 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusical Word Embedding for Music Tagging and Retrieval
Paper and Code
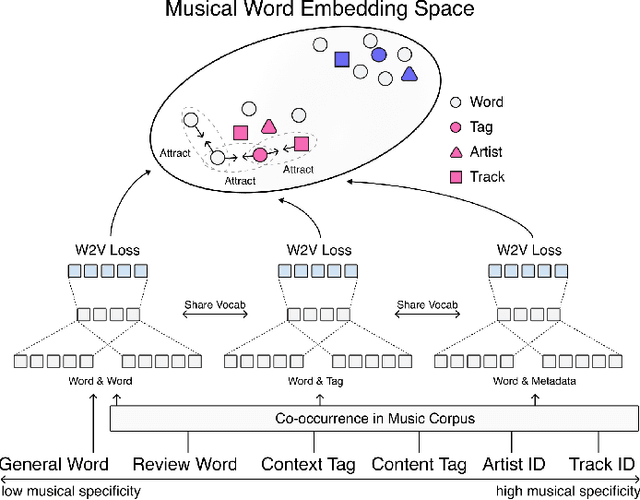
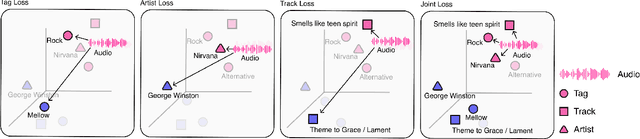
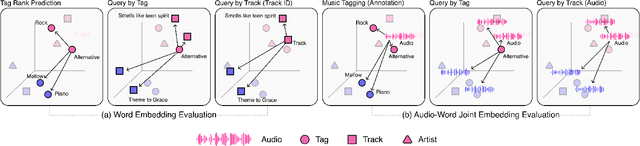
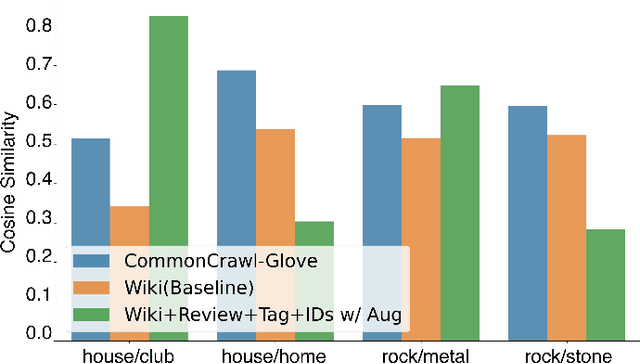
Word embedding has become an essential means for text-based information retrieval. Typically, word embeddings are learned from large quantities of general and unstructured text data. However, in the domain of music, the word embedding may have difficulty understanding musical contexts or recognizing music-related entities like artists and tracks. To address this issue, we propose a new approach called Musical Word Embedding (MWE), which involves learning from various types of texts, including both everyday and music-related vocabulary. We integrate MWE into an audio-word joint representation framework for tagging and retrieving music, using words like tag, artist, and track that have different levels of musical specificity. Our experiments show that using a more specific musical word like track results in better retrieval performance, while using a less specific term like tag leads to better tagging performance. To balance this compromise, we suggest multi-prototype training that uses words with different levels of musical specificity jointly. We evaluate both word embedding and audio-word joint embedding on four tasks (tag rank prediction, music tagging, query-by-tag, and query-by-track) across two datasets (Million Song Dataset and MTG-Jamendo). Our findings show that the suggested MWE is more efficient and robust than the conventional word embedding.