 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerLM: Explaining Face Verification Using Natural Language
Jan 05, 2026Face verification systems have seen substantial advancements; however, they often lack transparency in their decision-making processes. In this paper, we introduce an innovative Vision-Language Model (VLM) for Face Verification, which not only accurately determines if two face images depict the same individual but also explicitly explains the rationale behind its decisions. Our model is uniquely trained using two complementary explanation styles: (1) concise explanations that summarize the key factors influencing its decision, and (2) comprehensive explanations detailing the specific differences observed between the images. We adapt and enhance a state-of-the-art modeling approach originally designed for audio-based differentiation to suit visual inputs effectively. This cross-modal transfer significantly improves our model's accuracy and interpretability. The proposed VLM integrates sophisticated feature extraction techniques with advanced reasoning capabilities, enabling clear articulation of its verification process. Our approach demonstrates superior performance, surpassing baseline methods and existing models. These findings highlight the immense potential of vision language models in face verification set up, contributing to more transparent, reliable, and explainable face verification systems.
Audio Entailment: Assessing Deductive Reasoning for Audio Understanding
Jul 25, 2024Recent literature uses language to build foundation models for audio. These Audio-Language Models (ALMs) are trained on a vast number of audio-text pairs and show remarkable performance in tasks including Text-to-Audio Retrieval, Captioning, and Question Answering. However, their ability to engage in more complex open-ended tasks, like Interactive Question-Answering, requires proficiency in logical reasoning -- a skill not yet benchmarked. We introduce the novel task of Audio Entailment to evaluate an ALM's deductive reasoning ability. This task assesses whether a text description (hypothesis) of audio content can be deduced from an audio recording (premise), with potential conclusions being entailment, neutral, or contradiction, depending on the sufficiency of the evidence. We create two datasets for this task with audio recordings sourced from two audio captioning datasets -- AudioCaps and Clotho -- and hypotheses generated using Large Language Models (LLMs). We benchmark state-of-the-art ALMs and find deficiencies in logical reasoning with both zero-shot and linear probe evaluations. Finally, we propose "caption-before-reason", an intermediate step of captioning that improves the zero-shot and linear-probe performance of ALMs by an absolute 6% and 3%, respectively.
SELM: Enhancing Speech Emotion Recognition for Out-of-Domain Scenarios
Jul 22, 2024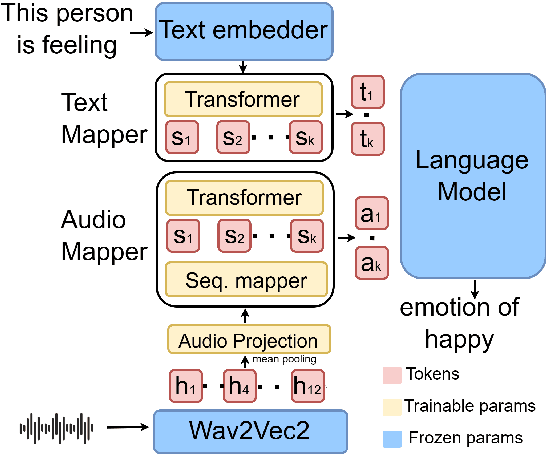
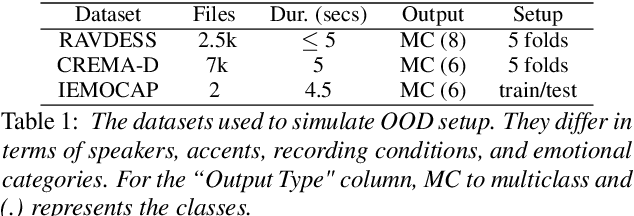

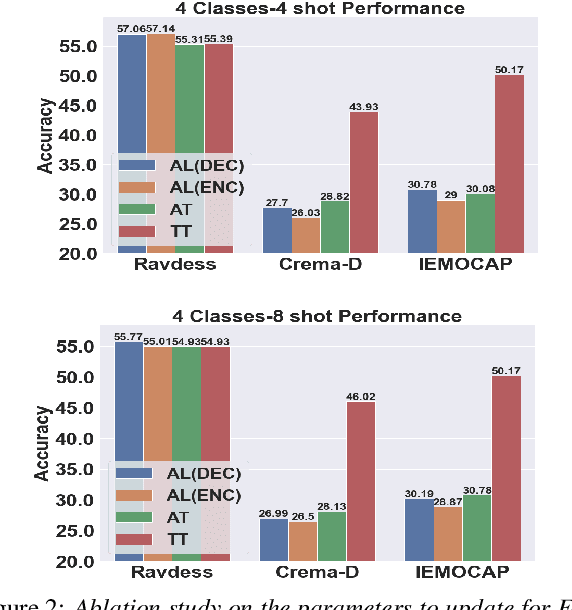
Speech Emotion Recognition (SER) has been traditionally formulated as a classification task. However, emotions are generally a spectrum whose distribution varies from situation to situation leading to poor Out-of-Domain (OOD) performance. We take inspiration from statistical formulation of Automatic Speech Recognition (ASR) and formulate the SER task as generating the most likely sequence of text tokens to infer emotion. The formulation breaks SER into predicting acoustic model features weighted by language model prediction. As an instance of this approach, we present SELM, an audio-conditioned language model for SER that predicts different emotion views. We train SELM on curated speech emotion corpus and test it on three OOD datasets (RAVDESS, CREMAD, IEMOCAP) not used in training. SELM achieves significant improvements over the state-of-the-art baselines, with 17% and 7% relative accuracy gains for RAVDESS and CREMA-D, respectively. Moreover, SELM can further boost its performance by Few-Shot Learning using a few annotated examples. The results highlight the effectiveness of our SER formulation, especially to improve performance in OOD scenarios.