 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIDMs: Matching Interleaved Diffusion Models for Exemplar-based Image Translation
Paper and Code
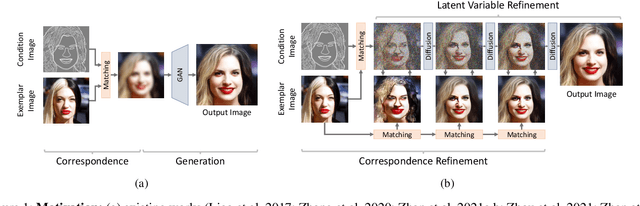
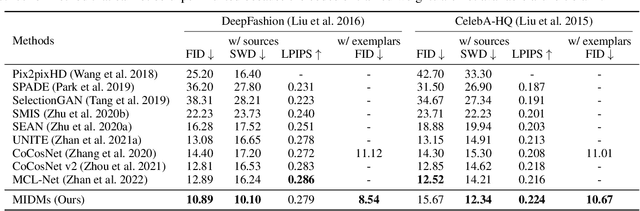
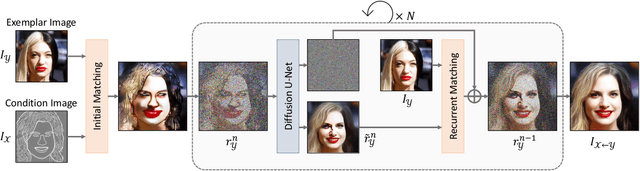
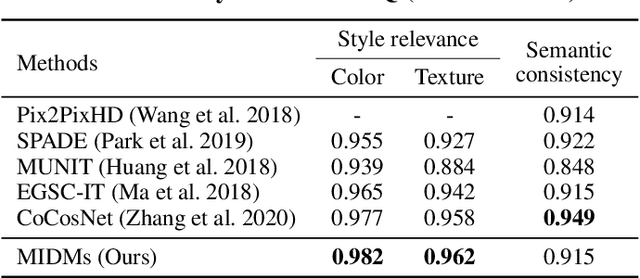
We present a novel method for exemplar-based image translation, called matching interleaved diffusion models (MIDMs). Most existing methods for this task were formulated as GAN-based matching-then-generation framework. However, in this framework, matching errors induced by the difficulty of semantic matching across cross-domain, e.g., sketch and photo, can be easily propagated to the generation step, which in turn leads to degenerated results. Motivated by the recent success of diffusion models overcoming the shortcomings of GANs, we incorporate the diffusion models to overcome these limitations. Specifically, we formulate a diffusion-based matching-and-generation framework that interleaves cross-domain matching and diffusion steps in the latent space by iteratively feeding the intermediate warp into the noising process and denoising it to generate a translated image. In addition, to improve the reliability of the diffusion process, we design a confidence-aware process using cycle-consistency to consider only confident regions during translation. Experimental results show that our MIDMs generate more plausible images than state-of-the-art methods.