 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective Measurements of Voice Quality
Paper and Code
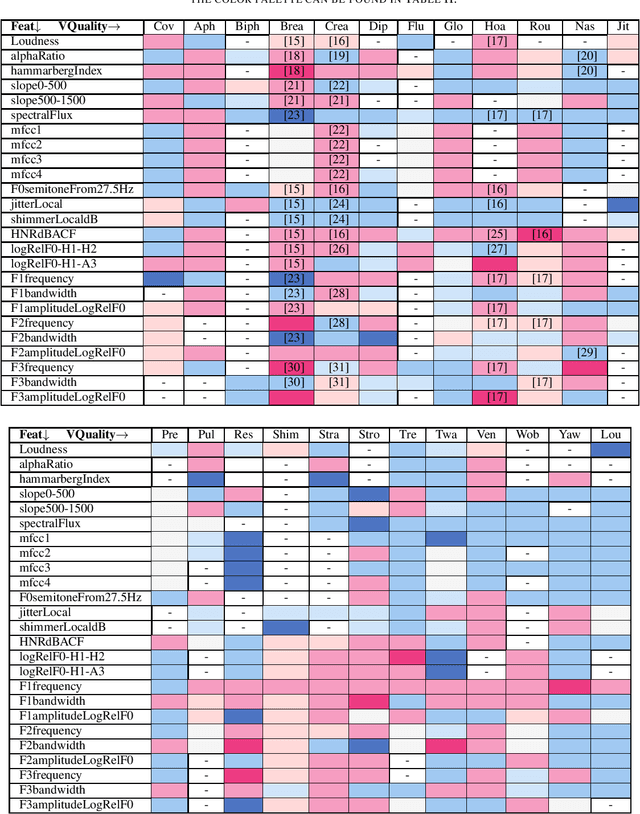
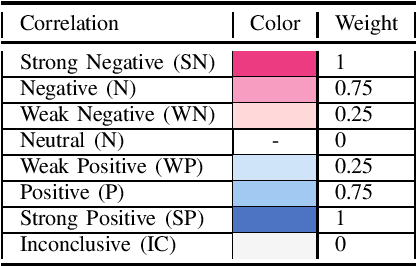
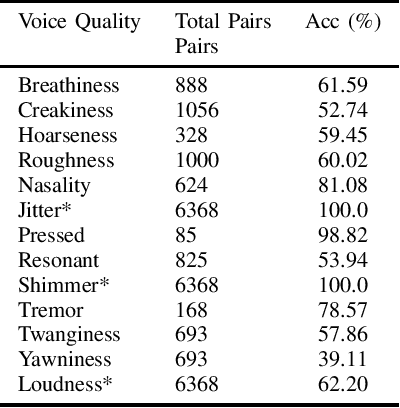
The quality of human voice plays an important role across various fields like music, speech therapy, and communication, yet it lacks a universally accepted, objective definition. Instead, voice quality is referred to using subjective descriptors like "rough", "breathy" etc. Despite this subjectivity, extensive research across disciplines has linked these voice qualities to specific information about the speaker, such as health, physiological traits, and others. Current machine learning approaches for voice profiling rely on data-driven analysis without fully incorporating these established correlations, due to their qualitative nature. This paper aims to objectively quantify voice quality by synthesizing formulaic representations from past findings that correlate voice qualities to signal-processing metrics. We introduce formulae for 24 voice sub-qualities based on 25 signal properties, grounded in scientific literature. These formulae are tested against datasets with subjectively labeled voice qualities, demonstrating their validity.