 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation into Target Speaking Rate Adaptation for Voice Conversion
Paper and Code
Sep 05, 2022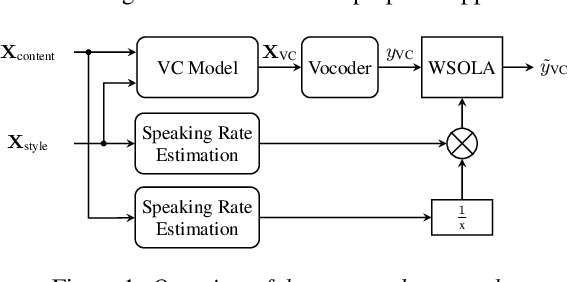

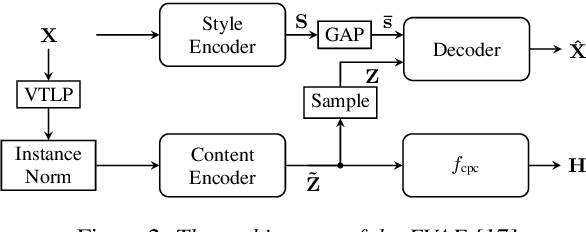
Disentangling speaker and content attributes of a speech signal into separate latent representations followed by decoding the content with an exchanged speaker representation is a popular approach for voice conversion, which can be trained with non-parallel and unlabeled speech data. However, previous approaches perform disentanglement only implicitly via some sort of information bottleneck or normalization, where it is usually hard to find a good trade-off between voice conversion and content reconstruction. Further, previous works usually do not consider an adaptation of the speaking rate to the target speaker or they put some major restrictions to the data or use case. Therefore, the contribution of this work is two-fold. First, we employ an explicit and fully unsupervised disentanglement approach, which has previously only been used for representation learning, and show that it allows to obtain both superior voice conversion and content reconstruction. Second, we investigate simple and generic approaches to linearly adapt the length of a speech signal, and hence the speaking rate, to a target speaker and show that the proposed adaptation allows to increase the speaking rate similarity with respect to the target speaker.