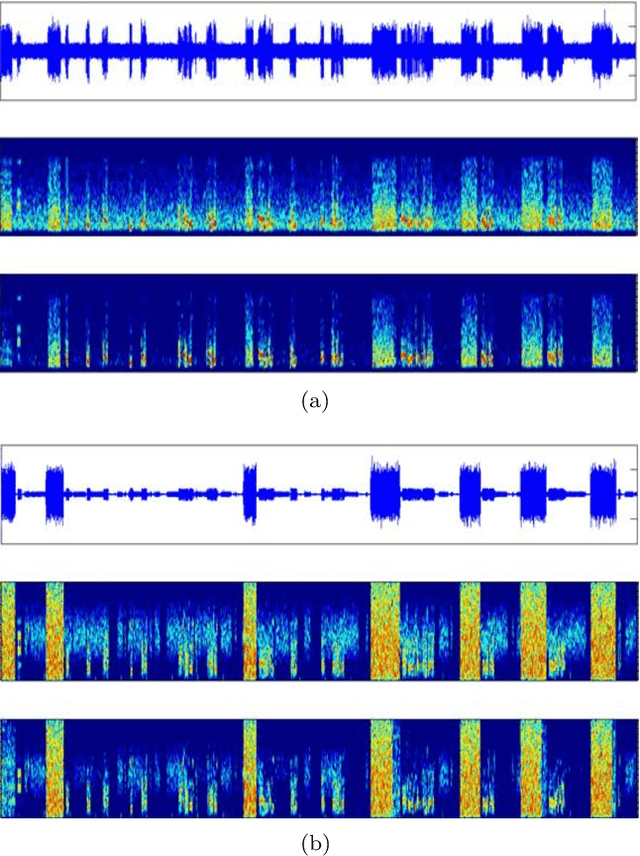
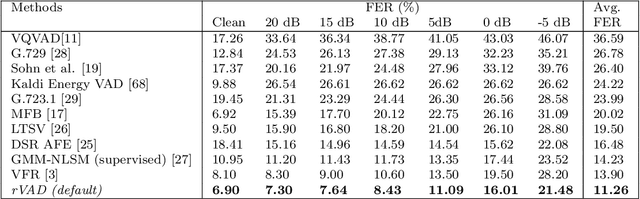
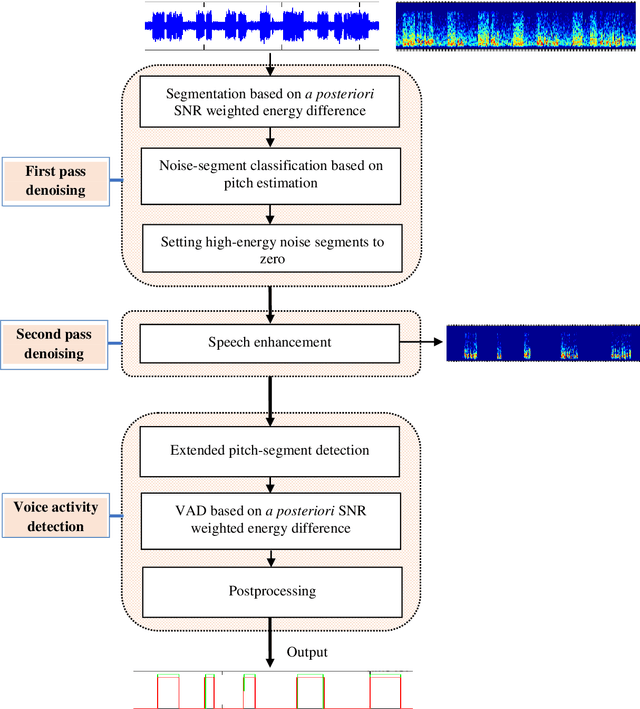
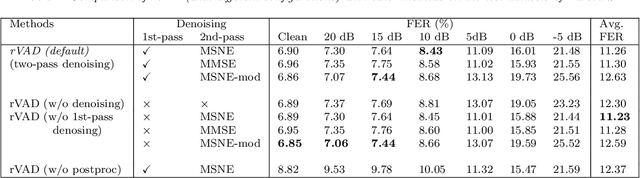
This paper presents an unsupervised segment-based method for robust voice activity detection (rVAD). The method consists of two passes of denoising followed by a voice activity detection (VAD) stage. In the first pass, high-energy segments in a speech signal are detected by using a posteriori signal-to-noise ratio (SNR) weighted energy difference and if no pitch is detected within a segment, the segment is considered as a high-energy noise segment and set to zero. In the second pass, the speech signal is denoised by a speech enhancement method, for which several methods are explored. Next, neighbouring frames with pitch are grouped together to form pitch segments, and based on speech statistics, the pitch segments are further extended from both ends in order to include both voiced and unvoiced sounds and likely non-speech parts as well. In the end, a posteriori SNR weighted energy difference is applied to the extended pitch segments of the denoised speech signal for detecting voice activity. We evaluate the VAD performance of the proposed method using two databases, RATS and Aurora-2, which contain a large variety of noise conditions. The rVAD method is further evaluated, in terms of speaker verification performance, on the RedDots 2016 challenge database and its noise-corrupted versions. Experiment results show that rVAD is compared favourably with a number of existing methods. In addition, we present a modified version of rVAD where computationally intensive pitch extraction is replaced by computationally efficient spectral flatness calculation. The modified version significantly reduces the computational complexity at the cost of moderately inferior VAD performance, which is an advantage when processing a large amount of data and running on low resource devices. The source code of rVAD is made publicly available.
* Paper is to appear in CSL
Time-Contrastive Learning Based Deep Bottleneck Features for Text-Dependent Speaker Verification
May 11, 2019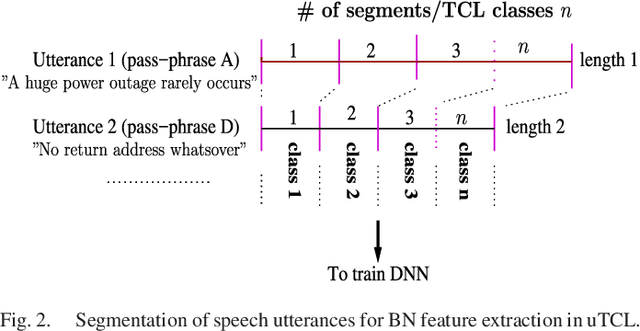
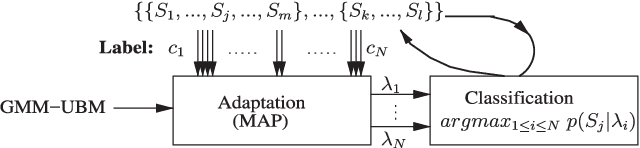
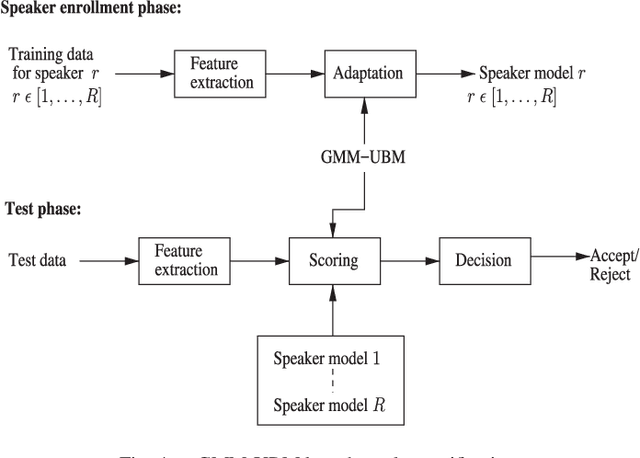
There are a number of studies about extraction of bottleneck (BN) features from deep neural networks (DNNs)trained to discriminate speakers, pass-phrases and triphone states for improving the performance of text-dependent speaker verification (TD-SV). However, a moderate success has been achieved. A recent study [1] presented a time contrastive learning (TCL) concept to explore the non-stationarity of brain signals for classification of brain states. Speech signals have similar non-stationarity property, and TCL further has the advantage of having no need for labeled data. We therefore present a TCL based BN feature extraction method. The method uniformly partitions each speech utterance in a training dataset into a predefined number of multi-frame segments. Each segment in an utterance corresponds to one class, and class labels are shared across utterances. DNNs are then trained to discriminate all speech frames among the classes to exploit the temporal structure of speech. In addition, we propose a segment-based unsupervised clustering algorithm to re-assign class labels to the segments. TD-SV experiments were conducted on the RedDots challenge database. The TCL-DNNs were trained using speech data of fixed pass-phrases that were excluded from the TD-SV evaluation set, so the learned features can be considered phrase-independent. We compare the performance of the proposed TCL bottleneck (BN) feature with those of short-time cepstral features and BN features extracted from DNNs discriminating speakers, pass-phrases, speaker+pass-phrase, as well as monophones whose labels and boundaries are generated by three different automatic speech recognition (ASR) systems. Experimental results show that the proposed TCL-BN outperforms cepstral features and speaker+pass-phrase discriminant BN features, and its performance is on par with those of ASR derived BN features. Moreover,....
* Copyright (c) 2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works