 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnoma-to-wave: Environmental sound synthesis from onomatopoeic words
Feb 11, 2021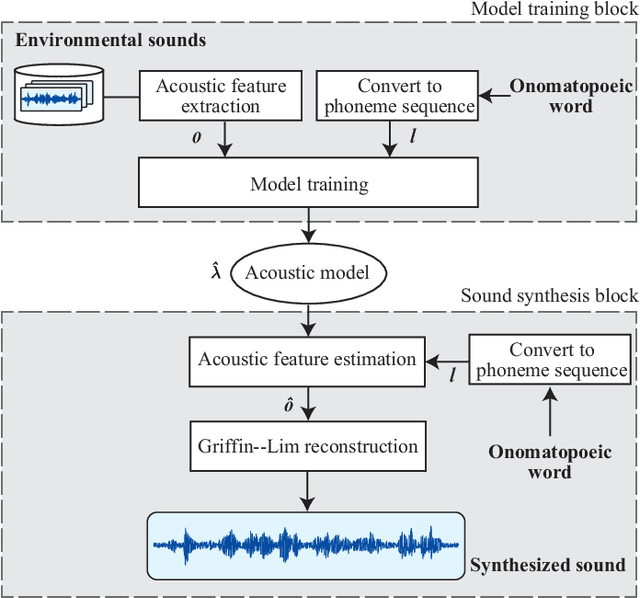
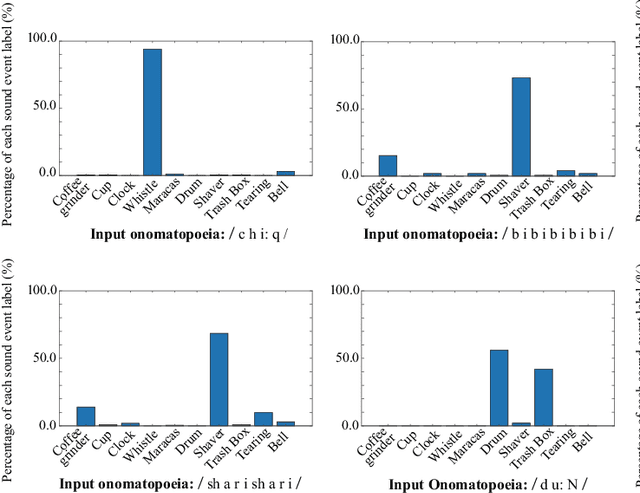
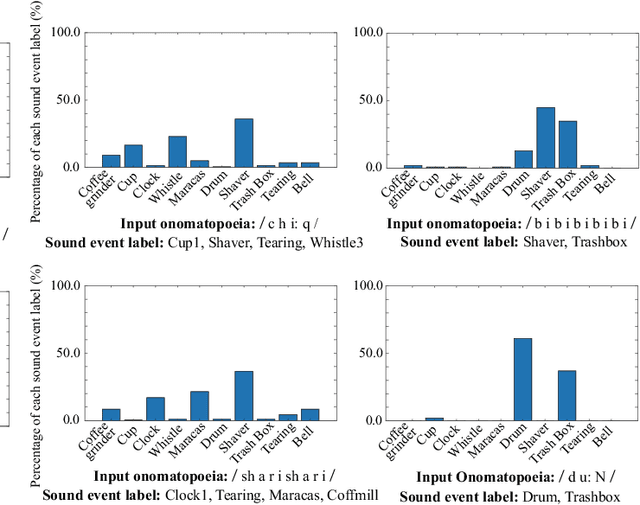
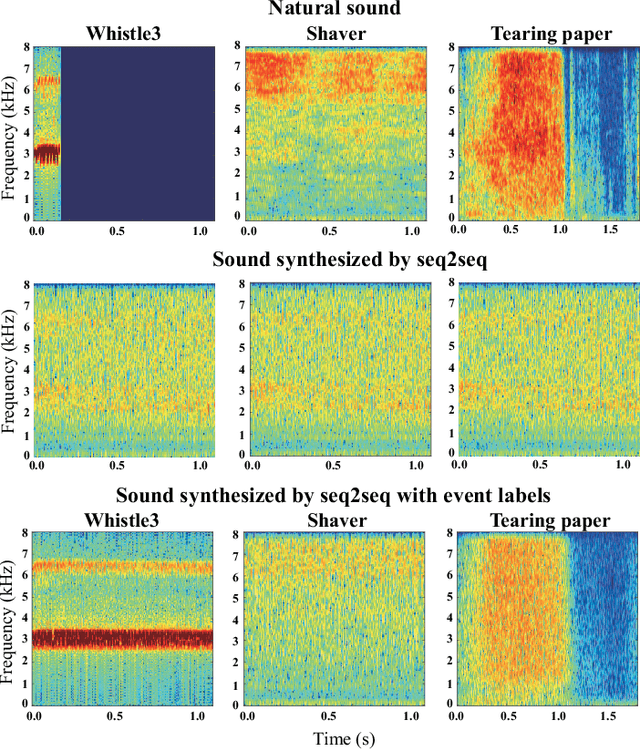
In this paper, we propose a new framework for environmental sound synthesis using onomatopoeic words and sound event labels. The conventional method of environmental sound synthesis, in which only sound event labels are used, cannot finely control the time-frequency structural features of synthesized sounds, such as sound duration, timbre, and pitch. There are various ways to express environmental sound other than sound event labels, such as the use of onomatopoeic words. An onomatopoeic word, which is a character sequence for phonetically imitating a sound, has been shown to be effective for describing the phonetic feature of sounds. We believe that environmental sound synthesis using onomatopoeic words will enable us to control the fine time-frequency structural features of synthesized sounds, such as sound duration, timbre, and pitch. In this paper, we thus propose environmental sound synthesis from onomatopoeic words on the basis of a sequence-to-sequence framework. To convert onomatopoeic words to environmental sound, we use a sequence-to-sequence framework. We also propose a method of environmental sound synthesis using onomatopoeic words and sound event labels to control the fine time-frequency structure and frequency property of synthesized sounds. Our subjective experiments show that the proposed method achieves the same level of sound quality as the conventional method using WaveNet. Moreover, our methods are better than the conventional method in terms of the expressiveness of synthesized sounds to onomatopoeic words.