 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Dysarthric Speech Recognition Using Adversarial and Signal-Based Augmentation
Paper and Code
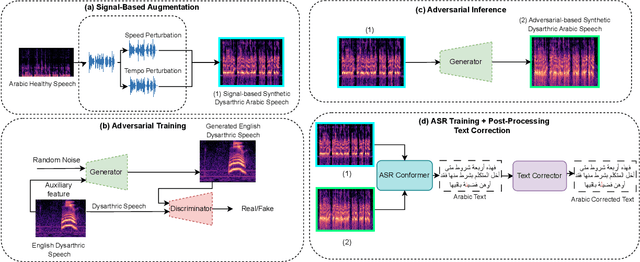
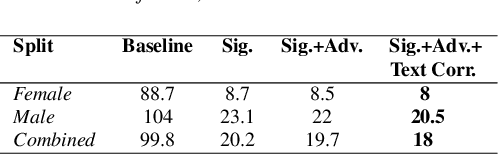
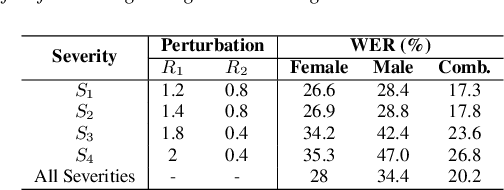
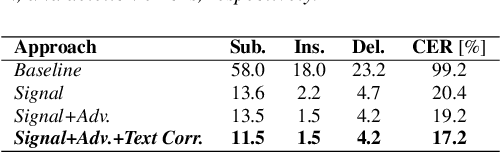
Despite major advancements in Automatic Speech Recognition (ASR), the state-of-the-art ASR systems struggle to deal with impaired speech even with high-resource languages. In Arabic, this challenge gets amplified, with added complexities in collecting data from dysarthric speakers. In this paper, we aim to improve the performance of Arabic dysarthric automatic speech recognition through a multi-stage augmentation approach. To this effect, we first propose a signal-based approach to generate dysarthric Arabic speech from healthy Arabic speech by modifying its speed and tempo. We also propose a second stage Parallel Wave Generative (PWG) adversarial model that is trained on an English dysarthric dataset to capture language-independant dysarthric speech patterns and further augment the signal-adjusted speech samples. Furthermore, we propose a fine-tuning and text-correction strategies for Arabic Conformer at different dysarthric speech severity levels. Our fine-tuned Conformer achieved 18% Word Error Rate (WER) and 17.2% Character Error Rate (CER) on synthetically generated dysarthric speech from the Arabic commonvoice speech dataset. This shows significant WER improvement of 81.8% compared to the baseline model trained solely on healthy data. We perform further validation on real English dysarthric speech showing a WER improvement of 124% compared to the baseline trained only on healthy English LJSpeech dataset.