 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscretization and Re-synthesis: an alternative method to solve the Cocktail Party Problem
Paper and Code
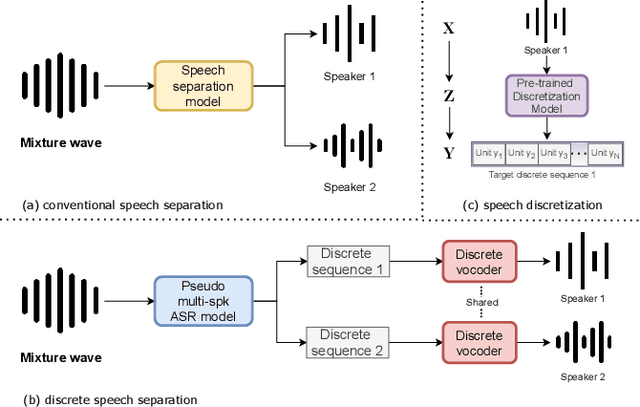

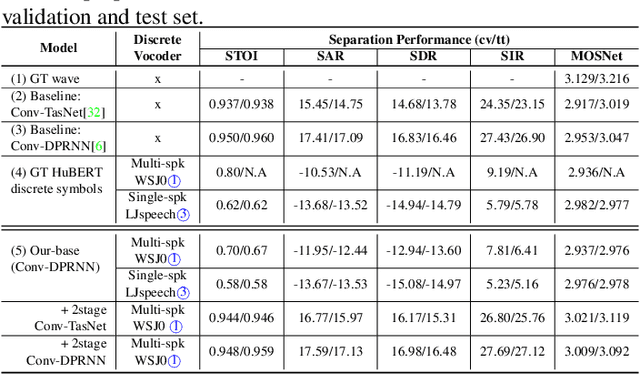
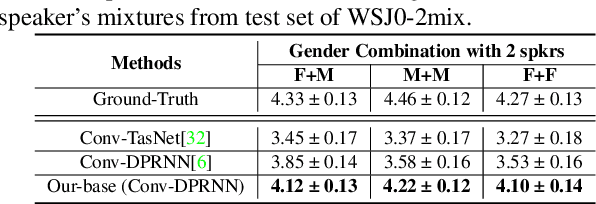
Deep learning based models have significantly improved the performance of speech separation with input mixtures like the cocktail party. Prominent methods (e.g., frequency-domain and time-domain speech separation) usually build regression models to predict the ground-truth speech from the mixture, using the masking-based design and the signal-level loss criterion (e.g., MSE or SI-SNR). This study demonstrates, for the first time, that the synthesis-based approach can also perform well on this problem, with great flexibility and strong potential. Specifically, we propose a novel speech separation/enhancement model based on the recognition of discrete symbols, and convert the paradigm of the speech separation/enhancement related tasks from regression to classification. By utilizing the synthesis model with the input of discrete symbols, after the prediction of discrete symbol sequence, each target speech could be re-synthesized. Evaluation results based on the WSJ0-2mix and VCTK-noisy corpora in various settings show that our proposed method can steadily synthesize the separated speech with high speech quality and without any interference, which is difficult to avoid in regression-based methods. In addition, with negligible loss of listening quality, the speaker conversion of enhanced/separated speech could be easily realized through our method.