 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrapheme-Coherent Phonemic and Prosodic Annotation of Speech by Implicit and Explicit Grapheme Conditioning
Jun 05, 2025We propose a model to obtain phonemic and prosodic labels of speech that are coherent with graphemes. Unlike previous methods that simply fine-tune a pre-trained ASR model with the labels, the proposed model conditions the label generation on corresponding graphemes by two methods: 1) Add implicit grapheme conditioning through prompt encoder using pre-trained BERT features. 2) Explicitly prune the label hypotheses inconsistent with the grapheme during inference. These methods enable obtaining parallel data of speech, the labels, and graphemes, which is applicable to various downstream tasks such as text-to-speech and accent estimation from text. Experiments showed that the proposed method significantly improved the consistency between graphemes and the predicted labels. Further, experiments on accent estimation task confirmed that the created parallel data by the proposed method effectively improve the estimation accuracy.
Audio-conditioned phonemic and prosodic annotation for building text-to-speech models from unlabeled speech data
Jun 12, 2024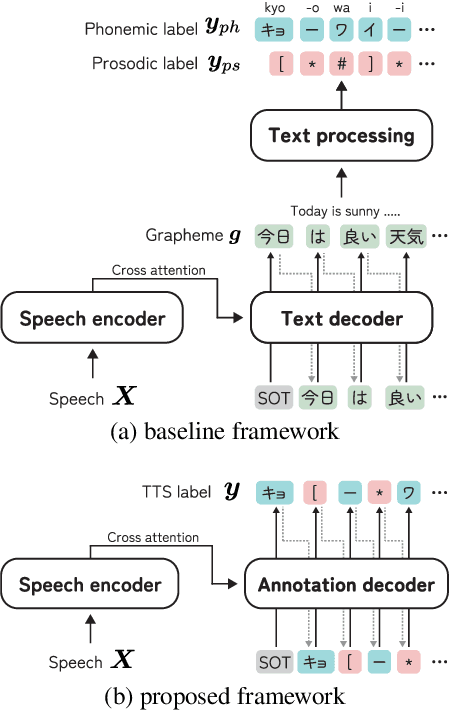
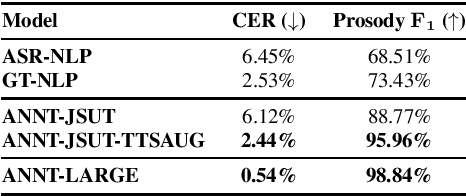
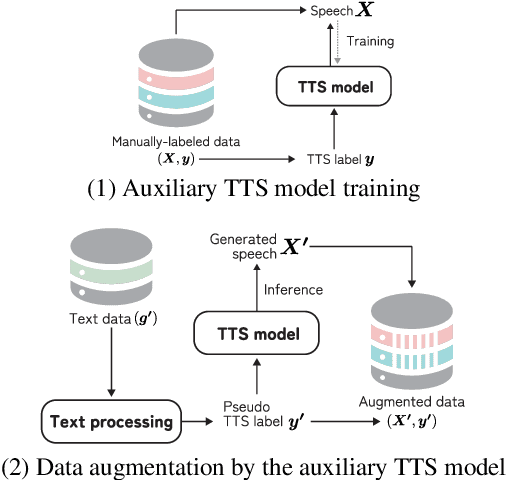

This paper proposes an audio-conditioned phonemic and prosodic annotation model for building text-to-speech (TTS) datasets from unlabeled speech samples. For creating a TTS dataset that consists of label-speech paired data, the proposed annotation model leverages an automatic speech recognition (ASR) model to obtain phonemic and prosodic labels from unlabeled speech samples. By fine-tuning a large-scale pre-trained ASR model, we can construct the annotation model using a limited amount of label-speech paired data within an existing TTS dataset. To alleviate the shortage of label-speech paired data for training the annotation model, we generate pseudo label-speech paired data using text-only corpora and an auxiliary TTS model. This TTS model is also trained with the existing TTS dataset. Experimental results show that the TTS model trained with the dataset created by the proposed annotation method can synthesize speech as naturally as the one trained with a fully-labeled dataset.
Phrase break prediction with bidirectional encoder representations in Japanese text-to-speech synthesis
Apr 26, 2021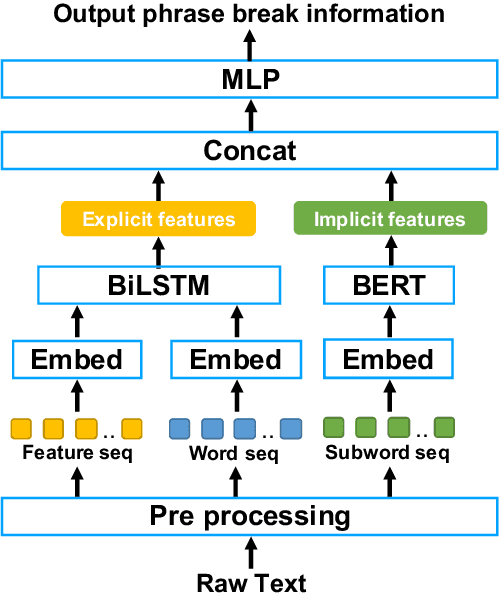



We propose a novel phrase break prediction method that combines implicit features extracted from a pre-trained large language model, a.k.a BERT, and explicit features extracted from BiLSTM with linguistic features. In conventional BiLSTM based methods, word representations and/or sentence representations are used as independent components. The proposed method takes account of both representations to extract the latent semantics, which cannot be captured by previous methods. The objective evaluation results show that the proposed method obtains an absolute improvement of 3.2 points for the F1 score compared with BiLSTM-based conventional methods using linguistic features. Moreover, the perceptual listening test results verify that a TTS system that applied our proposed method achieved a mean opinion score of 4.39 in prosody naturalness, which is highly competitive with the score of 4.37 for synthesized speech with ground-truth phrase breaks.