 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJet-RL: Enabling On-Policy FP8 Reinforcement Learning with Unified Training and Rollout Precision Flow
Jan 20, 2026Reinforcement learning (RL) is essential for enhancing the complex reasoning capabilities of large language models (LLMs). However, existing RL training pipelines are computationally inefficient and resource-intensive, with the rollout phase accounting for over 70% of total training time. Quantized RL training, particularly using FP8 precision, offers a promising approach to mitigating this bottleneck. A commonly adopted strategy applies FP8 precision during rollout while retaining BF16 precision for training. In this work, we present the first comprehensive study of FP8 RL training and demonstrate that the widely used BF16-training + FP8-rollout strategy suffers from severe training instability and catastrophic accuracy collapse under long-horizon rollouts and challenging tasks. Our analysis shows that these failures stem from the off-policy nature of the approach, which introduces substantial numerical mismatch between training and inference. Motivated by these observations, we propose Jet-RL, an FP8 RL training framework that enables robust and stable RL optimization. The key idea is to adopt a unified FP8 precision flow for both training and rollout, thereby minimizing numerical discrepancies and eliminating the need for inefficient inter-step calibration. Extensive experiments validate the effectiveness of Jet-RL: our method achieves up to 33% speedup in the rollout phase, up to 41% speedup in the training phase, and a 16% end-to-end speedup over BF16 training, while maintaining stable convergence across all settings and incurring negligible accuracy degradation.
FlashInfer-Bench: Building the Virtuous Cycle for AI-driven LLM Systems
Jan 01, 2026Recent advances show that large language models (LLMs) can act as autonomous agents capable of generating GPU kernels, but integrating these AI-generated kernels into real-world inference systems remains challenging. FlashInfer-Bench addresses this gap by establishing a standardized, closed-loop framework that connects kernel generation, benchmarking, and deployment. At its core, FlashInfer Trace provides a unified schema describing kernel definitions, workloads, implementations, and evaluations, enabling consistent communication between agents and systems. Built on real serving traces, FlashInfer-Bench includes a curated dataset, a robust correctness- and performance-aware benchmarking framework, a public leaderboard to track LLM agents' GPU programming capabilities, and a dynamic substitution mechanism (apply()) that seamlessly injects the best-performing kernels into production LLM engines such as SGLang and vLLM. Using FlashInfer-Bench, we further evaluate the performance and limitations of LLM agents, compare the trade-offs among different GPU programming languages, and provide insights for future agent design. FlashInfer-Bench thus establishes a practical, reproducible pathway for continuously improving AI-generated kernels and deploying them into large-scale LLM inference.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
Local deployment of large-scale music AI models on commodity hardware
Nov 14, 2024


We present the MIDInfinite, a web application capable of generating symbolic music using a large-scale generative AI model locally on commodity hardware. Creating this demo involved porting the Anticipatory Music Transformer, a large language model (LLM) pre-trained on the Lakh MIDI dataset, to the Machine Learning Compilation (MLC) framework. Once the model is ported, MLC facilitates inference on a variety of runtimes including C++, mobile, and the browser. We envision that MLC has the potential to bridge the gap between the landscape of increasingly capable music AI models and technology more familiar to music software developers. As a proof of concept, we build a web application that allows users to generate endless streams of multi-instrumental MIDI in the browser, either from scratch or conditioned on a prompt. On commodity hardware (an M3 Macbook Pro), our demo can generate 51 notes per second, which is faster than real-time playback for 72.9% of generations, and increases to 86.3% with 2 seconds of upfront buffering.
Approximating Martingale Process for Variance Reduction in Deep Reinforcement Learning with Large State Space
Nov 29, 2022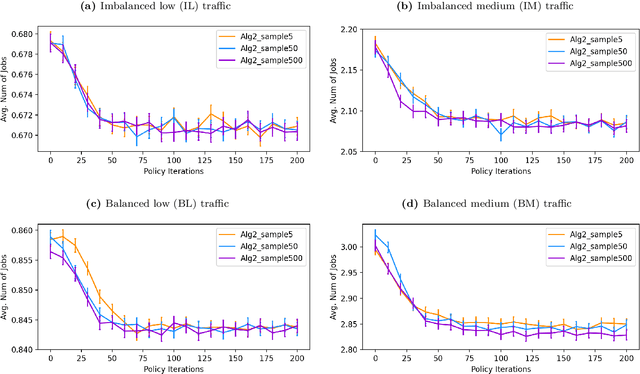



Approximating Martingale Process (AMP) is proven to be effective for variance reduction in reinforcement learning (RL) in specific cases such as Multiclass Queueing Networks. However, in the already proven cases, the state space is relatively small and all possible state transitions can be iterated through. In this paper, we consider systems in which state space is large and have uncertainties when considering state transitions, thus making AMP a generalized variance-reduction method in RL. Specifically, we will investigate the application of AMP in ride-hailing systems like Uber, where Proximal Policy Optimization (PPO) is incorporated to optimize the policy of matching drivers and customers.
Photo Rater: Photographs Auto-Selector with Deep Learning
Nov 26, 2022



Photo Rater is a computer vision project that uses neural networks to help photographers select the best photo among those that are taken based on the same scene. This process is usually referred to as "culling" in photography, and it can be tedious and time-consuming if done manually. Photo Rater utilizes three separate neural networks to complete such a task: one for general image quality assessment, one for classifying whether the photo is blurry (either due to unsteady hands or out-of-focusness), and one for assessing general aesthetics (including the composition of the photo, among others). After feeding the image through each neural network, Photo Rater outputs a final score for each image, ranking them based on this score and presenting it to the user.