 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Self-supervised Speech Representation Based Voice Conversion
Paper and Code
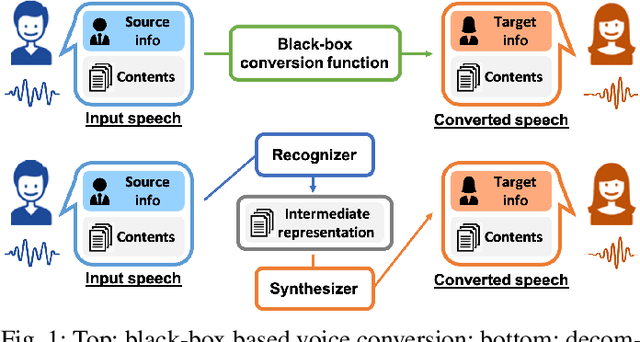
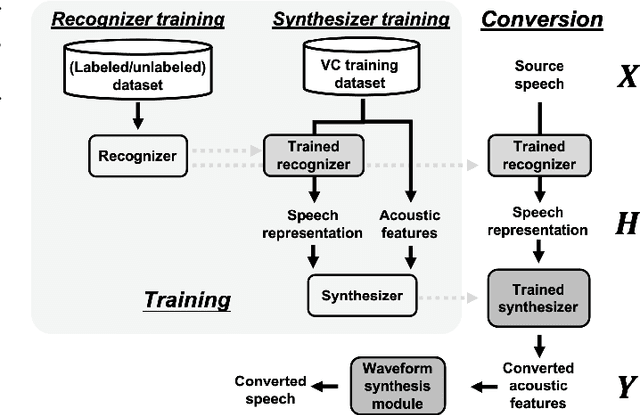
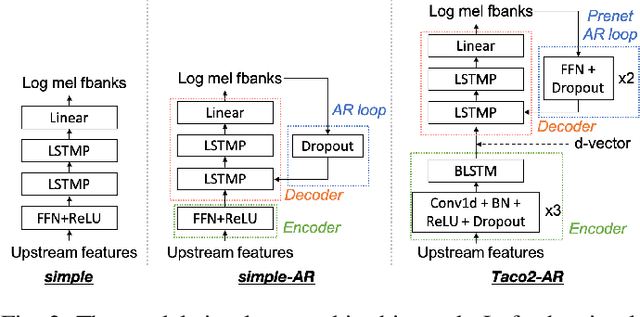
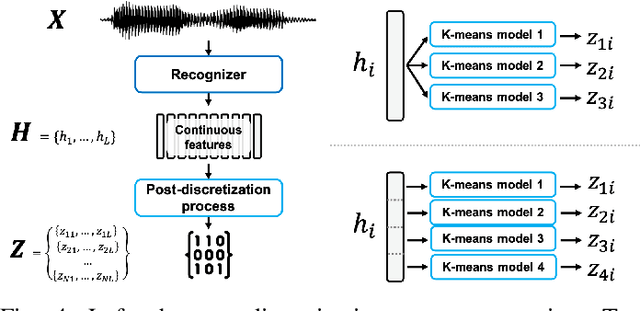
We present a large-scale comparative study of self-supervised speech representation (S3R)-based voice conversion (VC). In the context of recognition-synthesis VC, S3Rs are attractive owing to their potential to replace expensive supervised representations such as phonetic posteriorgrams (PPGs), which are commonly adopted by state-of-the-art VC systems. Using S3PRL-VC, an open-source VC software we previously developed, we provide a series of in-depth objective and subjective analyses under three VC settings: intra-/cross-lingual any-to-one (A2O) and any-to-any (A2A) VC, using the voice conversion challenge 2020 (VCC2020) dataset. We investigated S3R-based VC in various aspects, including model type, multilinguality, and supervision. We also studied the effect of a post-discretization process with k-means clustering and showed how it improves in the A2A setting. Finally, the comparison with state-of-the-art VC systems demonstrates the competitiveness of S3R-based VC and also sheds light on the possible improving directions.