 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying the Discrete and Continuous Emotion labels for Speech Emotion Recognition
Paper and Code
Oct 29, 2022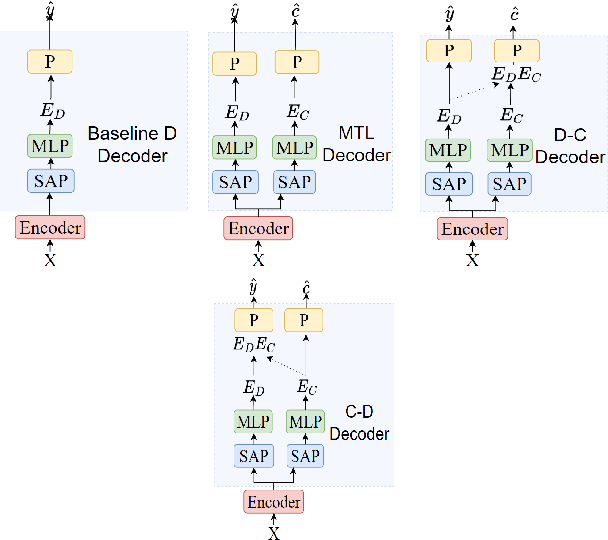
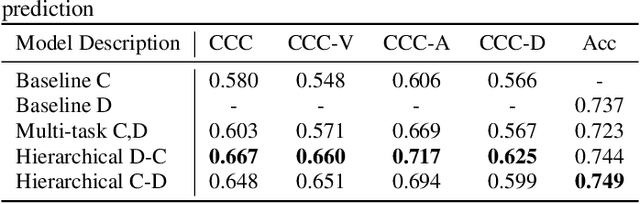
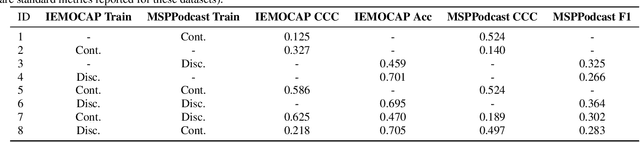
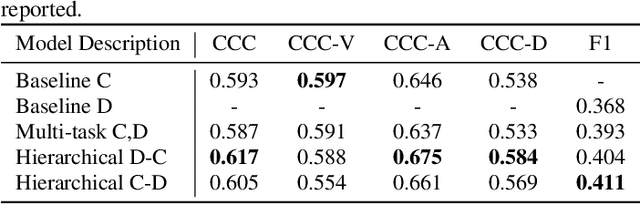
Traditionally, in paralinguistic analysis for emotion detection from speech, emotions have been identified with discrete or dimensional (continuous-valued) labels. Accordingly, models that have been proposed for emotion detection use one or the other of these label types. However, psychologists like Russell and Plutchik have proposed theories and models that unite these views, maintaining that these representations have shared and complementary information. This paper is an attempt to validate these viewpoints computationally. To this end, we propose a model to jointly predict continuous and discrete emotional attributes and show how the relationship between these can be utilized to improve the robustness and performance of emotion recognition tasks. Our approach comprises multi-task and hierarchical multi-task learning frameworks that jointly model the relationships between continuous-valued and discrete emotion labels. Experimental results on two widely used datasets (IEMOCAP and MSPPodcast) for speech-based emotion recognition show that our model results in statistically significant improvements in performance over strong baselines with non-unified approaches. We also demonstrate that using one type of label (discrete or continuous-valued) for training improves recognition performance in tasks that use the other type of label. Experimental results and reasoning for this approach (called the mismatched training approach) are also presented.