 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-similarity Aware Meta-learning through Nonparametric Kernel Regression
Paper and Code
Jun 12, 2020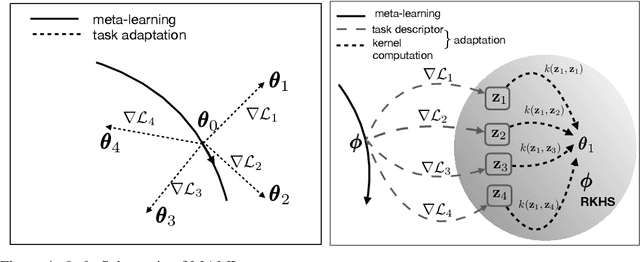
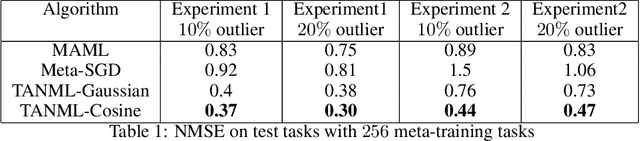
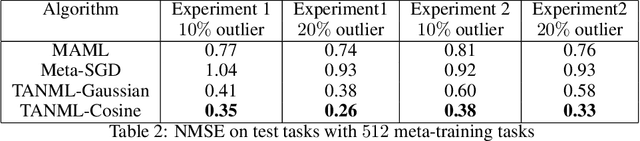
Meta-learning refers to the process of abstracting a learning rule for a class of tasks through a meta-parameter that captures the inductive bias for the class. The metaparameter is used to achieve a fast adaptation to unseen tasks from the class, given a few training samples. While meta-learning implicitly assumes the tasks as being similar, it is generally unclear how this similarity could be quantified. Further, many of the popular meta-learning approaches do not actively use such a task-similarity in solving for the tasks. In this paper, we propose the task-similarity aware nonparameteric meta-learning algorithm that explicitly employs similarity/dissimilarity between tasks using nonparametric kernel regression. Our approach models the task-specific parameters to lie in a reproducing kernel Hilbert space, wherein the kernel function captures the similarity across tasks. The proposed algorithm iteratively learns a meta-parameter which is used to assign a task-specific descriptor for every task. The task descriptors are then used to quantify the similarity through the kernel function. We show how our approach generalizes the popular meta-learning approaches of model-agnostic meta-learning (MAML) and Meta-stochastic gradient descent (Meta-SGD) approaches. Numerical experiments with regression tasks show that our algorithm performs well even in the presence of outlier or dissimilar tasks, validating the proposed approach