 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Audios Using Acoustic Properties For Emotion Representation
Paper and Code
Oct 05, 2023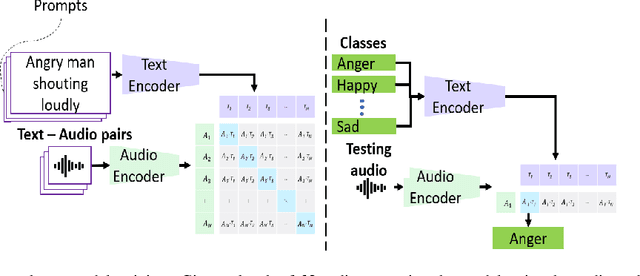
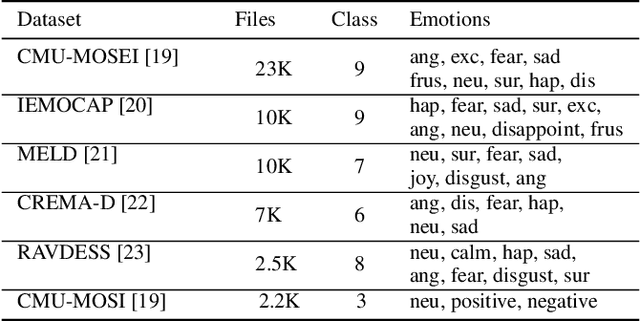
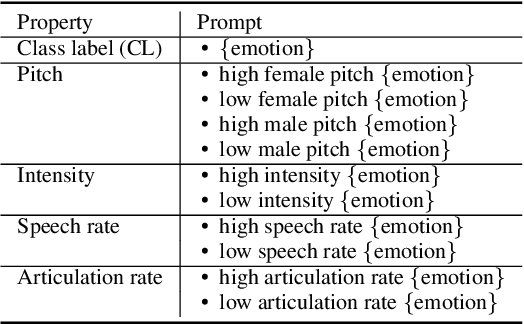
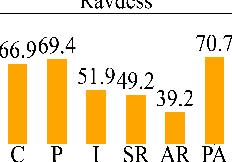
Emotions lie on a continuum, but current models treat emotions as a finite valued discrete variable. This representation does not capture the diversity in the expression of emotion. To better represent emotions we propose the use of natural language descriptions (or prompts). In this work, we address the challenge of automatically generating these prompts and training a model to better learn emotion representations from audio and prompt pairs. We use acoustic properties that are correlated to emotion like pitch, intensity, speech rate, and articulation rate to automatically generate prompts i.e. 'acoustic prompts'. We use a contrastive learning objective to map speech to their respective acoustic prompts. We evaluate our model on Emotion Audio Retrieval and Speech Emotion Recognition. Our results show that the acoustic prompts significantly improve the model's performance in EAR, in various Precision@K metrics. In SER, we observe a 3.8% relative accuracy improvement on the Ravdess dataset.