 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENIE-ASI: Generative Instruction and Executable Code for Analog Subcircuit Identification
Aug 26, 2025Analog subcircuit identification is a core task in analog design, essential for simulation, sizing, and layout. Traditional methods often require extensive human expertise, rule-based encoding, or large labeled datasets. To address these challenges, we propose GENIE-ASI, the first training-free, large language model (LLM)-based methodology for analog subcircuit identification. GENIE-ASI operates in two phases: it first uses in-context learning to derive natural language instructions from a few demonstration examples, then translates these into executable Python code to identify subcircuits in unseen SPICE netlists. In addition, to evaluate LLM-based approaches systematically, we introduce a new benchmark composed of operational amplifier netlists (op-amps) that cover a wide range of subcircuit variants. Experimental results on the proposed benchmark show that GENIE-ASI matches rule-based performance on simple structures (F1-score = 1.0), remains competitive on moderate abstractions (F1-score = 0.81), and shows potential even on complex subcircuits (F1-score = 0.31). These findings demonstrate that LLMs can serve as adaptable, general-purpose tools in analog design automation, opening new research directions for foundation model applications in analog design automation.
Locality-aware Surrogates for Gradient-based Black-box Optimization
Jan 31, 2025In physics and engineering, many processes are modeled using non-differentiable black-box simulators, making the optimization of such functions particularly challenging. To address such cases, inspired by the Gradient Theorem, we propose locality-aware surrogate models for active model-based black-box optimization. We first establish a theoretical connection between gradient alignment and the minimization of a Gradient Path Integral Equation (GradPIE) loss, which enforces consistency of the surrogate's gradients in local regions of the design space. Leveraging this theoretical insight, we develop a scalable training algorithm that minimizes the GradPIE loss, enabling both offline and online learning while maintaining computational efficiency. We evaluate our approach on three real-world tasks - spanning automated in silico experiments such as coupled nonlinear oscillators, analog circuits, and optical systems - and demonstrate consistent improvements in optimization efficiency under limited query budgets. Our results offer dependable solutions for both offline and online optimization tasks where reliable gradient estimation is needed.
Schemato -- An LLM for Netlist-to-Schematic Conversion
Nov 21, 2024



Machine learning models are advancing circuit design, particularly in analog circuits. They typically generate netlists that lack human interpretability. This is a problem as human designers heavily rely on the interpretability of circuit diagrams or schematics to intuitively understand, troubleshoot, and develop designs. Hence, to integrate domain knowledge effectively, it is crucial to translate ML-generated netlists into interpretable schematics quickly and accurately. We propose Schemato, a large language model (LLM) for netlist-to-schematic conversion. In particular, we consider our approach in the two settings of converting netlists to .asc files for LTSpice and LATEX files for CircuiTikz schematics. Experiments on our circuit dataset show that Schemato achieves up to 93% compilation success rate for the netlist-to-LaTeX conversion task, surpassing the 26% rate scored by the state-of-the-art LLMs. Furthermore, our experiments show that Schemato generates schematics with a mean structural similarity index measure that is 3xhigher than the best performing LLMs, therefore closer to the reference human design.
GraCo -- A Graph Composer for Integrated Circuits
Nov 21, 2024



Designing integrated circuits involves substantial complexity, posing challenges in revealing its potential applications - from custom digital cells to analog circuits. Despite extensive research over the past decades in building versatile and automated frameworks, there remains open room to explore more computationally efficient AI-based solutions. This paper introduces the graph composer GraCo, a novel method for synthesizing integrated circuits using reinforcement learning (RL). GraCo learns to construct a graph step-by-step, which is then converted into a netlist and simulated with SPICE. We demonstrate that GraCo is highly configurable, enabling the incorporation of prior design knowledge into the framework. We formalize how this prior knowledge can be utilized and, in particular, show that applying consistency checks enhances the efficiency of the sampling process. To evaluate its performance, we compare GraCo to a random baseline, which is known to perform well for smaller design space problems. We demonstrate that GraCo can discover circuits for tasks such as generating standard cells, including the inverter and the two-input NAND (NAND2) gate. Compared to a random baseline, GraCo requires 5x fewer sampling steps to design an inverter and successfully synthesizes a NAND2 gate that is 2.5x faster.
Knowledge-Distilled Graph Neural Networks for Personalized Epileptic Seizure Detection
Apr 03, 2023



Wearable devices for seizure monitoring detection could significantly improve the quality of life of epileptic patients. However, existing solutions that mostly rely on full electrode set of electroencephalogram (EEG) measurements could be inconvenient for every day use. In this paper, we propose a novel knowledge distillation approach to transfer the knowledge from a sophisticated seizure detector (called the teacher) trained on data from the full set of electrodes to learn new detectors (called the student). They are both providing lightweight implementations and significantly reducing the number of electrodes needed for recording the EEG. We consider the case where the teacher and the student seizure detectors are graph neural networks (GNN), since these architectures actively use the connectivity information. We consider two cases (a) when a single student is learnt for all the patients using preselected channels; and (b) when personalized students are learnt for every individual patient, with personalized channel selection using a Gumbelsoftmax approach. Our experiments on the publicly available Temple University Hospital EEG Seizure Data Corpus (TUSZ) show that both knowledge-distillation and personalization play significant roles in improving performance of seizure detection, particularly for patients with scarce EEG data. We observe that using as few as two channels, we are able to obtain competitive seizure detection performance. This, in turn, shows the potential of our approach in more realistic scenario of wearable devices for personalized monitoring of seizures, even with few recordings.
A Meta-GNN approach to personalized seizure detection and classification
Nov 01, 2022In this paper, we propose a personalized seizure detection and classification framework that quickly adapts to a specific patient from limited seizure samples. We achieve this by combining two novel paradigms that have recently seen much success in a wide variety of real-world applications: graph neural networks (GNN), and meta-learning. We train a Meta-GNN based classifier that learns a global model from a set of training patients such that this global model can eventually be adapted to a new unseen patient using very limited samples. We apply our approach on the TUSZ-dataset, one of the largest and publicly available benchmark datasets for epilepsy. We show that our method outperforms the baselines by reaching 82.7% on accuracy and 82.08% on F1 score after only 20 iterations on new unseen patients.
Task-similarity Aware Meta-learning through Nonparametric Kernel Regression
Jun 12, 2020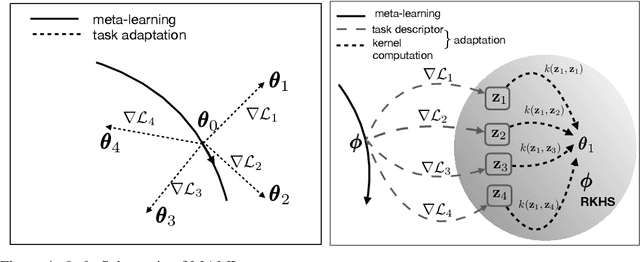
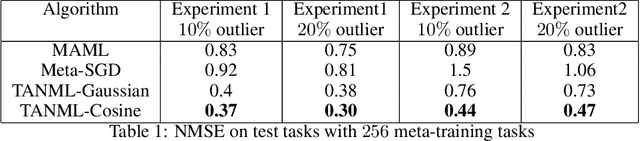
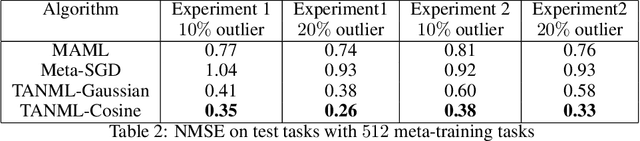
Meta-learning refers to the process of abstracting a learning rule for a class of tasks through a meta-parameter that captures the inductive bias for the class. The metaparameter is used to achieve a fast adaptation to unseen tasks from the class, given a few training samples. While meta-learning implicitly assumes the tasks as being similar, it is generally unclear how this similarity could be quantified. Further, many of the popular meta-learning approaches do not actively use such a task-similarity in solving for the tasks. In this paper, we propose the task-similarity aware nonparameteric meta-learning algorithm that explicitly employs similarity/dissimilarity between tasks using nonparametric kernel regression. Our approach models the task-specific parameters to lie in a reproducing kernel Hilbert space, wherein the kernel function captures the similarity across tasks. The proposed algorithm iteratively learns a meta-parameter which is used to assign a task-specific descriptor for every task. The task descriptors are then used to quantify the similarity through the kernel function. We show how our approach generalizes the popular meta-learning approaches of model-agnostic meta-learning (MAML) and Meta-stochastic gradient descent (Meta-SGD) approaches. Numerical experiments with regression tasks show that our algorithm performs well even in the presence of outlier or dissimilar tasks, validating the proposed approach
Predictive Analysis of COVID-19 Time-series Data from Johns Hopkins University
May 22, 2020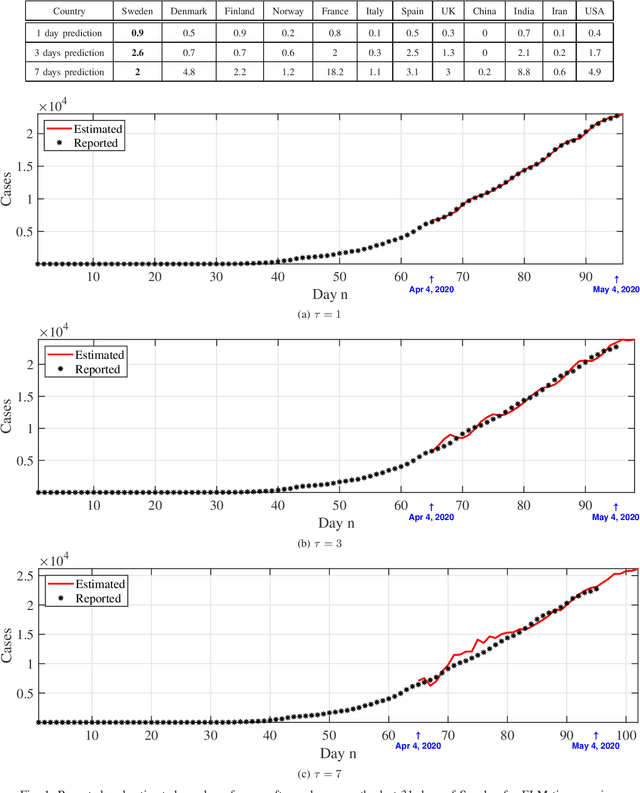
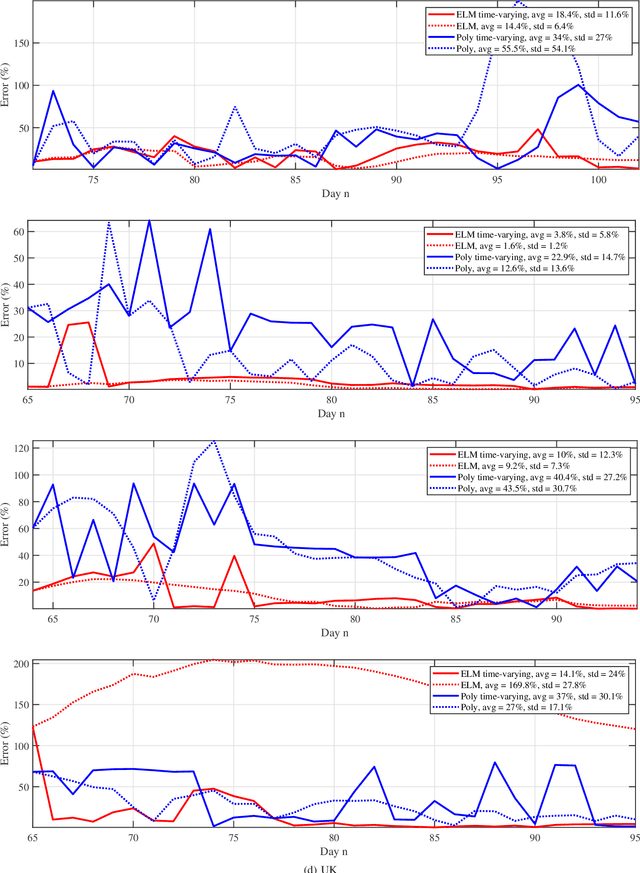
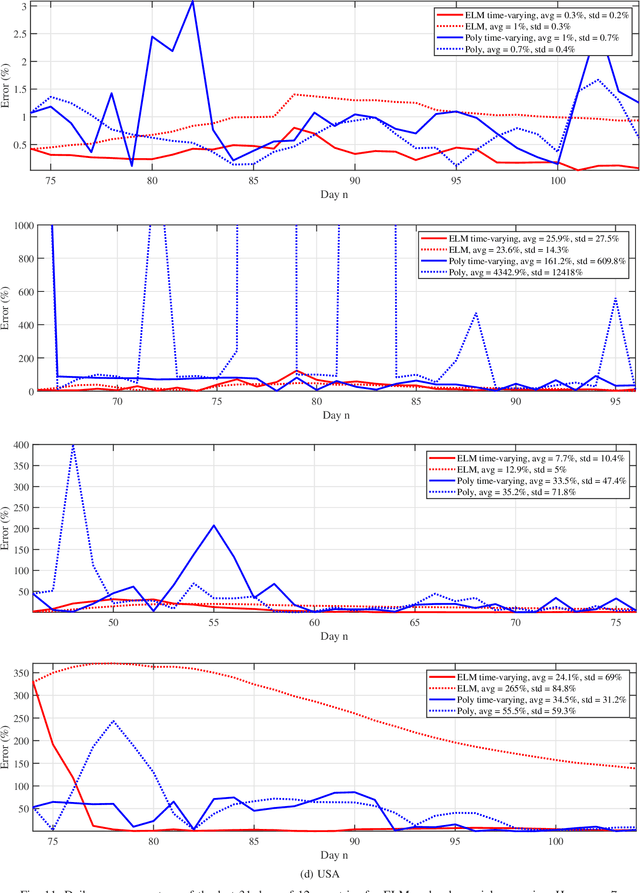
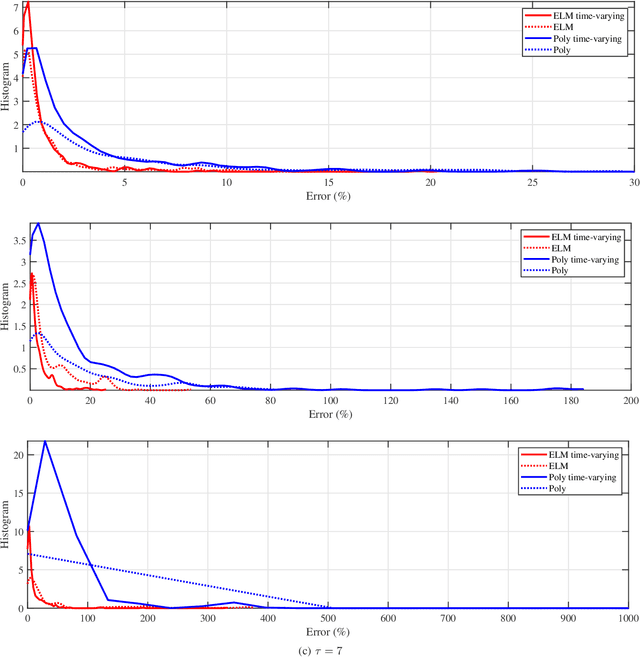
We provide a predictive analysis of the spread of COVID-19, also known as SARS-CoV-2, using the dataset made publicly available online by the Johns Hopkins University. Our main objective is to provide predictions of the number of infected people for different countries in the next 14 days. The predictive analysis is done using time-series data transformed on a logarithmic scale. We use two well-known methods for prediction: polynomial regression and neural network. As the number of training data for each country is limited, we use a single-layer neural network called the extreme learning machine (ELM) to avoid over-fitting. Due to the non-stationary nature of the time-series, a sliding window approach is used to provide a more accurate prediction.
On Training and Evaluation of Neural Network Approaches for Model Predictive Control
May 08, 2020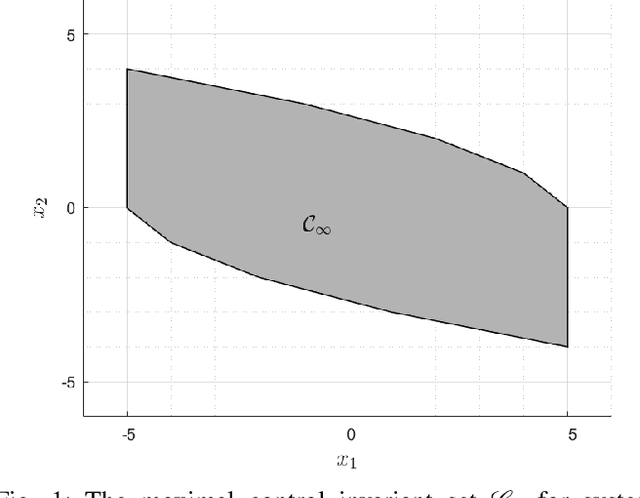
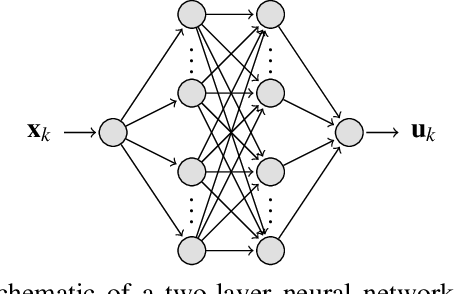
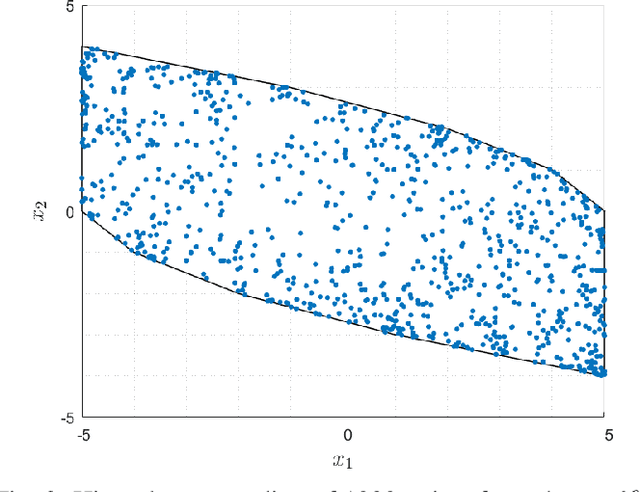
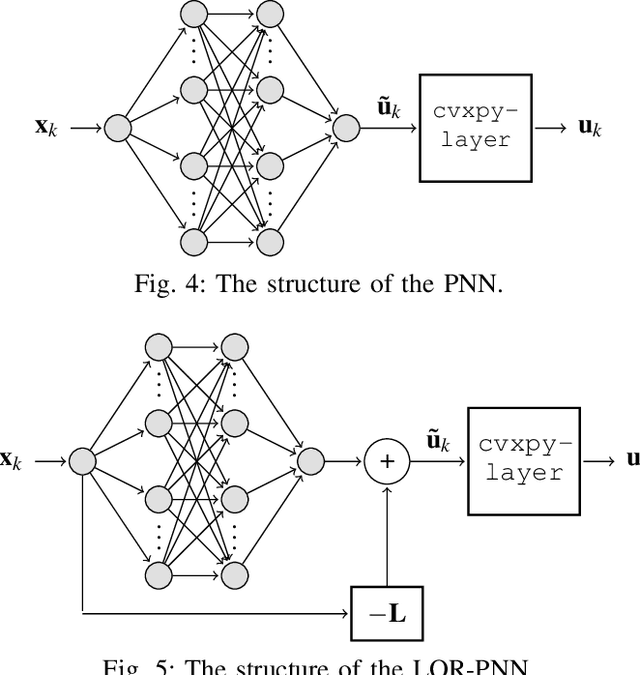
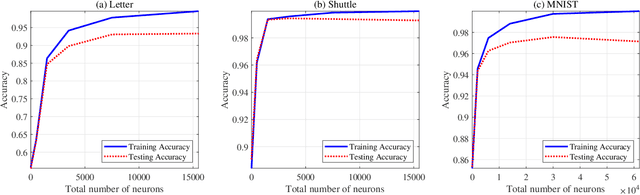
The contribution of this paper is a framework for training and evaluation of Model Predictive Control (MPC) implemented using constrained neural networks. Recent studies have proposed to use neural networks with differentiable convex optimization layers to implement model predictive controllers. The motivation is to replace real-time optimization in safety critical feedback control systems with learnt mappings in the form of neural networks with optimization layers. Such mappings take as the input the state vector and predict the control law as the output. The learning takes place using training data generated from off-line MPC simulations. However, a general framework for characterization of learning approaches in terms of both model validation and efficient training data generation is lacking in literature. In this paper, we take the first steps towards developing such a coherent framework. We discuss how the learning problem has similarities with system identification, in particular input design, model structure selection and model validation. We consider the study of neural network architectures in PyTorch with the explicit MPC constraints implemented as a differentiable optimization layer using CVXPY. We propose an efficient approach of generating MPC input samples subject to the MPC model constraints using a hit-and-run sampler. The corresponding true outputs are generated by solving the MPC offline using OSOP. We propose different metrics to validate the resulting approaches. Our study further aims to explore the advantages of incorporating domain knowledge into the network structure from a training and evaluation perspective. Different model structures are numerically tested using the proposed framework in order to obtain more insights in the properties of constrained neural networks based MPC.
High-dimensional Neural Feature using Rectified Linear Unit and Random Matrix Instance
Mar 29, 2020
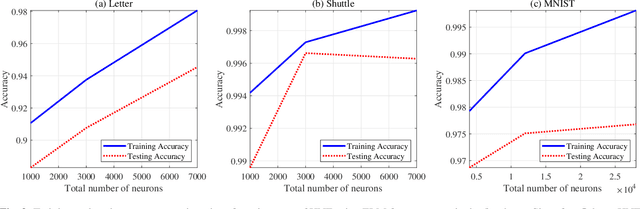
We design a ReLU-based multilayer neural network to generate a rich high-dimensional feature vector. The feature guarantees a monotonically decreasing training cost as the number of layers increases. We design the weight matrix in each layer to extend the feature vectors to a higher dimensional space while providing a richer representation in the sense of training cost. Linear projection to the target in the higher dimensional space leads to a lower training cost if a convex cost is minimized. An $\ell_2$-norm convex constraint is used in the minimization to improve the generalization error and avoid overfitting. The regularization hyperparameters of the network are derived analytically to guarantee a monotonic decrement of the training cost and therefore, it eliminates the need for cross-validation to find the regularization hyperparameter in each layer.