 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACE: Leveraging Audio for Evaluating Audio Captioning Systems
Paper and Code
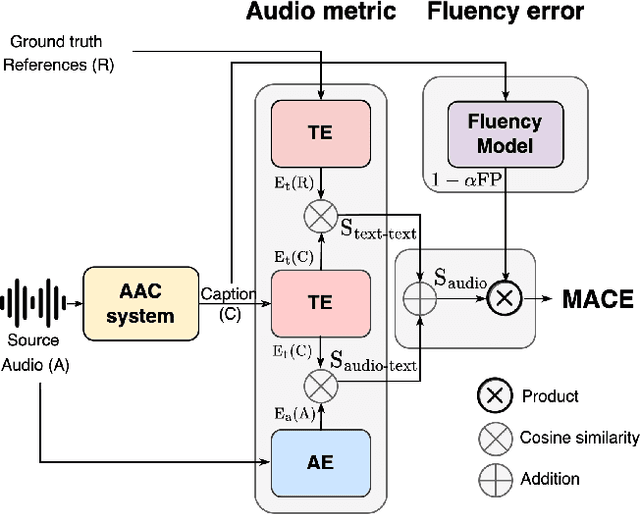
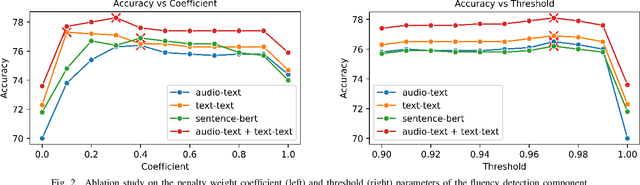
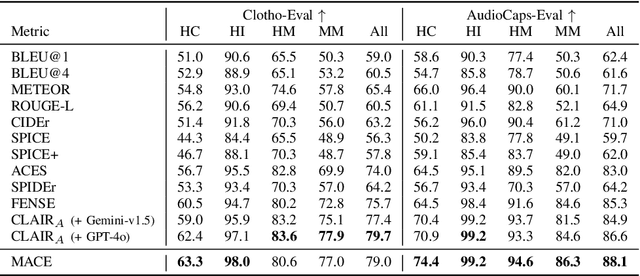
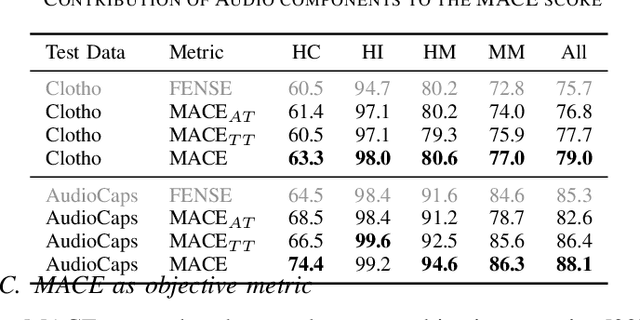
The Automated Audio Captioning (AAC) task aims to describe an audio signal using natural language. To evaluate machine-generated captions, the metrics should take into account audio events, acoustic scenes, paralinguistics, signal characteristics, and other audio information. Traditional AAC evaluation relies on natural language generation metrics like ROUGE and BLEU, image captioning metrics such as SPICE and CIDEr, or Sentence-BERT embedding similarity. However, these metrics only compare generated captions to human references, overlooking the audio signal itself. In this work, we propose MACE (Multimodal Audio-Caption Evaluation), a novel metric that integrates both audio and reference captions for comprehensive audio caption evaluation. MACE incorporates audio information from audio as well as predicted and reference captions and weights it with a fluency penalty. Our experiments demonstrate MACE's superior performance in predicting human quality judgments compared to traditional metrics. Specifically, MACE achieves a 3.28% and 4.36% relative accuracy improvement over the FENSE metric on the AudioCaps-Eval and Clotho-Eval datasets respectively. Moreover, it significantly outperforms all the previous metrics on the audio captioning evaluation task. The metric is opensourced at https://github.com/satvik-dixit/mace