 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescribing emotions with acoustic property prompts for speech emotion recognition
Paper and Code
Nov 14, 2022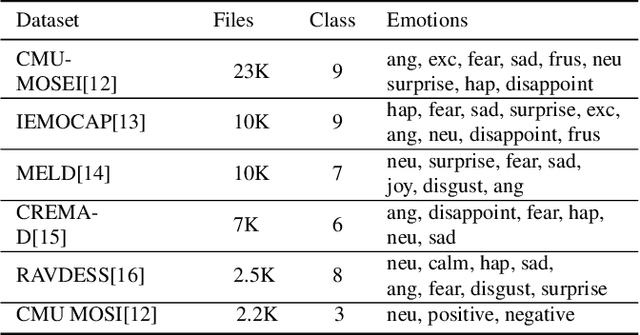
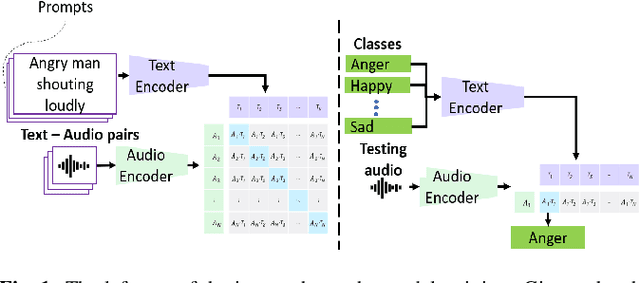
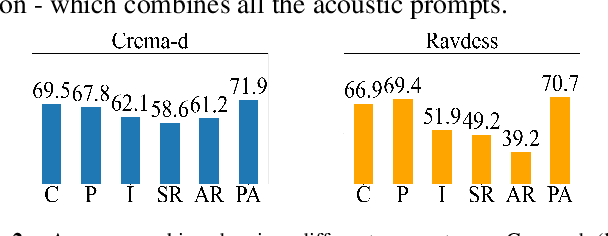
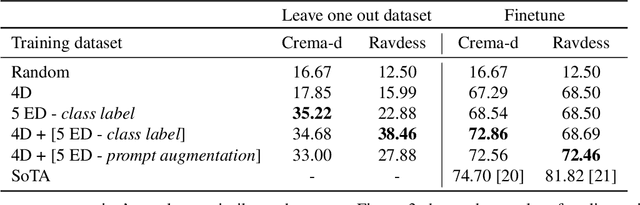
Emotions lie on a broad continuum and treating emotions as a discrete number of classes limits the ability of a model to capture the nuances in the continuum. The challenge is how to describe the nuances of emotions and how to enable a model to learn the descriptions. In this work, we devise a method to automatically create a description (or prompt) for a given audio by computing acoustic properties, such as pitch, loudness, speech rate, and articulation rate. We pair a prompt with its corresponding audio using 5 different emotion datasets. We trained a neural network model using these audio-text pairs. Then, we evaluate the model using one more dataset. We investigate how the model can learn to associate the audio with the descriptions, resulting in performance improvement of Speech Emotion Recognition and Speech Audio Retrieval. We expect our findings to motivate research describing the broad continuum of emotion