 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Novel and Realistic Speakers for Voice Conversion
Nov 10, 2025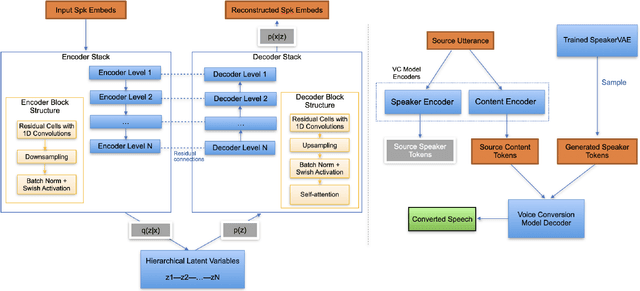



Voice conversion models modify timbre while preserving paralinguistic features, enabling applications like dubbing and identity protection. However, most VC systems require access to target utterances, limiting their use when target data is unavailable or when users desire conversion to entirely novel, unseen voices. To address this, we introduce a lightweight method SpeakerVAE to generate novel speakers for VC. Our approach uses a deep hierarchical variational autoencoder to model the speaker timbre space. By sampling from the trained model, we generate novel speaker representations for voice synthesis in a VC pipeline. The proposed method is a flexible plug-in module compatible with various VC models, without co-training or fine-tuning of the base VC system. We evaluated our approach with state-of-the-art VC models: FACodec and CosyVoice2. The results demonstrate that our method successfully generates novel, unseen speakers with quality comparable to that of the training speakers.
GTR-Voice: Articulatory Phonetics Informed Controllable Expressive Speech Synthesis
Jun 15, 2024

Expressive speech synthesis aims to generate speech that captures a wide range of para-linguistic features, including emotion and articulation, though current research primarily emphasizes emotional aspects over the nuanced articulatory features mastered by professional voice actors. Inspired by this, we explore expressive speech synthesis through the lens of articulatory phonetics. Specifically, we define a framework with three dimensions: Glottalization, Tenseness, and Resonance (GTR), to guide the synthesis at the voice production level. With this framework, we record a high-quality speech dataset named GTR-Voice, featuring 20 Chinese sentences articulated by a professional voice actor across 125 distinct GTR combinations. We verify the framework and GTR annotations through automatic classification and listening tests, and demonstrate precise controllability along the GTR dimensions on two fine-tuned expressive TTS models. We open-source the dataset and TTS models.
Articulatory Phonetics Informed Controllable Expressive Speech Synthesis
Jun 15, 2024Expressive speech synthesis aims to generate speech that captures a wide range of para-linguistic features, including emotion and articulation, though current research primarily emphasizes emotional aspects over the nuanced articulatory features mastered by professional voice actors. Inspired by this, we explore expressive speech synthesis through the lens of articulatory phonetics. Specifically, we define a framework with three dimensions: Glottalization, Tenseness, and Resonance (GTR), to guide the synthesis at the voice production level. With this framework, we record a high-quality speech dataset named GTR-Voice, featuring 20 Chinese sentences articulated by a professional voice actor across 125 distinct GTR combinations. We verify the framework and GTR annotations through automatic classification and listening tests, and demonstrate precise controllability along the GTR dimensions on two fine-tuned expressive TTS models. We open-source the dataset and TTS models.