 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentre Stage: Centricity-based Audio-Visual Temporal Action Detection
Nov 28, 2023Previous one-stage action detection approaches have modelled temporal dependencies using only the visual modality. In this paper, we explore different strategies to incorporate the audio modality, using multi-scale cross-attention to fuse the two modalities. We also demonstrate the correlation between the distance from the timestep to the action centre and the accuracy of the predicted boundaries. Thus, we propose a novel network head to estimate the closeness of timesteps to the action centre, which we call the centricity score. This leads to increased confidence for proposals that exhibit more precise boundaries. Our method can be integrated with other one-stage anchor-free architectures and we demonstrate this on three recent baselines on the EPIC-Kitchens-100 action detection benchmark where we achieve state-of-the-art performance. Detailed ablation studies showcase the benefits of fusing audio and our proposed centricity scores. Code and models for our proposed method are publicly available at https://github.com/hanielwang/Audio-Visual-TAD.git
Refining Action Boundaries for One-stage Detection
Oct 25, 2022Current one-stage action detection methods, which simultaneously predict action boundaries and the corresponding class, do not estimate or use a measure of confidence in their boundary predictions, which can lead to inaccurate boundaries. We incorporate the estimation of boundary confidence into one-stage anchor-free detection, through an additional prediction head that predicts the refined boundaries with higher confidence. We obtain state-of-the-art performance on the challenging EPIC-KITCHENS-100 action detection as well as the standard THUMOS14 action detection benchmarks, and achieve improvement on the ActivityNet-1.3 benchmark.
TVNet: Temporal Voting Network for Action Localization
Jan 02, 2022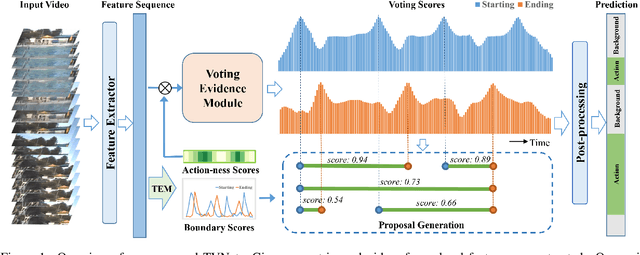
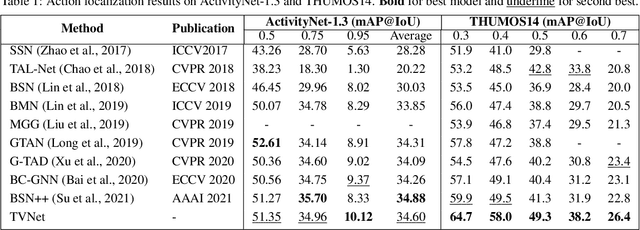
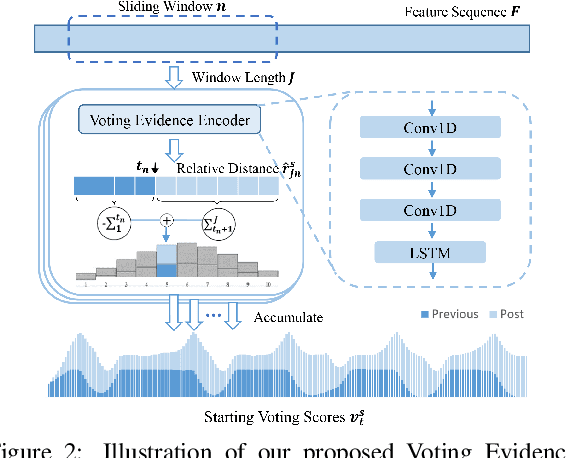
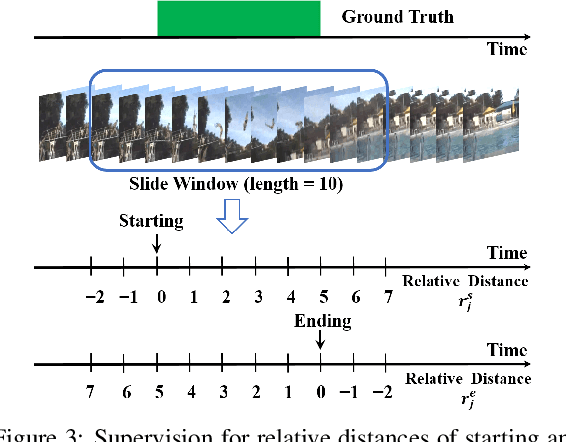
We propose a Temporal Voting Network (TVNet) for action localization in untrimmed videos. This incorporates a novel Voting Evidence Module to locate temporal boundaries, more accurately, where temporal contextual evidence is accumulated to predict frame-level probabilities of start and end action boundaries. Our action-independent evidence module is incorporated within a pipeline to calculate confidence scores and action classes. We achieve an average mAP of 34.6% on ActivityNet-1.3, particularly outperforming previous methods with the highest IoU of 0.95. TVNet also achieves mAP of 56.0% when combined with PGCN and 59.1% with MUSES at 0.5 IoU on THUMOS14 and outperforms prior work at all thresholds. Our code is available at https://github.com/hanielwang/TVNet.