 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Learning for Regression via Quantum Annealing Based Spectral Sampling
Jan 13, 2026While quantum annealing (QA) has been developed for combinatorial optimization, practical QA devices operate at finite temperature and under noise, and their outputs can be regarded as stochastic samples close to a Gibbs--Boltzmann distribution. In this study, we propose a QA-in-the-loop kernel learning framework that integrates QA not merely as a substitute for Markov-chain Monte Carlo sampling but as a component that directly determines the learned kernel for regression. Based on Bochner's theorem, a shift-invariant kernel is represented as an expectation over a spectral distribution, and random Fourier features (RFF) approximate the kernel by sampling frequencies. We model the spectral distribution with a (multi-layer) restricted Boltzmann machine (RBM), generate discrete RBM samples using QA, and map them to continuous frequencies via a Gaussian--Bernoulli transformation. Using the resulting RFF, we construct a data-adaptive kernel and perform Nadaraya--Watson (NW) regression. Because the RFF approximation based on $\cos(\bmω^{\top}Δ\bm{x})$ can yield small negative values and cancellation across neighbors, the Nadaraya--Watson denominator $\sum_j k_{ij}$ may become close to zero. We therefore employ nonnegative squared-kernel weights $w_{ij}=k(\bm{x}_i,\bm{x}_j)^2$, which also enhances the contrast of kernel weights. The kernel parameters are trained by minimizing the leave-one-out NW mean squared error, and we additionally evaluate local linear regression with the same squared-kernel weights at inference. Experiments on multiple benchmark regression datasets demonstrate a decrease in training loss, accompanied by structural changes in the kernel matrix, and show that the learned kernel tends to improve $R^2$ and RMSE over the baseline Gaussian-kernel NW. Increasing the number of random features at inference further enhances accuracy.
Quantum generative model on bicycle-sharing system and an application
Oct 06, 2025



Recently, bicycle-sharing systems have been implemented in numerous cities, becoming integral to daily life. However, a prevalent issue arises when intensive commuting demand leads to bicycle shortages in specific areas and at particular times. To address this challenge, we employ a novel quantum machine learning model that analyzes time series data by fitting quantum time evolution to observed sequences. This model enables us to capture actual trends in bicycle counts at individual ports and identify correlations between different ports. Utilizing the trained model, we simulate the impact of proactively adding bicycles to high-demand ports on the overall rental number across the system. Given that the core of this method lies in a Monte Carlo simulation, it is anticipated to have a wide range of industrial applications.
Black-box optimization and quantum annealing for filtering out mislabeled training instances
Jan 12, 2025



This study proposes an approach for removing mislabeled instances from contaminated training datasets by combining surrogate model-based black-box optimization (BBO) with postprocessing and quantum annealing. Mislabeled training instances, a common issue in real-world datasets, often degrade model generalization, necessitating robust and efficient noise-removal strategies. The proposed method evaluates filtered training subsets based on validation loss, iteratively refines loss estimates through surrogate model-based BBO with postprocessing, and leverages quantum annealing to efficiently sample diverse training subsets with low validation error. Experiments on a noisy majority bit task demonstrate the method's ability to prioritize the removal of high-risk mislabeled instances. Integrating D-Wave's clique sampler running on a physical quantum annealer achieves faster optimization and higher-quality training subsets compared to OpenJij's simulated quantum annealing sampler or Neal's simulated annealing sampler, offering a scalable framework for enhancing dataset quality. This work highlights the effectiveness of the proposed method for supervised learning tasks, with future directions including its application to unsupervised learning, real-world datasets, and large-scale implementations.
Relaxation-assisted reverse annealing on nonnegative/binary matrix factorization
Jan 03, 2025
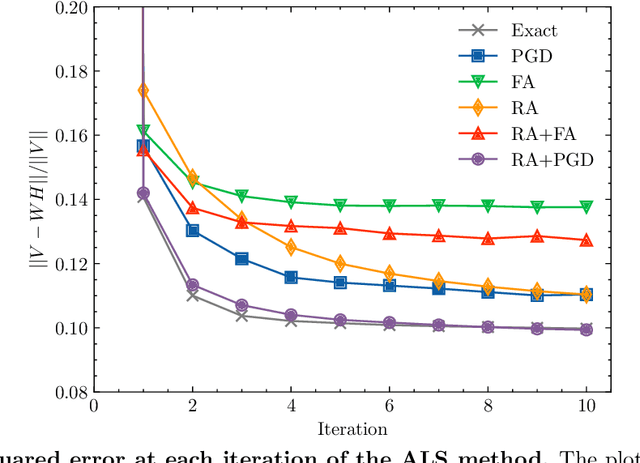
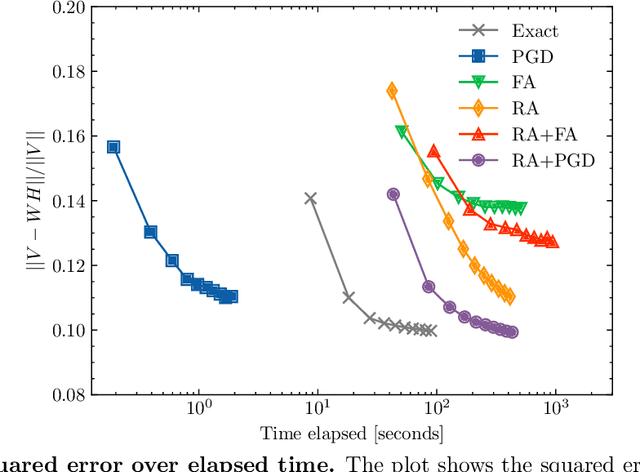
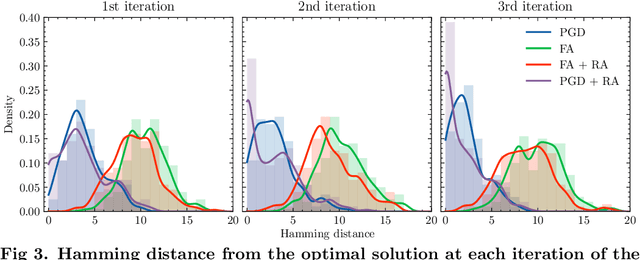
Quantum annealing has garnered significant attention as meta-heuristics inspired by quantum physics for combinatorial optimization problems. Among its many applications, nonnegative/binary matrix factorization stands out for its complexity and relevance in unsupervised machine learning. The use of reverse annealing, a derivative procedure of quantum annealing to prioritize the search in a vicinity under a given initial state, helps improve its optimization performance in matrix factorization. This study proposes an improved strategy that integrates reverse annealing with a linear programming relaxation technique. Using relaxed solutions as the initial configuration for reverse annealing, we demonstrate improvements in optimization performance comparable to the exact optimization methods. Our experiments on facial image datasets show that our method provides better convergence than known reverse annealing methods. Furthermore, we investigate the effectiveness of relaxation-based initialization methods on randomized datasets, demonstrating a relationship between the relaxed solution and the optimal solution. This research underscores the potential of combining reverse annealing and classical optimization strategies to enhance optimization performance.
Schödinger Bridge Type Diffusion Models as an Extension of Variational Autoencoders
Dec 24, 2024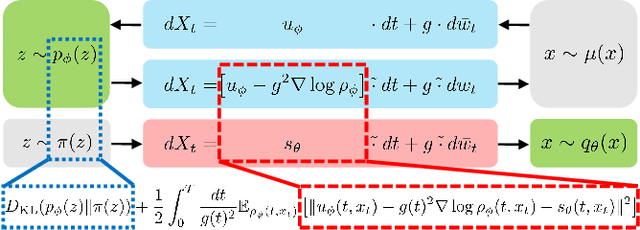
Generative diffusion models use time-forward and backward stochastic differential equations to connect the data and prior distributions. While conventional diffusion models (e.g., score-based models) only learn the backward process, more flexible frameworks have been proposed to also learn the forward process by employing the Schr\"odinger bridge (SB). However, due to the complexity of the mathematical structure behind SB-type models, we can not easily give an intuitive understanding of their objective function. In this work, we propose a unified framework to construct diffusion models by reinterpreting the SB-type models as an extension of variational autoencoders. In this context, the data processing inequality plays a crucial role. As a result, we find that the objective function consists of the prior loss and drift matching parts.
Routing and Scheduling Optimization for Urban Air Mobility Fleet Management using Quantum Annealing
Oct 15, 2024



The growing integration of urban air mobility (UAM) for urban transportation and delivery has accelerated due to increasing traffic congestion and its environmental and economic repercussions. Efficiently managing the anticipated high-density air traffic in cities is critical to ensure safe and effective operations. In this study, we propose a routing and scheduling framework to address the needs of a large fleet of UAM vehicles operating in urban areas. Using mathematical optimization techniques, we plan efficient and deconflicted routes for a fleet of vehicles. Formulating route planning as a maximum weighted independent set problem enables us to utilize various algorithms and specialized optimization hardware, such as quantum annealers, which has seen substantial progress in recent years. Our method is validated using a traffic management simulator tailored for the airspace in Singapore. Our approach enhances airspace utilization by distributing traffic throughout a region. This study broadens the potential applications of optimization techniques in UAM traffic management.
Application of time-series quantum generative model to financial data
May 20, 2024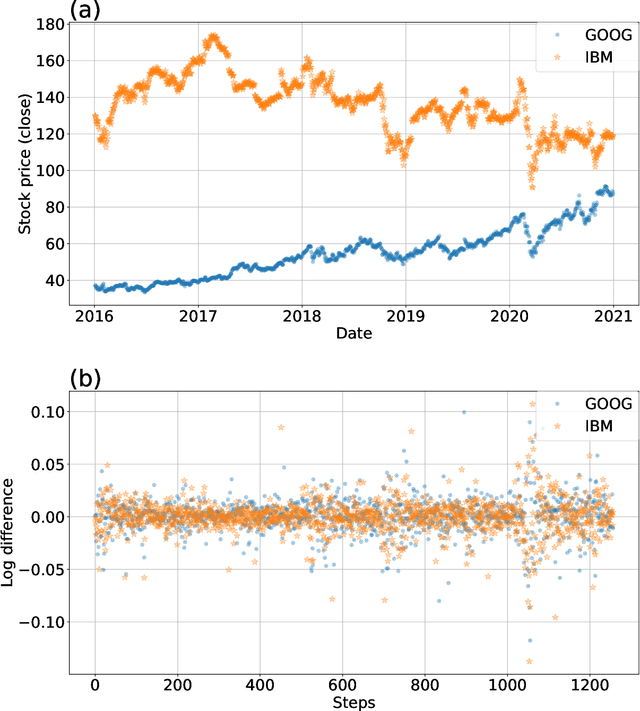

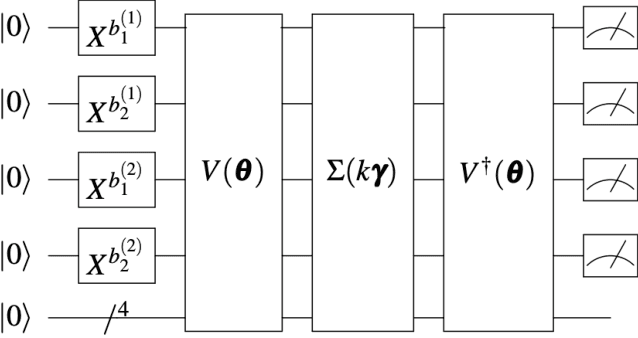
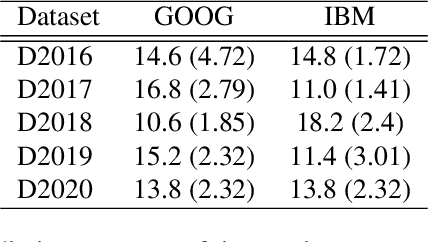
Despite proposing a quantum generative model for time series that successfully learns correlated series with multiple Brownian motions, the model has not been adapted and evaluated for financial problems. In this study, a time-series generative model was applied as a quantum generative model to actual financial data. Future data for two correlated time series were generated and compared with classical methods such as long short-term memory and vector autoregression. Furthermore, numerical experiments were performed to complete missing values. Based on the results, we evaluated the practical applications of the time-series quantum generation model. It was observed that fewer parameter values were required compared with the classical method. In addition, the quantum time-series generation model was feasible for both stationary and nonstationary data. These results suggest that several parameters can be applied to various types of time-series data.
Statistical Mechanics Calculations Using Variational Autoregressive Networks and Quantum Annealing
Apr 30, 2024


In statistical mechanics, computing the partition function is generally difficult. An approximation method using a variational autoregressive network (VAN) has been proposed recently. This approach offers the advantage of directly calculating the generation probabilities while obtaining a significantly large number of samples. The present study introduces a novel approximation method that employs samples derived from quantum annealing machines in conjunction with VAN, which are empirically assumed to adhere to the Gibbs-Boltzmann distribution. When applied to the finite-size Sherrington-Kirkpatrick model, the proposed method demonstrates enhanced accuracy compared to the traditional VAN approach and other approximate methods, such as the widely utilized naive mean field.
Solution space and storage capacity of fully connected two-layer neural networks with generic activation functions
Apr 20, 2024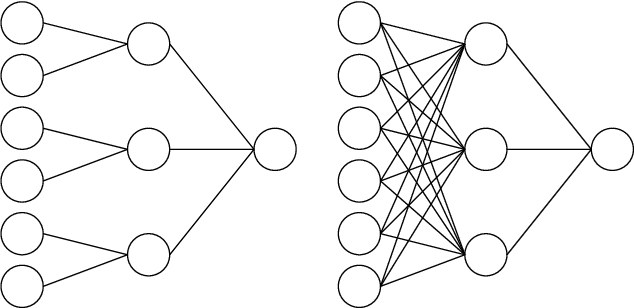
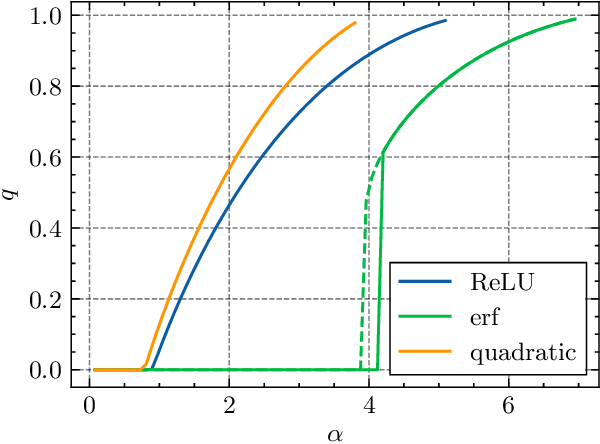
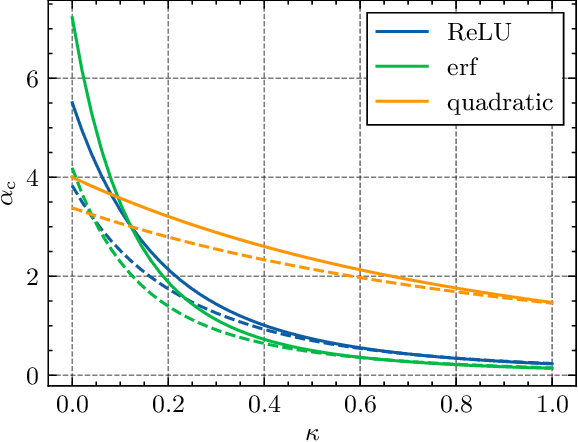
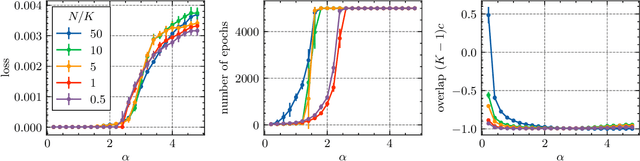
The storage capacity of a binary classification model is the maximum number of random input-output pairs per parameter that the model can learn. It is one of the indicators of the expressive power of machine learning models and is important for comparing the performance of various models. In this study, we analyze the structure of the solution space and the storage capacity of fully connected two-layer neural networks with general activation functions using the replica method from statistical physics. Our results demonstrate that the storage capacity per parameter remains finite even with infinite width and that the weights of the network exhibit negative correlations, leading to a 'division of labor'. In addition, we find that increasing the dataset size triggers a phase transition at a certain transition point where the permutation symmetry of weights is broken, resulting in the solution space splitting into disjoint regions. We identify the dependence of this transition point and the storage capacity on the choice of activation function. These findings contribute to understanding the influence of activation functions and the number of parameters on the structure of the solution space, potentially offering insights for selecting appropriate architectures based on specific objectives.
Spatio-temporal reconstruction of substance dynamics using compressed sensing in multi-spectral magnetic resonance spectroscopic imaging
Mar 01, 2024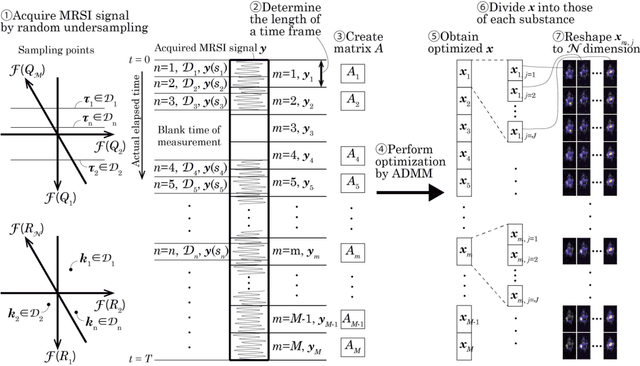
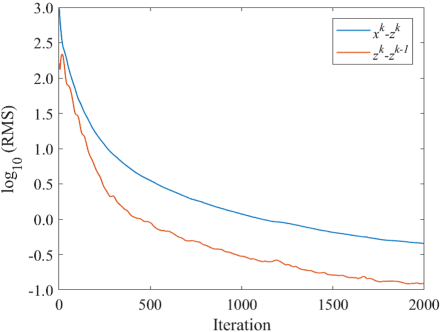
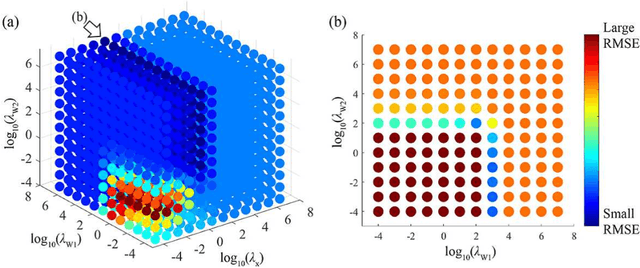
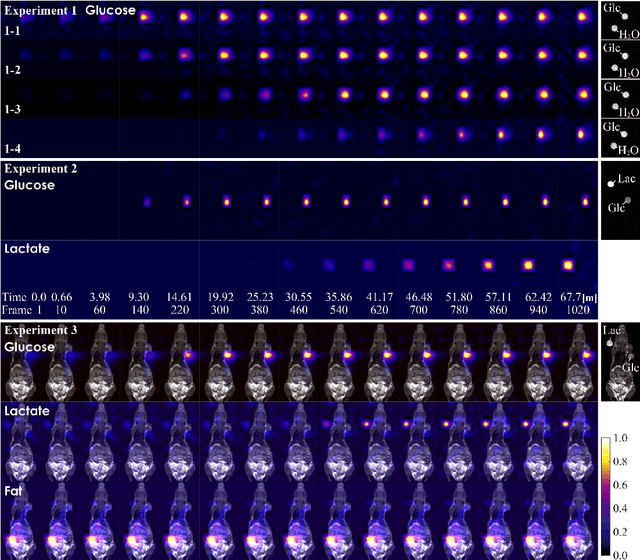
The objective of our study is to observe dynamics of multiple substances in vivo with high temporal resolution from multi-spectral magnetic resonance spectroscopic imaging (MRSI) data. The multi-spectral MRSI can effectively separate spectral peaks of multiple substances and is useful to measure spatial distributions of substances. However it is difficult to measure time-varying substance distributions directly by ordinary full sampling because the measurement requires a significantly long time. In this study, we propose a novel method to reconstruct the spatio-temporal distributions of substances from randomly undersampled multi-spectral MRSI data on the basis of compressed sensing (CS) and the partially separable function model with base spectra of substances. In our method, we have employed spatio-temporal sparsity and temporal smoothness of the substance distributions as prior knowledge to perform CS. The effectiveness of our method has been evaluated using phantom data sets of glass tubes filled with glucose or lactate solution in increasing amounts over time and animal data sets of a tumor-bearing mouse to observe the metabolic dynamics involved in the Warburg effect in vivo. The reconstructed results are consistent with the expected behaviors, showing that our method can reconstruct the spatio-temporal distribution of substances with a temporal resolution of four seconds which is extremely short time scale compared with that of full sampling. Since this method utilizes only prior knowledge naturally assumed for the spatio-temporal distributions of substances and is independent of the number of the spectral and spatial dimensions or the acquisition sequence of MRSI, it is expected to contribute to revealing the underlying substance dynamics in MRSI data already acquired or to be acquired in the future.