 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Sample Quality of Diffusion Models Using Self-Attention Guidance
Paper and Code
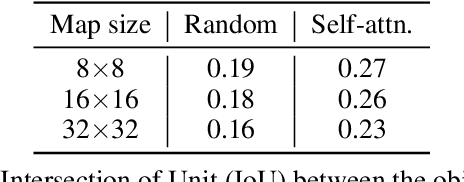
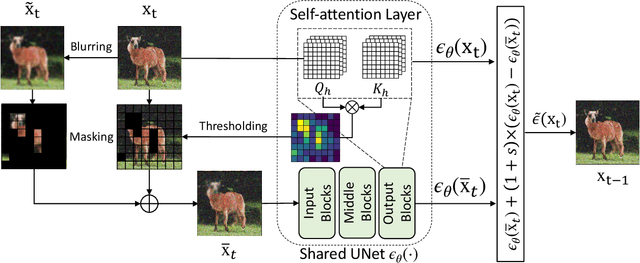
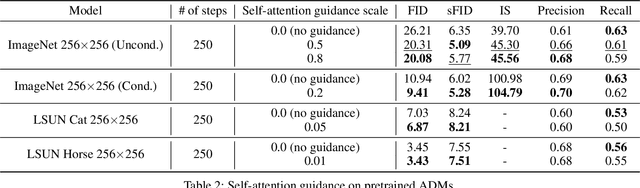

Following generative adversarial networks (GANs), a de facto standard model for image generation, denoising diffusion models (DDMs) have been actively researched and attracted strong attention due to their capability to generate images with high quality and diversity. However, the way the internal self-attention mechanism works inside the UNet of DDMs is under-explored. To unveil them, in this paper, we first investigate the self-attention operations within the black-boxed diffusion models and build hypotheses. Next, we verify the hypotheses about the self-attention map by conducting frequency analysis and testing the relationships with the generated objects. In consequence, we find out that the attention map is closely related to the quality of generated images. On the other hand, diffusion guidance methods based on additional information such as labels are proposed to improve the quality of generated images. Inspired by these methods, we present label-free guidance based on the intermediate self-attention map that can guide existing pretrained diffusion models to generate images with higher fidelity. In addition to the enhanced sample quality when used alone, we show that the results are further improved by combining our method with classifier guidance on ImageNet 128x128.