 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnweaveNet: Unweaving Activity Stories
Dec 19, 2021
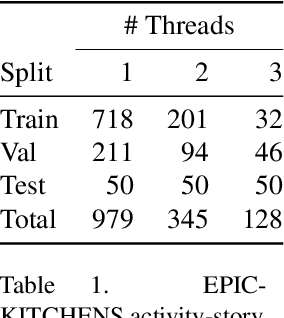
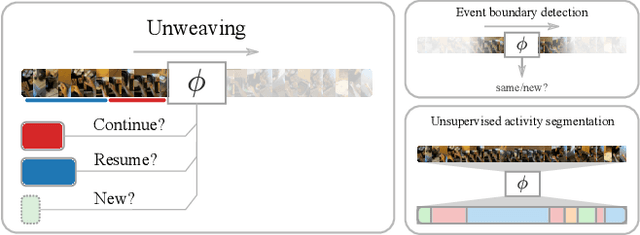
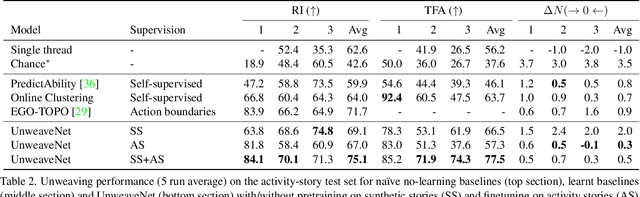
Our lives can be seen as a complex weaving of activities; we switch from one activity to another, to maximise our achievements or in reaction to demands placed upon us. Observing a video of unscripted daily activities, we parse the video into its constituent activity threads through a process we call unweaving. To accomplish this, we introduce a video representation explicitly capturing activity threads called a thread bank, along with a neural controller capable of detecting goal changes and resuming of past activities, together forming UnweaveNet. We train and evaluate UnweaveNet on sequences from the unscripted egocentric dataset EPIC-KITCHENS. We propose and showcase the efficacy of pretraining UnweaveNet in a self-supervised manner.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021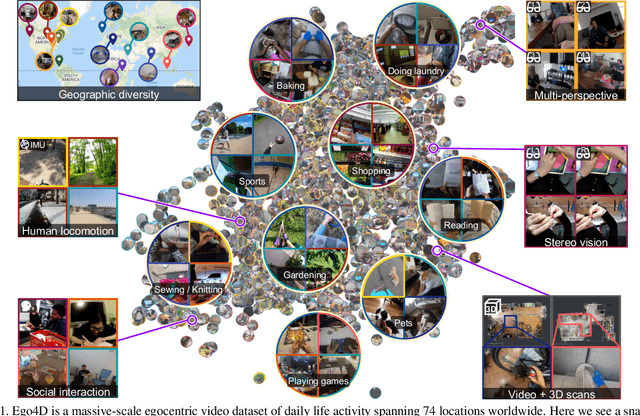
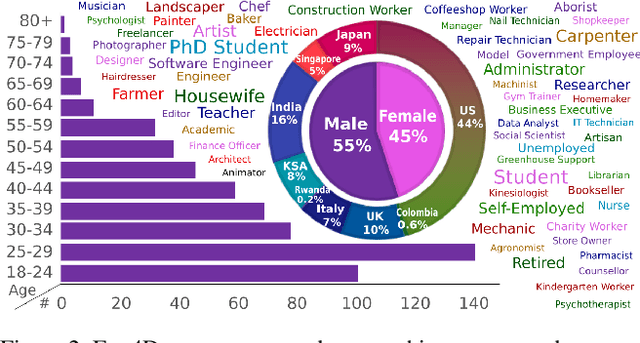

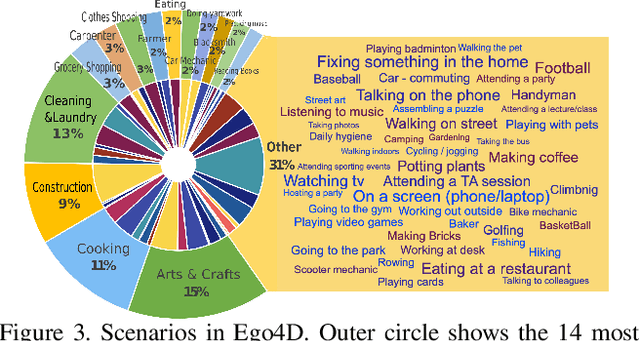
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Play Fair: Frame Attributions in Video Models
Nov 24, 2020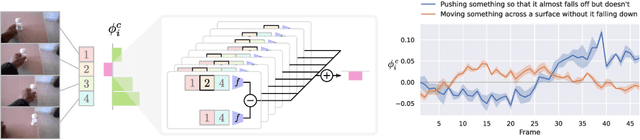


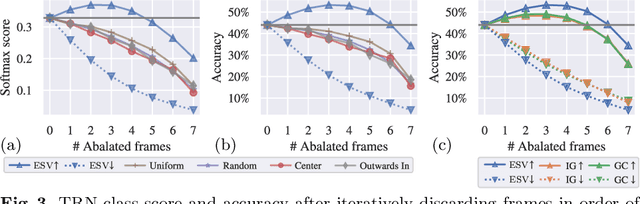
In this paper, we introduce an attribution method for explaining action recognition models. Such models fuse information from multiple frames within a video, through score aggregation or relational reasoning. We break down a model's class score into the sum of contributions from each frame, fairly. Our method adapts an axiomatic solution to fair reward distribution in cooperative games, known as the Shapley value, for elements in a variable-length sequence, which we call the Element Shapley Value (ESV). Critically, we propose a tractable approximation of ESV that scales linearly with the number of frames in the sequence. We employ ESV to explain two action recognition models (TRN and TSN) on the fine-grained dataset Something-Something. We offer detailed analysis of supporting/distracting frames, and the relationships of ESVs to the frame's position, class prediction, and sequence length. We compare ESV to naive baselines and two commonly used feature attribution methods: Grad-CAM and Integrated-Gradients.
Rescaling Egocentric Vision
Jun 23, 2020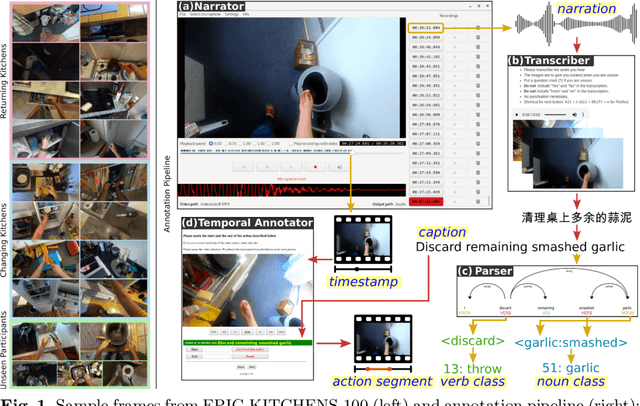
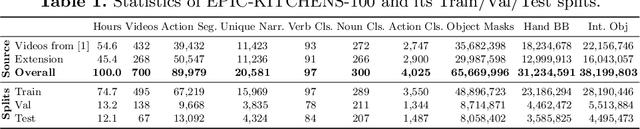
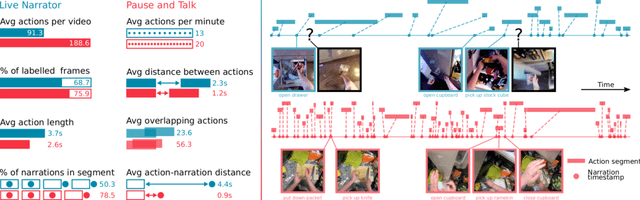
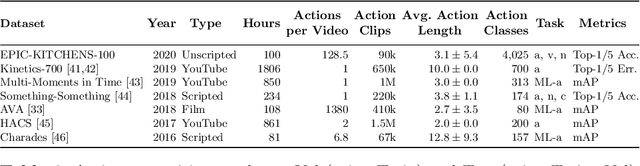
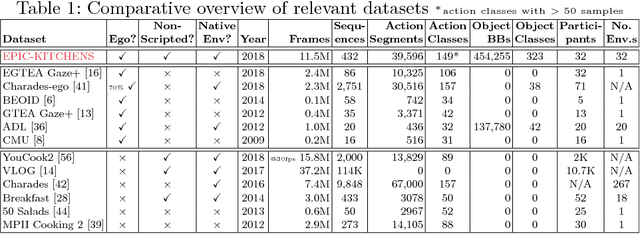
This paper introduces EPIC-KITCHENS-100, the largest annotated egocentric dataset - 100 hrs, 20M frames, 90K actions - of wearable videos capturing long-term unscripted activities in 45 environments. This extends our previous dataset (EPIC-KITCHENS-55), released in 2018, resulting in more action segments (+128%), environments (+41%) and hours (+84%), using a novel annotation pipeline that allows denser and more complete annotations of fine-grained actions (54% more actions per minute). We evaluate the "test of time" - i.e. whether models trained on data collected in 2018 can generalise to new footage collected under the same hypotheses albeit "two years on". The dataset is aligned with 6 challenges: action recognition (full and weak supervision), detection, anticipation, retrieval (from captions), as well as unsupervised domain adaptation for action recognition. For each challenge, we define the task, provide baselines and evaluation metrics. Our dataset and challenge leaderboards will be made publicly available.
The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines
Apr 29, 2020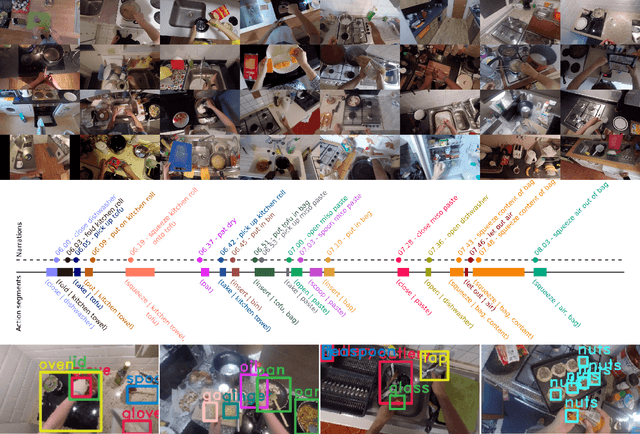
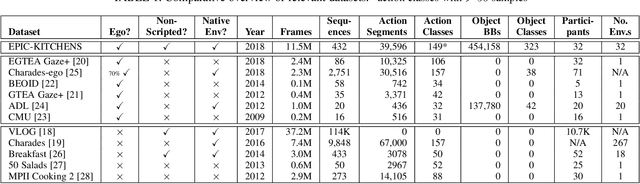

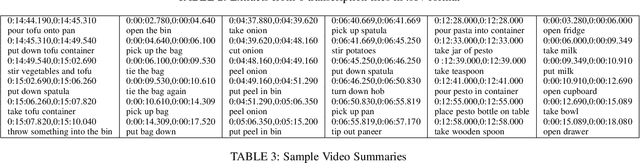
Since its introduction in 2018, EPIC-KITCHENS has attracted attention as the largest egocentric video benchmark, offering a unique viewpoint on people's interaction with objects, their attention, and even intention. In this paper, we detail how this large-scale dataset was captured by 32 participants in their native kitchen environments, and densely annotated with actions and object interactions. Our videos depict nonscripted daily activities, as recording is started every time a participant entered their kitchen. Recording took place in 4 countries by participants belonging to 10 different nationalities, resulting in highly diverse kitchen habits and cooking styles. Our dataset features 55 hours of video consisting of 11.5M frames, which we densely labelled for a total of 39.6K action segments and 454.2K object bounding boxes. Our annotation is unique in that we had the participants narrate their own videos after recording, thus reflecting true intention, and we crowd-sourced ground-truths based on these. We describe our object, action and. anticipation challenges, and evaluate several baselines over two test splits, seen and unseen kitchens. We introduce new baselines that highlight the multimodal nature of the dataset and the importance of explicit temporal modelling to discriminate fine-grained actions e.g. 'closing a tap' from 'opening' it up.
Retro-Actions: Learning 'Close' by Time-Reversing 'Open' Videos
Sep 20, 2019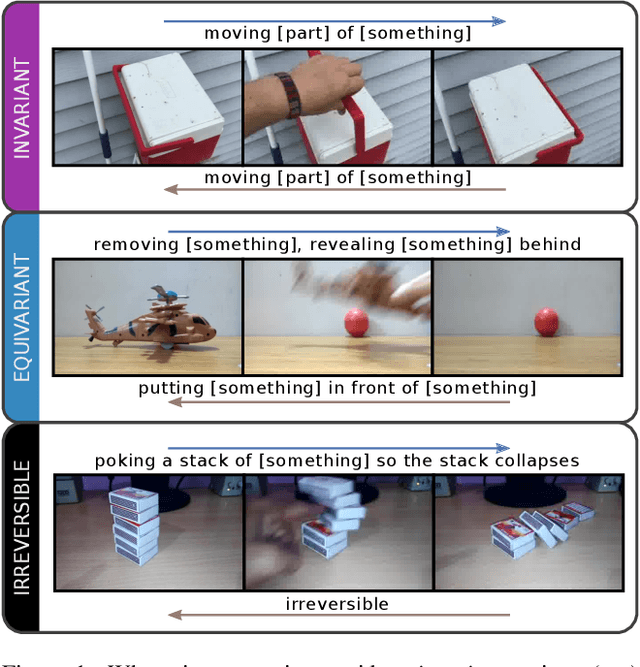
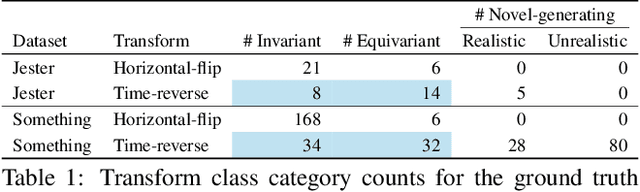

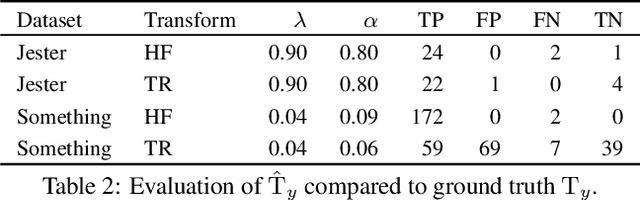
We investigate video transforms that result in class-homogeneous label-transforms. These are video transforms that consistently maintain or modify the labels of all videos in each class. We propose a general approach to discover invariant classes, whose transformed examples maintain their label; pairs of equivariant classes, whose transformed examples exchange their labels; and novel-generating classes, whose transformed examples belong to a new class outside the dataset. Label transforms offer additional supervision previously unexplored in video recognition benefiting data augmentation and enabling zero-shot learning opportunities by learning a class from transformed videos of its counterpart. Amongst such video transforms, we study horizontal-flipping, time-reversal, and their composition. We highlight errors in naively using horizontal-flipping as a form of data augmentation in video. Next, we validate the realism of time-reversed videos through a human perception study where people exhibit equal preference for forward and time-reversed videos. Finally, we test our approach on two datasets, Jester and Something-Something, evaluating the three video transforms for zero-shot learning and data augmentation. Our results show that gestures such as zooming in can be learnt from zooming out in a zero-shot setting, as well as more complex actions with state transitions such as digging something out of something from burying something in something.
An Evaluation of Action Recognition Models on EPIC-Kitchens
Aug 02, 2019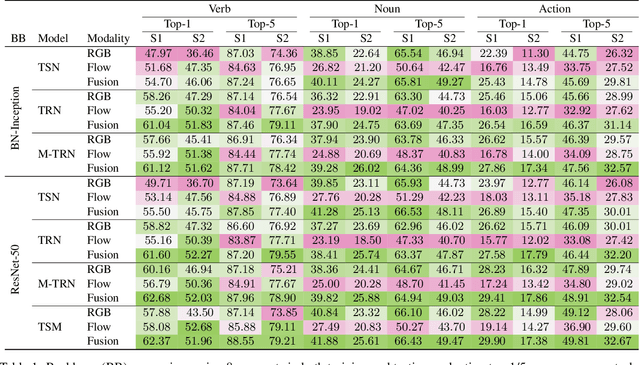
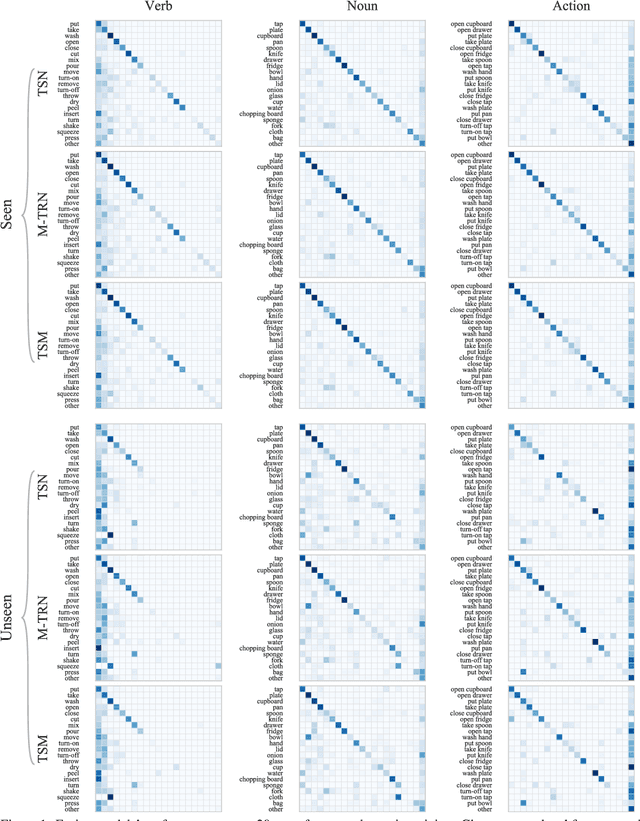
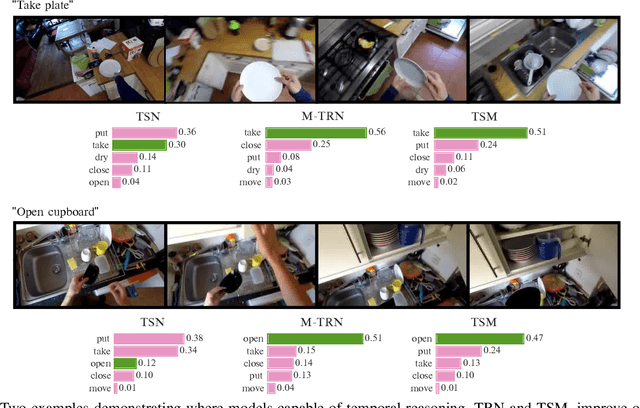
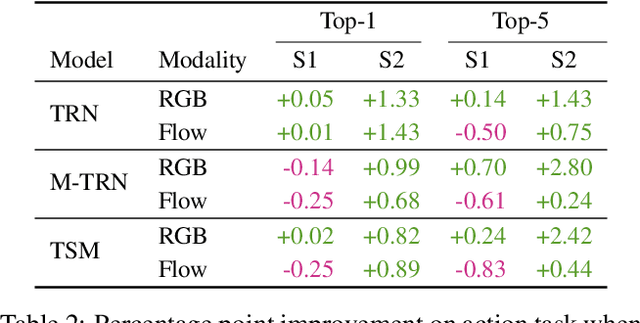
We benchmark contemporary action recognition models (TSN, TRN, and TSM) on the recently introduced EPIC-Kitchens dataset and release pretrained models on GitHub (https://github.com/epic-kitchens/action-models) for others to build upon. In contrast to popular action recognition datasets like Kinetics, Something-Something, UCF101, and HMDB51, EPIC-Kitchens is shot from an egocentric perspective and captures daily actions in-situ. In this report, we aim to understand how well these models can tackle the challenges present in this dataset, such as its long tail class distribution, unseen environment test set, and multiple tasks (verb, noun and, action classification). We discuss the models' shortcomings and avenues for future research.
Scaling Egocentric Vision: The EPIC-KITCHENS Dataset
Jul 31, 2018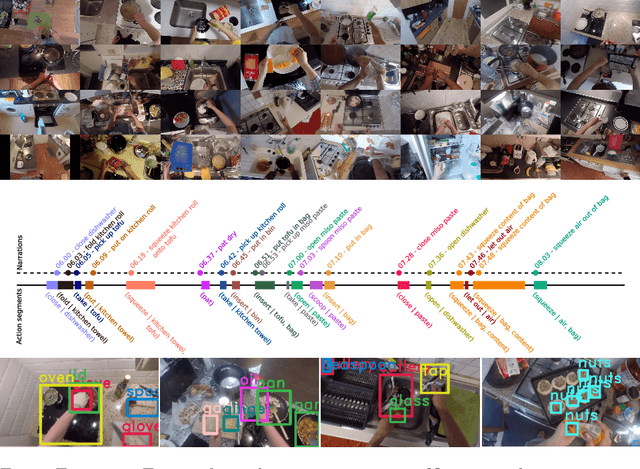


First-person vision is gaining interest as it offers a unique viewpoint on people's interaction with objects, their attention, and even intention. However, progress in this challenging domain has been relatively slow due to the lack of sufficiently large datasets. In this paper, we introduce EPIC-KITCHENS, a large-scale egocentric video benchmark recorded by 32 participants in their native kitchen environments. Our videos depict nonscripted daily activities: we simply asked each participant to start recording every time they entered their kitchen. Recording took place in 4 cities (in North America and Europe) by participants belonging to 10 different nationalities, resulting in highly diverse cooking styles. Our dataset features 55 hours of video consisting of 11.5M frames, which we densely labeled for a total of 39.6K action segments and 454.3K object bounding boxes. Our annotation is unique in that we had the participants narrate their own videos (after recording), thus reflecting true intention, and we crowd-sourced ground-truths based on these. We describe our object, action and anticipation challenges, and evaluate several baselines over two test splits, seen and unseen kitchens. Dataset and Project page: http://epic-kitchens.github.io