 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-pop Lyric Translation: Dataset, Analysis, and Neural-Modelling
Paper and Code


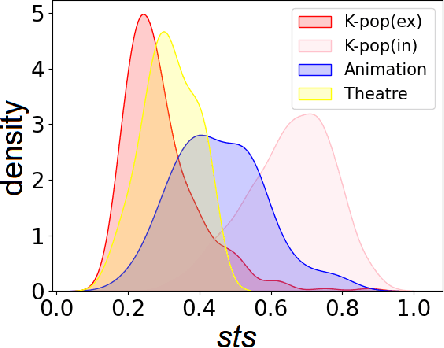
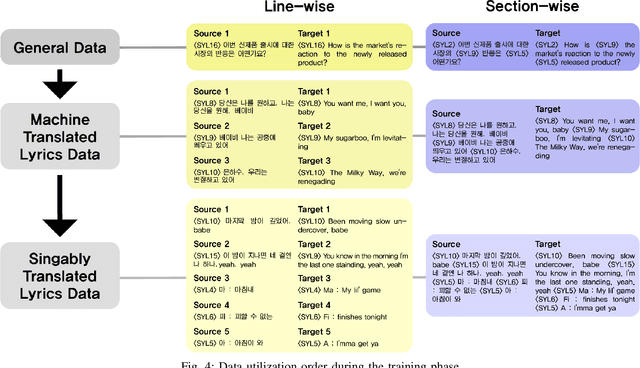
Lyric translation, a field studied for over a century, is now attracting computational linguistics researchers. We identified two limitations in previous studies. Firstly, lyric translation studies have predominantly focused on Western genres and languages, with no previous study centering on K-pop despite its popularity. Second, the field of lyric translation suffers from a lack of publicly available datasets; to the best of our knowledge, no such dataset exists. To broaden the scope of genres and languages in lyric translation studies, we introduce a novel singable lyric translation dataset, approximately 89\% of which consists of K-pop song lyrics. This dataset aligns Korean and English lyrics line-by-line and section-by-section. We leveraged this dataset to unveil unique characteristics of K-pop lyric translation, distinguishing it from other extensively studied genres, and to construct a neural lyric translation model, thereby underscoring the importance of a dedicated dataset for singable lyric translations.